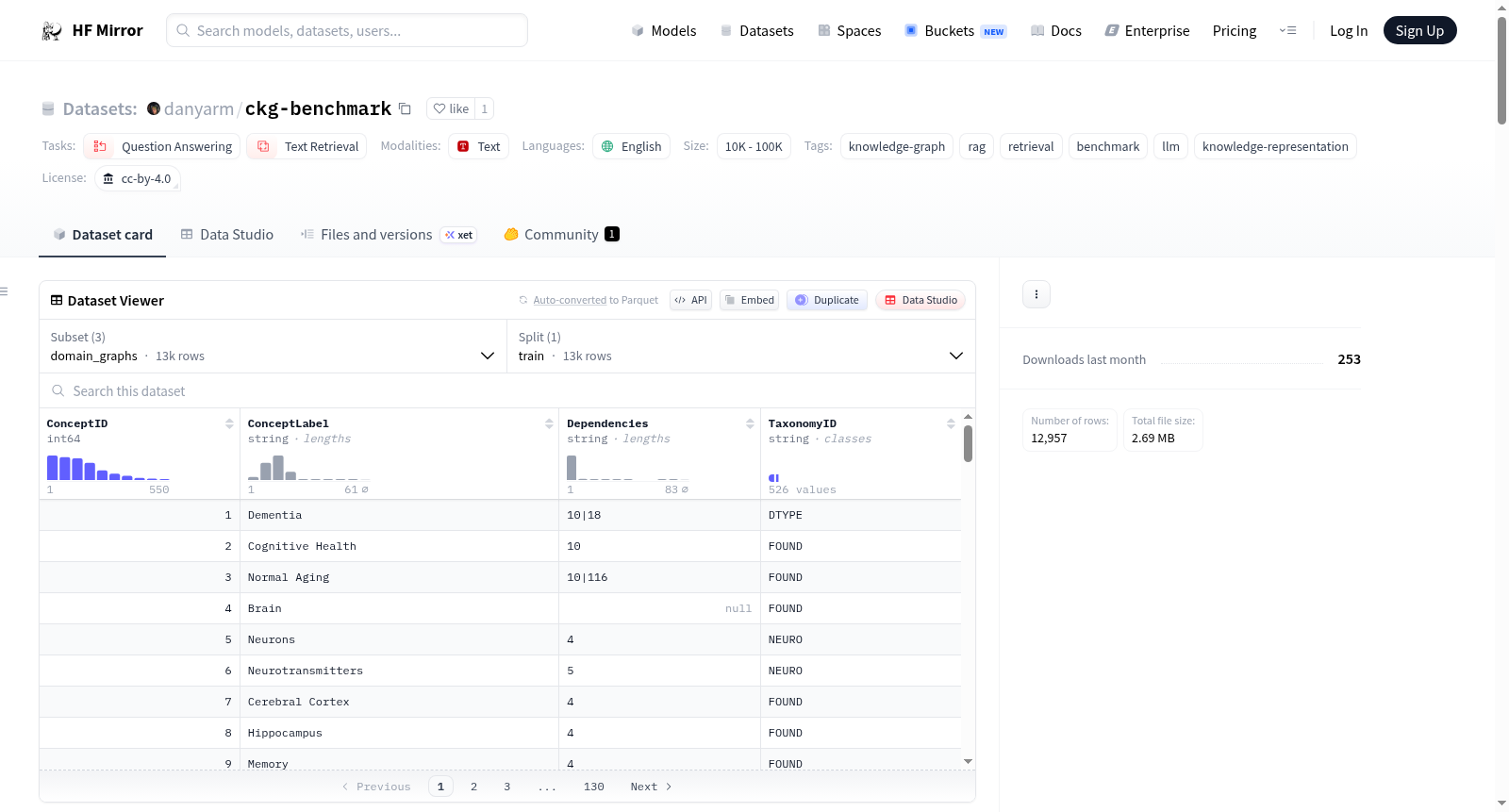
danyarm/ckg-benchmark
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/danyarm/ckg-benchmark
下载链接
链接失效反馈官方服务:
资源简介:
CKG Benchmark是一个用于知识检索架构基准测试的数据集,特别关注预结构化知识图在多个领域中的表现。数据集包含52个领域的结构化有向无环图(DAG)、7,928个基准查询以及每个系统的JSONL结果和摘要CSV。数据集强调了预结构化知识图在47个基准领域中的优越性,包括更高的F1分数和更低的令牌成本。此外,数据集还引入了新颖的度量标准,如检索密度分数(RDS)、跳深度F1和每正确答案成本(CPCA)。数据集内容涵盖教育和技术等多个领域,旨在为知识检索和表示提供全面的基准测试工具。
The CKG Benchmark is a dataset designed for benchmarking knowledge retrieval architectures, with a particular focus on the performance of pre-structured knowledge graphs across multiple domains. The dataset includes structured directed acyclic graphs (DAGs) for 52 domains, 7,928 benchmark queries, and JSONL results along with summary CSVs for each system. It highlights the superiority of pre-structured knowledge graphs in 47 benchmarked domains, demonstrating higher F1 scores and lower token costs. Additionally, the dataset introduces novel metrics such as Retrieval Density Score (RDS), Hop-Depth F1, and Cost Per Correct Answer (CPCA). Covering various fields including education and technology, the dataset serves as a comprehensive tool for benchmarking knowledge retrieval and representation.
提供机构:
danyarm
搜集汇总
数据集介绍
构建方式
