AF-Think
收藏Hugging Face2025-07-15 更新2025-07-15 收录
下载链接:
https://huggingface.co/datasets/nvidia/AF-Think
下载链接
链接失效反馈官方服务:
资源简介:
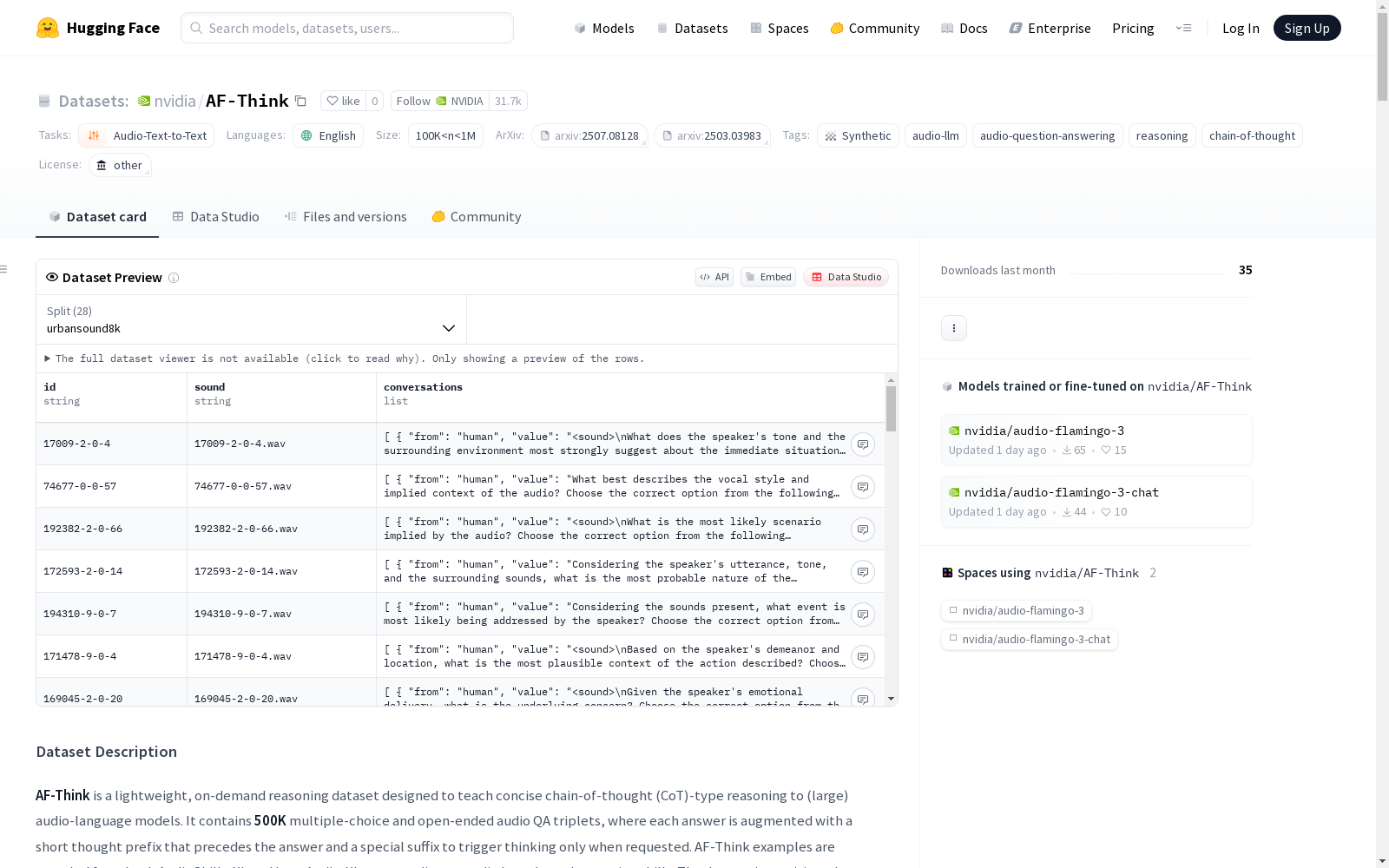
AF-Think是一个轻量级、按需推理数据集,旨在教授(大型)音频语言模型简洁的链式思维(CoT)推理。它包含50万个多项选择和开放式音频QA三元组,每个答案都带有简短的思想前缀,并在请求时触发特殊后缀。AF-Think示例从AudioSkills-XL和LongAudio-XL中采样,以涵盖不同的音频长度和推理技能。数据集根据每个音频的源数据集划分为子集。数据集旨在支持训练和微调(大型)音频语言模型,以便推理音频并使它们具有思维能力。
提供机构:
NVIDIA
创建时间:
2025-07-10
原始信息汇总
AF-Think 数据集概述
基本信息
- 名称: AF-Think
- 所有者: NVIDIA Corporation
- 创建日期: 2025/07/10
- 语言: 英语 (en)
- 许可证: NVIDIA OneWay Noncommercial License
- 大小: 100K<n<1M
- 标签: synthetic, audio-llm, audio-question-answering, reasoning, chain-of-thought
- 任务类别: audio-text-to-text
数据集描述
- 目的: 用于训练和微调(大型)音频语言模型,使其具备音频推理能力。
- 内容: 包含50万个多项选择和开放式音频QA三元组,每个答案都带有简短的前缀和后缀。
- 来源: 从AudioSkills-XL和LongAudio-XL中采样,覆盖多种音频长度和推理技能。
- 音频类型: 环境声音、语音(主要为英语)和音乐。
数据子集
数据集按音频来源划分为多个子集,包括但不限于:
- UrbanSound8K: 声音领域,来源:https://urbansounddataset.weebly.com/urbansound8k.html
- MusicCaps: 声音领域,来源:https://huggingface.co/datasets/google/MusicCaps
- MSD: 音乐领域,来源:http://millionsongdataset.com/
- Freesound: 声音领域,来源:https://freesound.org
- AudioSet_SL: 声音领域,来源:https://research.google.com/audioset/
- WavText5K: 声音领域,来源:https://github.com/microsoft/WavText5K
- MELD: 语音领域,来源:https://github.com/declare-lab/MELD
- AudioSet: 声音领域,来源:https://research.google.com/audioset/
- TUT_Urban: 声音领域,来源:https://dcase-repo.github.io/dcase_datalist/datasets/scenes/tut_asc_2018_mobile_eval.html
- Switchboard: 语音领域,来源:https://catalog.ldc.upenn.edu/LDC97S62
- Fisher: 语音领域,来源:https://catalog.ldc.upenn.edu/LDC2004T19
- ESC-50: 声音领域,来源:https://github.com/karolpiczak/ESC-50
- Clotho-v2: 声音领域,来源:https://zenodo.org/records/4783391
