ice-id
收藏Hugging Face2025-05-15 更新2025-05-16 收录
下载链接:
https://huggingface.co/datasets/goldpotatoes/ice-id
下载链接
链接失效反馈官方服务:
资源简介:
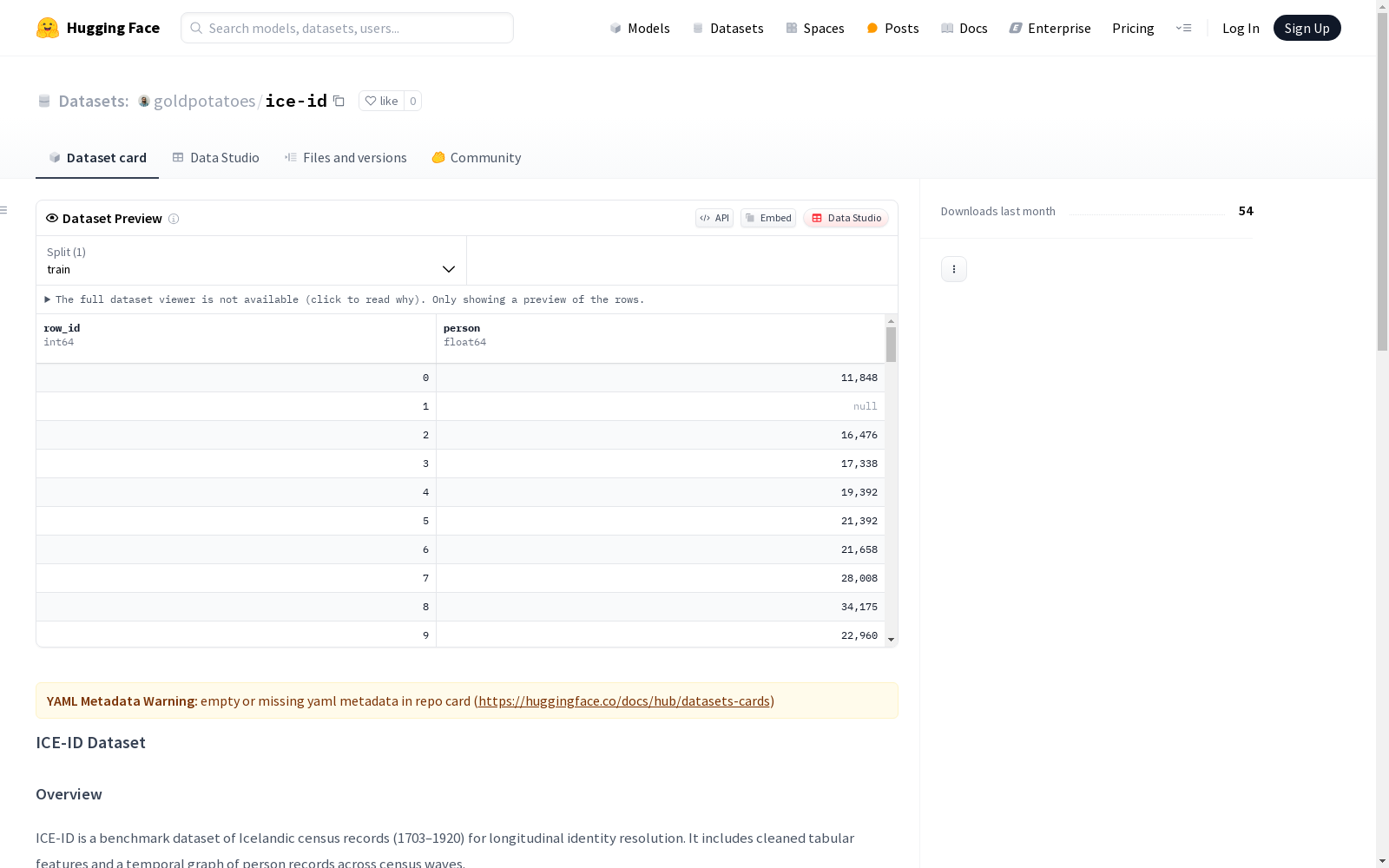
ICE-ID数据集是一个基于冰岛人口普查记录(1703-1920年)的基准数据集,用于长期身份识别研究。该数据集包括清洗后的表格特征和个人记录的时间图,跨越多个普查周期。
创建时间:
2025-05-11
原始信息汇总
ICE-ID 数据集概述
数据集简介
ICE-ID 是一个冰岛人口普查记录(1703–1920)的基准数据集,用于纵向身份解析。包含清洗后的表格特征和跨普查波次的个人记录时间图。
文件结构
原始数据
raw_data/people.csvraw_data/manntol_einstaklingar_new.csvraw_data/parishes.csv, districts.csv, counties.csv
处理后的数据
artifacts/row_labels.csv:行ID与人员映射artifacts/rows_with_person.csv:已链接的行子集artifacts/iceid_ml_ready.npz:包含数值、独热编码和序数特征的CSR矩阵artifacts/temporal_graph.pt:PyTorch Geometric数据(edge_index, node_id)
使用要求
- Python 3.7+
- 依赖库:numpy, pandas, scipy, scikit-learn, torch, torch-geometric
预处理
运行预处理脚本生成处理后的数据: bash python preprocess.py --data-dir raw_data --out-dir artifacts
使用方法
- 加载
iceid_ml_ready.npz获取机器学习特征(行×特征)。 - 使用
row_labels.csv将行映射到人员。 - 在 PyG 中加载
temporal_graph.pt: python import torch from torch_geometric.data import Data d = torch.load(artifacts/temporal_graph.pt) graph = Data(edge_index=d[edge_index]) graph.node_id = d[node_id]
许可证
MIT 许可证
搜集汇总
数据集介绍
构建方式
ICE-ID数据集基于冰岛历史人口普查记录(1703-1920年)构建,采用纵向身份解析技术对原始档案进行系统化整理。研究团队通过多源数据融合方法,将分散的教区、地区和县级行政记录整合为统一的结构化表格,并运用图神经网络技术构建跨时间维度的个人关系图谱。数据预处理流程包含特征工程、记录链接和时序图构建三个关键环节,最终形成可供机器学习直接使用的标准化矩阵表示。
特点