CKG Benchmark 数据集以紧凑知识图谱(CKG)为核心,其构建方式独具匠心。该数据集采用双轨设计:第一轨基于 McCreary 智能教科书语料库,涵盖 44 个开源教育领域,通过人工精心编写学习图谱 CSV 文件,确保领域知识的准确性和结构化;第二轨则借助自动化流程生成商业领域数据,例如从 ClinicalTrials.gov API 中提取 GLP-1/肥胖症药理学知识,无需专家筛选即可在单次会话中完成构建。数据集包含 52 个领域图谱、7,928 条基准查询以及多系统的评估结果,每个领域以有向无环图(DAG)形式组织概念与依赖关系,形成层次清晰的知识结构。
使用方法
使用 CKG Benchmark 数据集时,可通过 Hugging Face Datasets 库加载三个核心配置:domain_graphs 提供领域图谱数据,queries 包含五种类型(T1 至 T5)的基准查询,results 则存储各系统的评估结果。用户可根据需求选择 47 个基准教育领域或 5 个企业领域进行实验,查询类型涵盖从实体查找、直接依赖到多跳路径与跨概念关系。该数据集特别适用于检索增强生成(RAG)架构的对比评估,开发者可通过提供的 MCP 服务器(pip install ckg-mcp)快速部署,并借助在线演示界面直观查看检索结果。推荐的评估方式包括计算宏 F1、RDS 及 CPCA(每正确答案成本),以全面衡量系统性能。
背景与挑战
背景概述
知识图谱作为一种结构化知识表示形式,在自然语言处理与检索增强生成领域中发挥着日益重要的作用。CKG Benchmark数据集由Daniel Yarmoluk与Dan McCreary于2026年创建,旨在系统性地评估不同检索架构在处理多跳推理查询时的性能表现。该数据集覆盖47个经过基准测试的教育领域及5个企业级领域,包含7,928条涵盖实体查询、直接依赖、多跳路径、类别聚合与跨概念关系五种类型的查询。实验结果表明,预结构化知识图谱在宏观F1分数上以0.4709远超RAG的0.1231,同时其每个查询的令牌消耗仅为269个,展现出42倍于RAG的每令牌智能密度。这一工作为知识表示与检索领域的实证研究提供了全新的评估框架与度量标准。
当前挑战
当前检索系统面临的挑战首先体现为多跳推理能力的不足:实验数据显示,随着跳数深度增加,RAG系统的F1分数在低水平上徘徊甚至下降,而CKG系统则从0.374稳步攀升至0.772,揭示了传统检索方法在捕捉长程语义依赖关系时的结构性瓶颈。其次,构建过程面临数据异质性与质量控制的难题,包括跨领域概念间的依赖关系标注一致性维护、从非结构化知识源自动化生成结构化图谱的精度保障,以及如何有效组合专家手工标注与流水线自动化构建两种范式,以确保知识图谱的完备性与可靠性。最后,高昂的令牌成本成为制约实际部署的关键因素,RAG系统以2,982个令牌换取0.1231的F1分数,其运行成本高达76.23美元,远高于CKG系统的7.81美元,凸显了在资源受限场景下实现高效与经济平衡的紧迫性。