- BBC Sound Effects: 声音领域,来源:https://sound-effects.bbcrewind.co.uk/
- YouTube-8M: 声音和语音领域,来源:https://research.google.com/youtube8m/
- Medley-solos-DB: 音乐领域,来源:https://zenodo.org/records/3464194
- MACS: 声音领域,来源:https://zenodo.org/records/5114771
- Europarl: 语音领域,来源:https://www.statmt.org/europarl/
- VoxPopuli: 语音领域,来源:https://github.com/facebookresearch/voxpopuli
- MultiDialog: 语音领域,来源:https://huggingface.co/datasets/IVLLab/MultiDialog
- Medley-Pitch-DB: 音乐领域,来源:https://zenodo.org/records/3464194
- LibriSpeech: 语音领域,来源:https://www.openslr.org/12/
- IEMOCAP: 语音领域,来源:https://sail.usc.edu/iemocap/
- FSD50k: 声音领域,来源:https://zenodo.org/records/4060432
- FMA: 音乐领域,来源:https://github.com/mdeff/fma
- DailyTalk: 语音领域,来源:https://github.com/keonlee9420/DailyTalk
- VGGSound: 声音领域,来源:https://github.com/amirabd/vggsound
- SONNISS: 声音领域,来源:https://sonniss.com/
- MagnaTagATune: 音乐领域,来源:http://mirg.city.ac.uk/codeapps/the-magnatagatune-dataset
- GTZAN: 音乐领域,来源:https://github.com/chittalpatel/Music-Genre-Classification-GTZAN
数据格式
- 模态: 音频 (WAV/MP3/FLAC) + 文本 (JSON)
- JSON示例: json [ { "id": "Arbitary ID", "sound": "Name of the wav file.", "conversations": [ { "from": "human", "value": "<sound> The Question." }, { "from": "gpt", "value": "The Answer." } ] } ]
注意事项
- 仅提供文本QA注释,不提供原始音频文件。
- 用户需自行从原始来源获取音频文件。
- 使用需遵守NVIDIA OneWay Noncommercial License及其他相关许可证。
参考文献
- Goel, A., et al. (2025). Audio Flamingo 3: Advancing Audio Intelligence with Fully Open Large Audio Language Models. arXiv:2507.08128.
- Kong, Z., et al. (2024). Audio Flamingo: A Novel Audio Language Model with Few-Shot Learning and Dialogue Abilities. International Conference on Machine Learning.
