有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
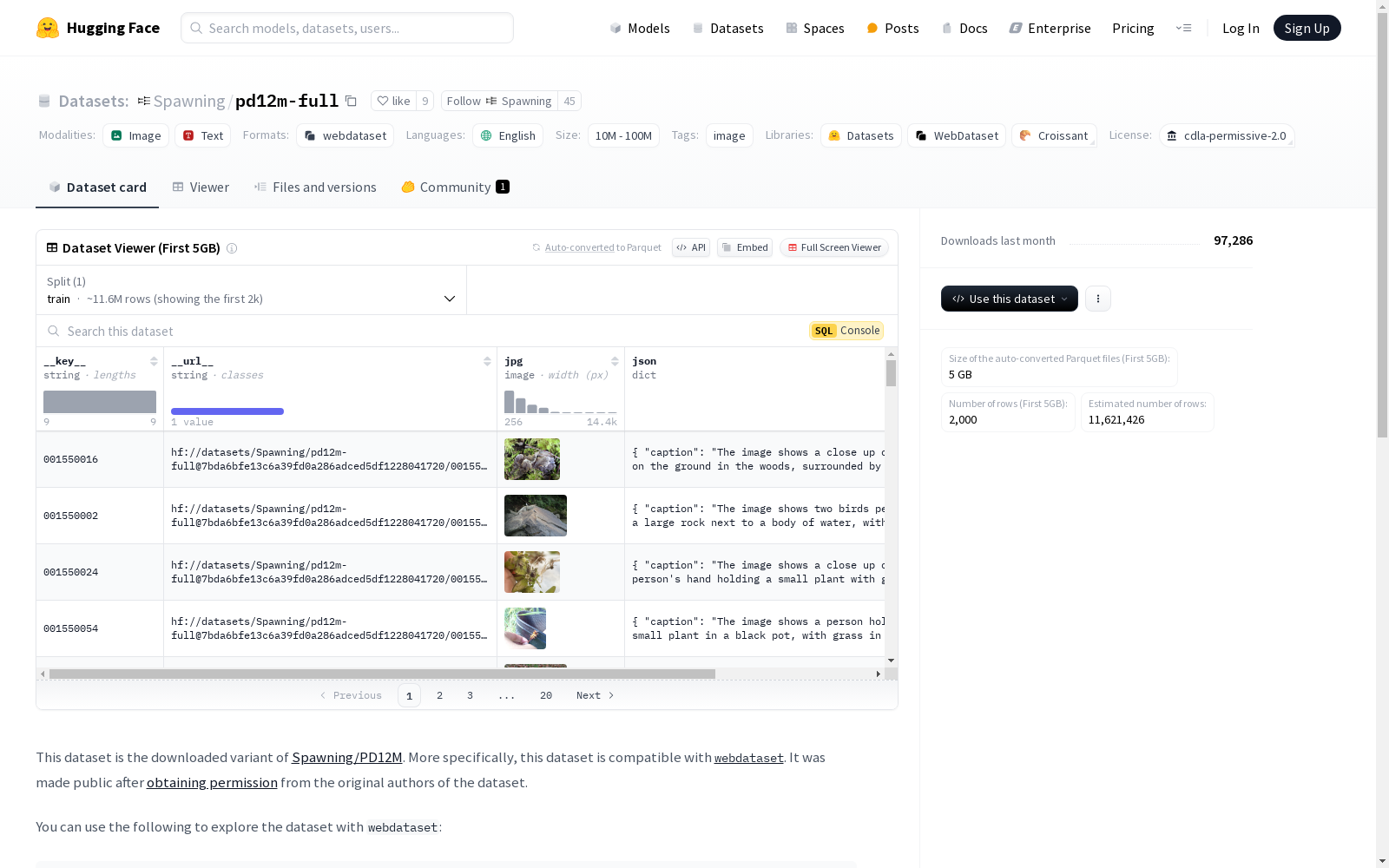
这个数据集如何下载?
webdataset。python import webdataset as wds
dataset_path = "pipe:curl -s -f -L https://huggingface.co/datasets/sayakpaul/pd12m-full/resolve/main/{00155..02480}.tar"
dataset = ( wds.WebDataset(dataset_path, handler=wds.warn_and_continue) .shuffle(690, handler=wds.warn_and_continue) .decode("pil", handler=wds.warn_and_continue) )
for sample in dataset: print(sample.keys()) print(sample["jpg"].size) print(sample["json"]) print(sample["txt"]) break
使用 img2dataset 工具进行下载。
下载命令如下: bash img2dataset --url_list pd12m_full.parquet --input_format "parquet" --url_col "url" --caption_col "caption" --output_format webdataset --number_sample_per_shard=5000 --skip_reencode=True --output_folder s3://diffusion-datasets/pd12m --processes_count 16 --thread_count 64 --resize_mode no --enable_wandb True
下载的 webdataset 分片被序列化到 S3 存储桶。
pd12m_full.parquet 是通过合并 metadata 中的所有 parquet 文件到一个 pandas 数据框中生成的,文件位于 original_parquet/pd12m_full.parquet。
使用以下脚本将文件从 S3 存储桶复制到当前仓库: python from huggingface_hub import create_repo, upload_file, dataset_info import ray import os
_temp_dir path accordingly.ray.init(num_cpus=16, _temp_dir="/scratch")
def main(): s3_fs = s3fs.S3FileSystem()
bucket_path = "s3://diffusion-datasets/pd12m"
files = s3_fs.ls(bucket_path, detail=True)
files = sorted([f["name"] for f in files if f["name"].endswith(".tar") and f["size"] > 0.0])
@ray.remote
def fn(tar_file):