该数据集最显著的特点是实现了历史文档的时空双重维度建模。表格特征包含清洗后的数值型、独热编码和序数特征,完整保留原始普查记录的统计特性。时序图结构采用PyTorch Geometric框架存储,精确捕捉个体在跨世纪普查中的身份演变轨迹。数据划分严格遵循历史学研究规范,确保训练集、验证集和测试集在时间跨度上的合理分布,为纵向研究提供可靠基准。
使用方法
使用者可通过加载预处理的CSR格式特征矩阵直接进行机器学习建模,配套的行标签文件支持结果的可解释性分析。时序图数据采用PyG标准格式封装,支持图神经网络算法的快速部署。为保障研究可复现性,建议按照提供的预处理脚本重新生成中间产物,所有依赖库版本需严格匹配Python 3.7+环境。典型应用场景包括历史人口迁移模式分析、跨代际社会网络研究等纵向计算社会科学课题。
背景与挑战
背景概述
ICE-ID数据集由冰岛研究机构于近年构建,专注于解决历史人口统计学中的身份解析难题。该数据集系统收录了1703至1920年间冰岛人口普查记录,通过结构化处理形成了包含清洗后表格特征和时间序列图的高质量基准数据。作为纵向身份解析研究的重要载体,该数据集为追踪个体在跨普查周期中的身份演变提供了关键数据支持,对历史人口迁移、家族谱系重建等研究领域具有显著价值。数据集采用多层级地理行政单元编码,体现了北欧历史人口统计的典型特征。
当前挑战
该数据集面临的核心挑战在于历史记录的不完整性与异构性。原始普查数据存在手写体识别误差、跨时期记录标准不一致等问题,要求研究者开发鲁棒的特征对齐算法。时间图构建需解决同名消歧与跨期实体匹配难题,这对图神经网络模型的时序推理能力提出较高要求。数据预处理阶段涉及古冰岛语文本标准化、行政区划变迁映射等特殊挑战,需要融合历史语言学与统计建模的跨学科方法。稀疏记录条件下的身份链式重建构成该领域持续存在的技术瓶颈。
常用场景
经典使用场景
在历史人口学和计算社会科学领域,ICE-ID数据集为研究者提供了一个独特的视角,用于追踪冰岛人口在长达两个多世纪(1703–1920)间的动态变化。该数据集通过整合清洗后的表格特征和跨人口普查波次的时序图结构,使得研究者能够构建个体身份解析模型,从而分析人口迁移、家庭结构演变等长期社会现象。其经典使用场景包括基于图神经网络的跨记录实体解析,以及结合机器学习方法对历史人口统计特征进行预测建模。
衍生相关工作
基于该数据集衍生的经典工作包括时序图嵌入方法在历史记录中的应用,如TGN(Temporal Graph Networks)框架的适应性改进。多项研究利用其多模态特征开发了联合实体解析模型,其中融合语义相似度与图拓扑特征的Hybrid-Link方法表现突出。在数字人文领域,该数据集还催生了冰岛人口可视化分析平台Íslendingabók的升级版本。
数据集最近研究
最新研究方向
在历史人口学和数字人文领域,ICE-ID数据集为研究者提供了探索冰岛历史人口动态的独特窗口。该数据集整合了1703至1920年间冰岛人口普查记录,通过清洗后的表格特征和跨普查波次的时序图结构,为身份解析任务奠定了坚实基础。近期研究聚焦于图神经网络在纵向身份关联中的应用,利用时序图捕捉个体在历史记录中的演变轨迹。结合机器学习方法,学者们致力于解决历史文档中常见的姓名变异、记录缺失等挑战,为家族重建和人口迁移模式分析提供新视角。这一方向不仅推动了计算历史学的发展,也为跨学科研究开辟了道路。
以上内容由遇见数据集搜集并总结生成