- Ghosh, S., et al. (2025). Audio Flamingo 2: An Audio-Language Model with Long-Audio Understanding and Expert Reasoning Abilities. arXiv:2503.03983.
搜集汇总
数据集介绍
构建方式
AF-Think数据集的构建融合了多源音频数据与先进的语言模型技术,通过精心设计的流程实现高质量数据合成。该数据集从AudioSkills-XL和LongAudio-XL中采样音频片段,覆盖环境声音、语音和音乐等多元场景。研究人员利用原始数据集提供的元数据(如字幕、转录文本等),结合专家设计的推理提示模板,通过大语言模型生成50万条带思维链标记的问答三元组。整个构建过程采用人机协同的迭代优化机制,确保数据质量与逻辑严谨性。
特点
作为专为音频语言模型设计的推理训练集,AF-Think的突出特点体现在其精细的思维链标注体系。每个问答对均包含触发推理的特殊前缀和后缀标记,支持按需激活模型的思考能力。数据集涵盖30秒内的短音频片段,包含选择题和开放式问题两种形式,问题类型跨越声音识别、语义理解、逻辑推理等多个层次。通过整合UrbanSound8K、AudioSet等32个权威子集,该数据集实现了音频长度与认知技能的双重多样性,为模型提供全面的训练场景。
使用方法
使用AF-Think时需注意其独特的模态组合特性。研究者需自行从原始来源获取音频文件,与数据集提供的JSON标注文件配合使用。标注文件采用标准化结构,包含音频文件名、人类提问和模型回答三个关键字段。典型应用场景包括:通过微调提升音频语言模型的推理能力,或作为评估基准测试模型的多步思考性能。由于采用非商业许可,使用者应严格遵守各子集的原始授权协议,特别注意合成数据可能涉及的额外条款要求。
背景与挑战
背景概述
AF-Think数据集由NVIDIA Corporation于2025年7月发布,旨在为音频语言模型提供轻量级的推理训练资源。该数据集包含50万个多选和开放式音频问答三元组,每个答案均附有简短的前缀思考提示和特殊后缀,以触发模型在需要时进行推理。AF-Think的样本来源于AudioSkills-XL和LongAudio-XL,涵盖了多样化的音频长度和推理技能。数据集涵盖了环境声音、语音(主要为英语)和音乐等多个领域,其音频来源于多个开源数据集,如UrbanSound8K、MusicCaps和AudioSet等。AF-Think的发布为音频推理任务的研究提供了丰富的资源,推动了音频语言模型在推理能力上的进步。
当前挑战
AF-Think数据集面临的主要挑战包括两个方面:领域问题的挑战和构建过程的挑战。在领域问题方面,音频语言模型需要处理复杂的多模态推理任务,包括音频理解、上下文关联和逻辑推理,这对模型的泛化能力和鲁棒性提出了较高要求。在构建过程中,由于音频数据来源多样且涉及不同许可协议,数据整合与标注面临法律和技术上的复杂性。此外,生成高质量的问答对需要依赖专家设计的推理提示和人工迭代优化,以确保数据的准确性和多样性。这些挑战使得数据集的构建和维护成本较高,同时也为后续研究提供了改进方向。
常用场景
经典使用场景
在音频语言模型的研究领域,AF-Think数据集被广泛用于训练和优化模型在复杂音频场景下的推理能力。通过提供50万条包含思维链的多选题和开放式音频问答三元组,该数据集能够有效模拟真实世界中的音频理解任务,如环境声音识别、语音情感分析和音乐风格分类。其独特的设计使得模型能够学习在回答问题前进行简短的逻辑推理,这一特性在音频字幕生成和对话系统等任务中展现出显著优势。
实际应用
在实际应用层面,AF-Think数据集支撑了多个前沿技术的开发。基于该数据集训练的模型已成功部署于智能家居系统的声音事件检测、音乐流媒体平台的自动标签生成以及客服中心的语音情感分析等场景。其独特的思维链标注机制尤其适用于需要可解释决策的医疗诊断辅助系统,例如通过咳嗽声分析呼吸道疾病的AI应用。这些实践验证了数据集在跨领域音频理解任务中的强大泛化能力。
衍生相关工作
AF-Think数据集催生了一系列重要的衍生研究,包括Audio Flamingo系列模型的持续优化。在Audio Flamingo 3中,研究者利用该数据集实现了开放域音频语言模型的突破性进展。同时,基于该数据集的多篇顶会论文探索了音频推理的新方法,如《Chain-of-Thought Prompting for Audio Question Answering》等研究,这些工作共同推动了音频语言理解领域向更智能、更可解释的方向发展。
以上内容由遇见数据集搜集并总结生成