# Change the paths accordingly.
full_s3_tar_file = f"s3://{tar_file}"
local_path = f"/scratch/{tar_file}"
s3_fs.download(full_s3_tar_file, local_path)
# Adjust according to what your local storage allows for.
batch_size = 20
for i in range(0, len(files), batch_size):
batch = files[i : i + batch_size]
futures = [fn.remote(tar_file) for tar_file in batch]
ray.get(futures)
os.system(
"huggingface-cli upload-large-folder sayakpaul/pd12m-full --repo-type=dataset /scratch/diffusion-datasets/pd12m --num-workers=16"
)
os.system(f"rm -rf /scratch/diffusion-datasets/pd12m/*.tar")
print("All shards have been downloaded successfully.")
if name == "main": create_repo(repo_id="sayakpaul/pd12m-full", repo_type="dataset", private=True, exist_ok=True) main()
中国空气质量数据集(2014-2020年)
数据集中的空气质量数据类型包括PM2.5, PM10, SO2, NO2, O3, CO, AQI,包含了2014-2020年全国360个城市的逐日空气质量监测数据。监测数据来自中国环境监测总站的全国城市空气质量实时发布平台,每日更新。数据集的原始文件为CSV的文本记录,通过空间化处理生产出Shape格式的空间数据。数据集包括CSV格式和Shape格式两数数据格式。
国家地球系统科学数据中心 收录
中国1km分辨率逐月降水量数据集(1901-2023)
该数据集为中国逐月降水量数据,空间分辨率为0.0083333°(约1km),时间为1901.1-2023.12。数据格式为NETCDF,即.nc格式。该数据集是根据CRU发布的全球0.5°气候数据集以及WorldClim发布的全球高分辨率气候数据集,通过Delta空间降尺度方案在中国降尺度生成的。并且,使用496个独立气象观测点数据进行验证,验证结果可信。本数据集包含的地理空间范围是全国主要陆地(包含港澳台地区),不含南海岛礁等区域。为了便于存储,数据均为int16型存于nc文件中,降水单位为0.1mm。 nc数据可使用ArcMAP软件打开制图; 并可用Matlab软件进行提取处理,Matlab发布了读入与存储nc文件的函数,读取函数为ncread,切换到nc文件存储文件夹,语句表达为:ncread (‘XXX.nc’,‘var’, [i j t],[leni lenj lent]),其中XXX.nc为文件名,为字符串需要’’;var是从XXX.nc中读取的变量名,为字符串需要’’;i、j、t分别为读取数据的起始行、列、时间,leni、lenj、lent i分别为在行、列、时间维度上读取的长度。这样,研究区内任何地区、任何时间段均可用此函数读取。Matlab的help里面有很多关于nc数据的命令,可查看。数据坐标系统建议使用WGS84。
国家青藏高原科学数据中心 收录
FMA (Free Music Archive)
免费音乐档案 (FMA) 是一个大型数据集,用于评估音乐信息检索中的多个任务。它包含 343 天的音频,来自 16,341 位艺术家的 106,574 首曲目和 14,854 张专辑,按 161 种流派的分级分类排列。它提供完整长度和高质量的音频、预先计算的功能,以及轨道和用户级元数据、标签和自由格式的文本,例如传记。作者定义了四个子集:Full:完整数据集,Large:音频限制为 30 秒的完整数据集 从轨道中间提取的剪辑(如果短于 30 秒,则为整个轨道),Medium:选择25,000 个具有单一根流派的 30 年代剪辑,小:一个平衡的子集,包含 8,000 个 30 年代剪辑,其中 8 种根流派中的每一个都有 1,000 个剪辑。官方分为训练集、验证集和测试集(80/10/10)使用分层抽样来保留每个流派的曲目百分比。同一艺术家的歌曲只是一组的一部分。资料来源:FMA:音乐分析数据集
OpenDataLab 收录
CHARLS
中国健康与养老追踪调查(CHARLS)数据集,旨在收集反映中国45岁及以上中老年人家庭和个人的高质量微观数据,用以分析人口老龄化问题,内容包括健康状况、经济状况、家庭结构和社会支持等。
charls.pku.edu.cn 收录
典型分布式光伏出力预测数据集
光伏电站出力数据每5分钟从电站机房监控系统获取;气象实测数据从气象站获取,气象站建于电站30号箱变附近,每5分钟将采集的数据通过光纤传输到机房;数值天气预报数据利用中国电科院新能源气象应用机房的WRF业务系统(包括30TF计算刀片机、250TB并行存储)进行中尺度模式计算后输出预报产品,每日8点前通过反向隔离装置推送到电站内网预测系统。
国家基础学科公共科学数据中心 收录