Stable_Diffusion_3_Recaption
收藏Hugging Face2025-01-03 更新2025-01-04 收录
下载链接:
https://huggingface.co/datasets/gmongaras/Stable_Diffusion_3_Recaption
下载链接
链接失效反馈官方服务:
资源简介:
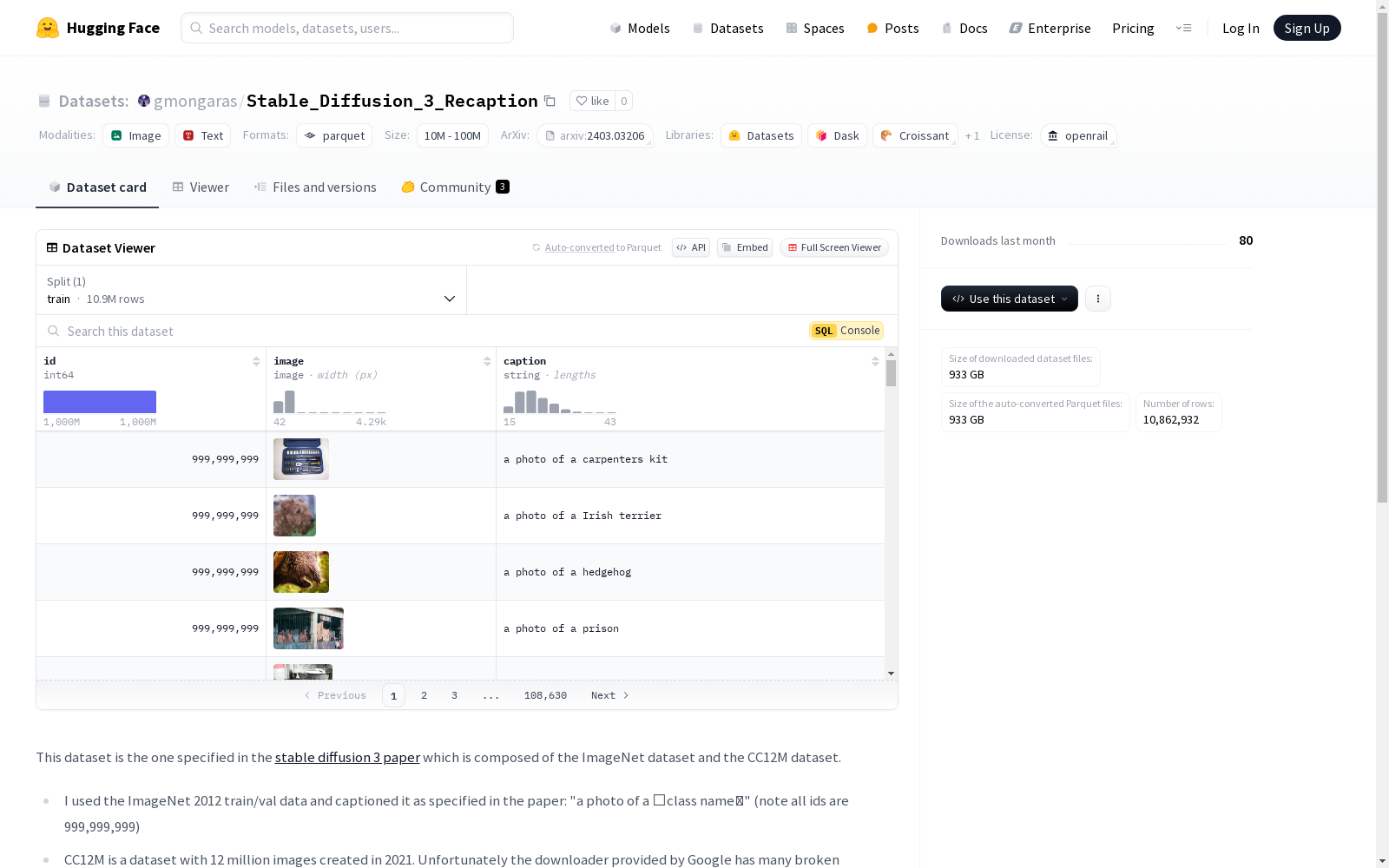
该数据集由ImageNet数据集和CC12M数据集组成,是稳定扩散3论文中指定的数据集。ImageNet 2012的训练/验证数据被按照论文中的描述进行了标注,即“a photo of a 〈class name〉”。CC12M是一个包含1200万张图片的数据集,但由于Google提供的下载器存在许多损坏的链接,下载过程非常耗时。社区中有人公开了这个数据集,最大的一个包含约1000万张图片的仓库被用于此数据集。为了提高图像生成的质量,该数据集的标注与另一个具有更好标注的数据集进行了合并。数据集包含id、image和caption三个列,其中id是CC12M图像的id或ImageNet的999,999,999,image是表示全分辨率图像的字节数据,caption是图像的llavanext标注。
This dataset consists of the ImageNet dataset and the CC12M dataset, as specified in the Stable Diffusion 3 paper. The training and validation data of ImageNet 2012 were annotated in accordance with the description in the paper, which is "a photo of a 〈class name〉". CC12M is a dataset containing 12 million images, but the downloading process is extremely time-consuming due to numerous broken links in the downloader provided by Google. Some community members have publicly released this dataset, and the largest repository with approximately 10 million images was used for this dataset. To improve the quality of image generation, the annotations of this dataset were merged with those of another dataset with better annotations. The dataset contains three columns: id, image, and caption. Specifically, id is either the image ID of CC12M or 999,999,999 for ImageNet; image refers to the byte data representing the full-resolution image; and caption refers to the LLaVA-Next annotations of the image.
