food-visual-instructions
收藏Hugging Face2024-12-15 更新2024-12-16 收录
下载链接:
https://huggingface.co/datasets/AdaptLLM/food-visual-instructions
下载链接
链接失效反馈官方服务:
资源简介:
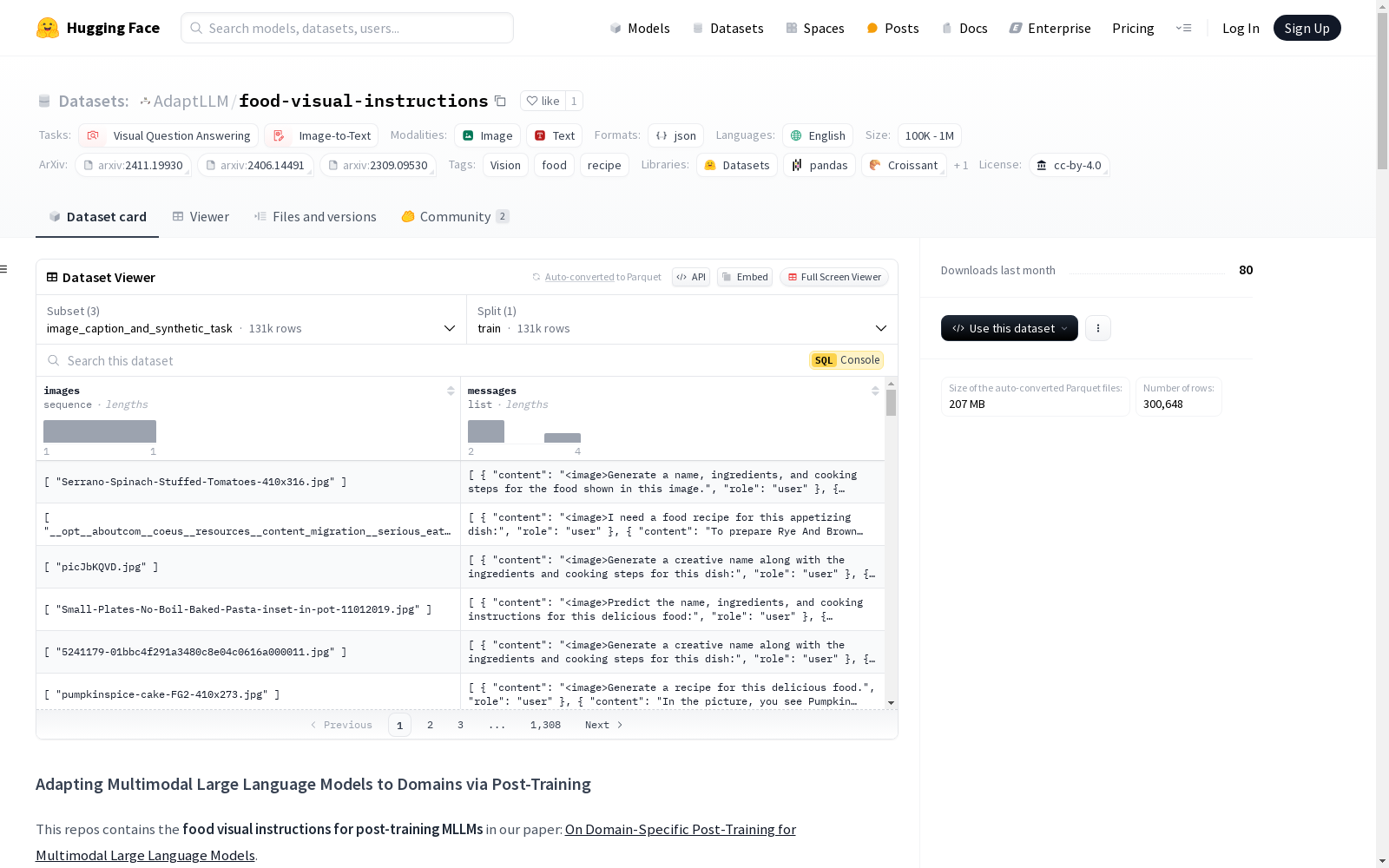
该数据集用于食品领域的多模态大语言模型(MLLMs)后训练,包含131K图像-标题对和39K合成视觉指令任务,基于扩展的Recipe1M+数据集生成。数据集通过单一阶段的训练流程来增强任务多样性,适用于视觉问答和图像到文本的任务。
创建时间:
2024-12-11
原始信息汇总
数据集概述
基本信息
- 许可证: CC BY 4.0
- 任务类别:
- 视觉问答
- 图像到文本
- 语言: 英语
- 标签: 视觉, 食物, 食谱
配置信息
- config_name: image_caption_and_synthetic_task
- data_files: image_caption_and_synthetic_task.json
- config_name: image_caption_pairs
- data_files: image_caption_pairs.json
- config_name: synthetic_visual_tasks
- data_files: synthetic_visual_tasks.json
数据集描述
- image_caption_pairs.json: 从扩展的Recipe1M+数据集中提取的单图像示例,包含131K图像-标题对。
- synthetic_visual_tasks.json: 基于上述图像-标题对生成的合成视觉任务,包含39K合成指令-响应对,经过一致性过滤。
- image_caption_and_synthetic_task.json: 用于重现单阶段领域特定后训练的数据集,包含图像标题任务和合成视觉指令任务,总计130K示例。
数据下载
- 文本数据:
- 使用
huggingface-cli download命令下载指定文件。
- 使用
- 图像数据:
- 使用
huggingface-cli download命令下载包含图像的zip文件,并解压缩。
- 使用
引用
- 如果使用该数据集,请引用相关论文。
搜集汇总
数据集介绍
构建方式
该数据集通过利用开源模型开发的视觉指令合成器,基于扩展的Recipe1M+数据集中的图像-标题对生成多样化的视觉指令任务。这些合成任务经过一致性过滤后,形成了包含39K指令-响应对的synthetic_visual_tasks.json文件。此外,从扩展的Recipe1M+数据集中提取的131K图像-标题对构成了image_caption_pairs.json文件。最终,image_caption_and_synthetic_task.json文件整合了图像标题任务和合成视觉指令任务,共计130K样本,用于单阶段领域特定后训练。
特点
