microsoft/MeetingBank-LLMCompressed
收藏Hugging Face2024-05-16 更新2024-05-25 收录
下载链接:
https://hf-mirror.com/datasets/microsoft/MeetingBank-LLMCompressed
下载链接
链接失效反馈官方服务:
资源简介:
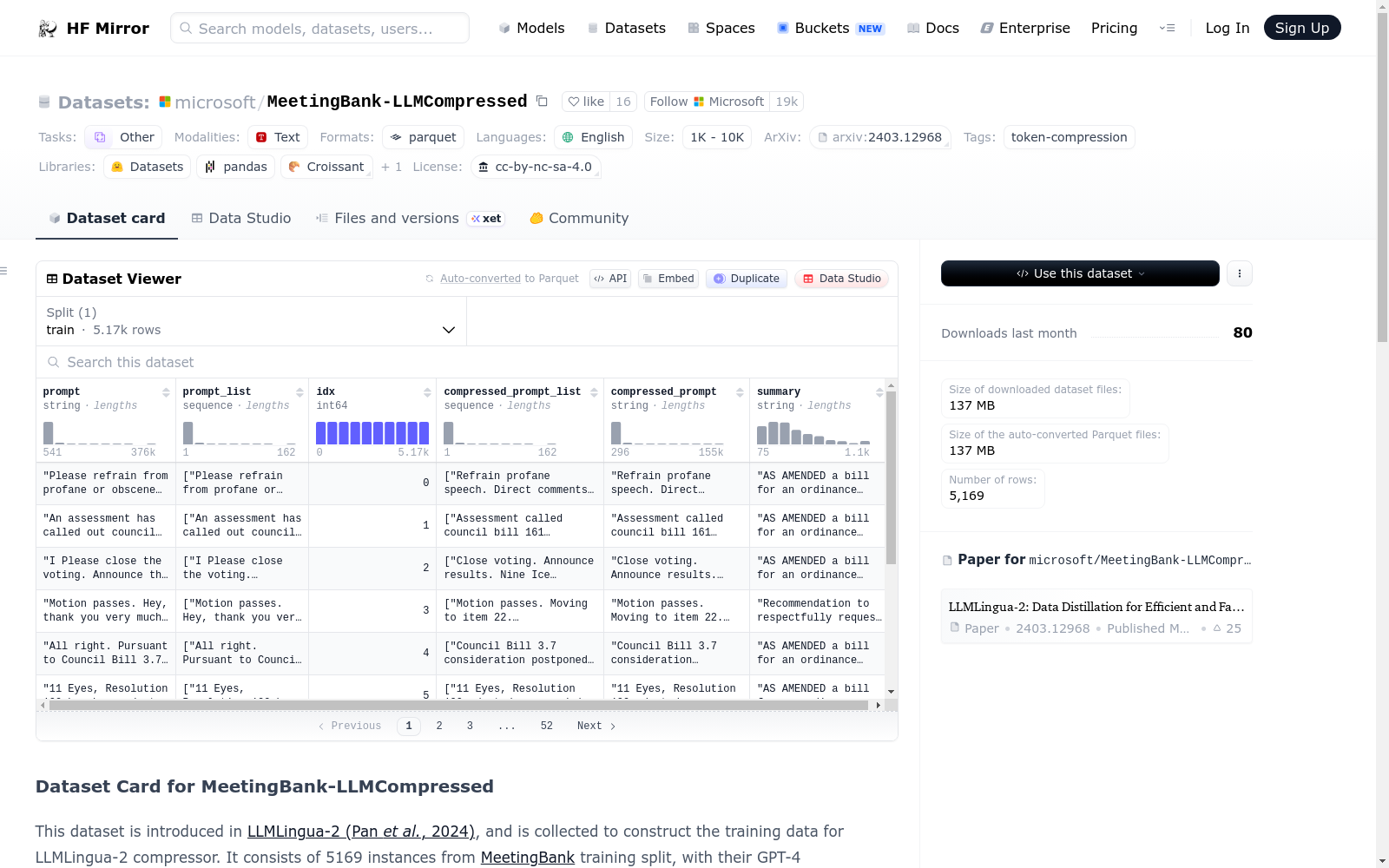
该数据集由Microsoft LLMLingua-2 Training Data组成,用于构建LLMLingua-2压缩器的训练数据。数据集包含5169个来自MeetingBank训练分割的实例,每个实例都有其GPT-4压缩版本。数据集的特征包括原始文本、压缩文本、文本块列表、压缩文本块列表、索引和会议摘要。
该数据集由Microsoft LLMLingua-2 Training Data组成,用于构建LLMLingua-2压缩器的训练数据。数据集包含5169个来自MeetingBank训练分割的实例,每个实例都有其GPT-4压缩版本。数据集的特征包括原始文本、压缩文本、文本块列表、压缩文本块列表、索引和会议摘要。
提供机构:
microsoft
原始信息汇总
数据集概述
数据集名称
Microsoft LLMLingua-2 Training Data
数据集描述
该数据集用于构建LLMLingua-2压缩器的训练数据,包含5169个来自MeetingBank训练分割的实例及其GPT-4压缩版本。
数据集特征
idx: 整数类型,实例的索引。prompt: 字符串类型,会议记录的原始文本。prompt_list: 字符串序列类型,对应于原始实例的文本块列表。compressed_prompt_list: 字符串序列类型,每个块独立压缩后的文本块列表。compressed_prompt: 字符串类型,会议记录的GPT-4压缩版本。summary: 字符串类型,会议记录的摘要。
数据集分割
train: 包含5169个实例,数据大小为246456074字节。
数据集大小
- 下载大小: 136743273字节
- 数据集大小: 246456074字节
语言
- 英语 (en)
数据集类别
- 大小类别: 100M<n<1B
- 任务类别: 其他
许可证
- cc-by-nc-sa-4.0
引用信息
bibtex @inproceedings{pan2024llmlingua2, title={LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression}, author={Zhuoshi Pan and Qianhui Wu and Huiqiang Jiang and Menglin Xia and Xufang Luo and Jue Zhang and Qingwei Lin and Victor Rühle and Yuqing Yang and Chin-Yew Lin and H. Vicky Zhao and Lili Qiu and Dongmei Zhang}, year={2024}, booktitle = {Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics}, publisher = {Association for Computational Linguistics} }
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含会议记录的原始文本及其GPT-4压缩版本,共5169个实例,用于训练LLMLingua-2压缩器。数据集提供了丰富的字段信息,包括原始文本、分块列表、压缩文本及分块列表、会议摘要等,适用于文本压缩和自然语言处理研究。
以上内容由遇见数据集搜集并总结生成