创建时间:
2025-01-02
搜集汇总
数据集介绍
构建方式
Stable_Diffusion_3_Recaption数据集的构建基于ImageNet 2012训练/验证数据和CC12M数据集。ImageNet数据通过统一格式的标题进行标注,格式为“a photo of a 〈class name〉”,而CC12M数据集则通过社区公开的资源进行整合。由于CC12M原始下载链接存在大量失效问题,数据集构建者采用了社区中公开的高分辨率图像资源,并结合了LLaVA-ReCap-CC12M和CaptionEmporium/conceptual-captions-cc12m-llavanext两个数据集,以优化标题质量。
特点
该数据集包含10862932个样本,主要特征包括id、image和caption三列。id列用于标识图像来源,image列存储高分辨率的图像字节数据,caption列则提供了经过优化的图像标题。ImageNet数据以PNG格式存储,而CC12M数据则以JPEG格式存储,确保了图像的多样性和高质量。数据集的总大小约为934.58GB,适用于大规模图像生成和标题生成任务。
使用方法
使用Stable_Diffusion_3_Recaption数据集时,可以通过Python的PIL库解码图像字节数据。具体方法为使用`Image.open(io.BytesIO(row['image']))`,其中`row['image']`为图像字节数据。该数据集适用于训练和评估图像生成模型,特别是基于标题的生成任务。用户可以通过id列区分ImageNet和CC12M数据,并结合caption列进行模型训练或生成任务。
背景与挑战
背景概述
Stable_Diffusion_3_Recaption数据集是基于Stable Diffusion 3论文中提出的需求构建的,旨在为图像生成模型提供高质量的图像-文本对数据。该数据集整合了ImageNet 2012的训练/验证集和CC12M数据集,其中ImageNet数据集的图像被统一标注为“a photo of a 〈class name〉”,而CC12M数据集则提供了12百万张图像及其对应的自然语言描述。该数据集的构建由社区成员共同完成,主要研究人员和机构未明确提及,但其核心研究问题在于如何通过高质量的图像-文本对数据提升生成模型的性能。该数据集对图像生成领域的研究具有重要影响,特别是在提升生成模型的语义理解和生成质量方面。
当前挑战
Stable_Diffusion_3_Recaption数据集在构建过程中面临多重挑战。首先,CC12M数据集由于Google提供的下载工具存在大量失效链接,导致数据获取极为耗时且不完整。其次,CC12M的原始标注文本质量较低,难以直接用于图像生成任务,因此需要通过与其他高质量标注数据集(如LLaVA-ReCap-CC12M和Conceptual Captions)进行合并以提升标注质量。此外,数据集中包含两种不同格式的图像数据(JPEG和PNG),这增加了数据处理的复杂性。这些挑战不仅影响了数据集的构建效率,也对后续模型的训练和性能优化提出了更高的要求。
常用场景
经典使用场景
Stable_Diffusion_3_Recaption数据集在图像生成和自然语言处理领域具有广泛的应用。该数据集结合了ImageNet和CC12M数据集,提供了丰富的图像和对应的自然语言描述,特别适用于训练和评估图像生成模型,如Stable Diffusion 3。通过提供高质量的图像和描述,该数据集能够帮助研究人员更好地理解和生成与图像内容相关的文本描述。
实际应用
在实际应用中,Stable_Diffusion_3_Recaption数据集被广泛用于图像生成、图像标注和内容创作等领域。例如,在广告设计和社交媒体内容生成中,该数据集可以帮助生成与图像内容高度相关的文本描述,提升用户体验。此外,该数据集还可用于教育领域,帮助学生学习图像与文本的对应关系。
衍生相关工作
Stable_Diffusion_3_Recaption数据集衍生了许多相关的研究工作,特别是在图像生成和多模态学习领域。基于该数据集,研究人员开发了多种先进的图像生成模型,如Stable Diffusion 3,这些模型在图像质量和文本描述的准确性上取得了显著进展。此外,该数据集还促进了多模态学习算法的发展,推动了图像与文本联合建模的研究。
以上内容由遇见数据集搜集并总结生成