常用场景
经典使用场景
在知识检索与问答系统评估领域,CKG Benchmark为衡量不同架构在结构化知识获取上的表现提供了标准化测试平台。该数据集涵盖47个教育领域与5个企业领域,包含7,928条涵盖实体查找、直接依赖、多跳路径、类别聚合与跨概念关系五类查询的基准测试用例。研究者可将手写学习图谱(Track 1)与流水线自动生成图谱(Track 2)作为检索源,通过对比紧凑知识图谱(CKG)与RAG、GraphRAG等主流方法在宏观F1分数、每查询令牌消耗及检索密度得分(RDS)等指标上的差异,系统评估知识表示与推理效率。这一基准设计使得跨领域、跨查询类型的公平比较成为可能。
解决学术问题
该数据集直面当前大语言模型知识检索中的核心矛盾:传统RAG虽灵活但常因上下文碎片化导致幻觉,且多跳推理能力随路径深度增加迅速衰减。CKG Benchmark通过引入预结构化有向无环图作为知识基底,证明其以极低令牌成本(每查询仅269个令牌)即可实现RAG近4倍的宏观F1性能,并在查询深度增加时展现持续提升的推理质量(5跳F1达0.772),而RAG则陷入性能平台期。这一发现挑战了‘更多上下文必然带来更好理解’的固有假设,为知识密集型问答场景提供了一种零幻觉、高性价比的替代方案,同时推动了检索密度得分(RDS)与单正确回答成本(CPCA)等新型评估指标的建立。
实际应用
CKG Benchmark所验证的紧凑知识图谱架构已在多个实际场景中落地应用。在教育领域,智能教科书系统利用手写学习图谱为学生提供精准的前提概念链导航,显著提升自适应学习路径规划的准确性。在商业领域,GLP-1/肥胖症药理图谱通过自动化从ClinicalTrials.gov构建而成,经基准测试验证其性能(F1=0.53)甚至超越人工精心编纂的领域均值,展示了在医药合规、药物相互作用分析等垂直行业快速部署的可能性。此外,该数据集衍生的MCP服务器已支持实时图谱查询,开发者可将其集成至企业知识管理系统,从而在临床药物编码、医疗账单审核等场景中实现低成本、高可靠的知识检索。
数据集最近研究
最新研究方向
当前,知识图谱与检索增强生成(RAG)的融合已成为提升大语言模型(LLM)事实准确性与推理能力的前沿方向。CKG Benchmark独辟蹊径,通过构建预结构化紧凑知识图谱(CKG),在47个横跨教育、医疗、工程等领域的数据集上系统对比了CKG、传统RAG与GraphRAG的性能。实验揭示了一个颠覆性发现:CKG以较RAG低11倍的Token消耗,实现了4倍的宏F1性能提升,且在多跳推理深度增加时,CKG的F1值持续攀升至0.772,而RAG则陷入停滞。这一结果深刻挑战了当前依赖稠密向量检索的主流范式,首次提出“智能密度”(RDS)这一评估指标——即单位Token所承载的推理效能,为构建高精度、低成本的LLM知识基础设施开辟了新路径。
以上内容由遇见数据集搜集并总结生成