该数据集的显著特点在于其合成任务的高效性和多样性,这些任务在增强多模态大语言模型(MLLMs)的领域特定性能方面表现出色,超越了手动规则和GPT-4等方法生成的任务。此外,数据集的构建采用了单阶段训练管道,旨在提升任务多样性,适用于领域特定的后训练。
使用方法
用户可以通过HuggingFace Hub下载该数据集,包括文本数据和图像数据。文本数据包括image_caption_and_synthetic_task.json、image_caption_pairs.json和synthetic_visual_tasks.json,图像数据则需解压后使用。下载和解压步骤详见README文件。该数据集适用于多模态大语言模型的领域特定后训练,特别适用于食品领域的视觉问答和图像到文本任务。
背景与挑战
背景概述
food-visual-instructions数据集由Cheng, Daixuan等人于2024年创建,旨在通过后训练方法提升多模态大语言模型(MLLMs)在特定领域的表现。该数据集的核心研究问题是如何通过数据合成、训练管道优化和任务评估来实现领域适应。研究团队利用开源模型开发了视觉指令合成器,生成了多样化的视觉指令任务,并结合图像-文本对进行单阶段训练,以增强MLLMs在食品领域的性能。该数据集的构建基于扩展的Recipe1M+数据集,包含131K图像-文本对和39K合成指令-响应对,对多模态语言模型的领域适应研究具有重要意义。
当前挑战
food-visual-instructions数据集面临的主要挑战包括:1) 数据合成过程中如何确保生成的视觉指令任务具有高质量和多样性,超越手动规则和GPT-4等方法的生成效果;2) 单阶段训练管道的实施,如何在保持任务多样性的同时,有效提升模型在特定领域的性能;3) 任务评估的复杂性,需在多个领域和不同规模的MLLMs上进行广泛实验,以验证数据集的有效性和通用性。此外,数据集的构建还需解决图像和文本数据的一致性问题,确保合成任务的准确性和实用性。
常用场景
经典使用场景
food-visual-instructions数据集的经典使用场景主要集中在视觉问答(Visual Question Answering, VQA)和图像到文本生成(Image-to-Text)任务中。该数据集通过结合图像与指令生成的合成任务,能够有效提升多模态大语言模型(MLLMs)在食品领域的特定性能。例如,模型可以通过分析食品图像并生成相应的烹饪步骤或食材描述,从而在食品相关的视觉指令任务中表现出色。
解决学术问题
food-visual-instructions数据集解决了多模态大语言模型在特定领域(如食品)中的适应性问题。通过提供高质量的图像与指令对,该数据集帮助模型在食品领域的视觉问答和图像描述任务中取得显著进展,从而推动了多模态学习在特定领域中的应用研究。这一进展不仅提升了模型的领域适应能力,还为未来的多模态研究提供了新的方向。
衍生相关工作
food-visual-instructions数据集的发布催生了一系列相关研究工作。例如,基于该数据集的视觉指令合成器(Visual Instruction Synthesizer)被广泛应用于多模态模型的训练和评估。此外,该数据集还启发了在生物医学领域的类似研究,如开发针对医学图像的视觉问答系统。这些衍生工作进一步拓展了多模态学习在不同领域的应用边界。
以上内容由遇见数据集搜集并总结生成


