proxima-fusion/coilstellaration
收藏Hugging Face2026-05-06 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/proxima-fusion/coilstellaration
下载链接
链接失效反馈官方服务:
资源简介:
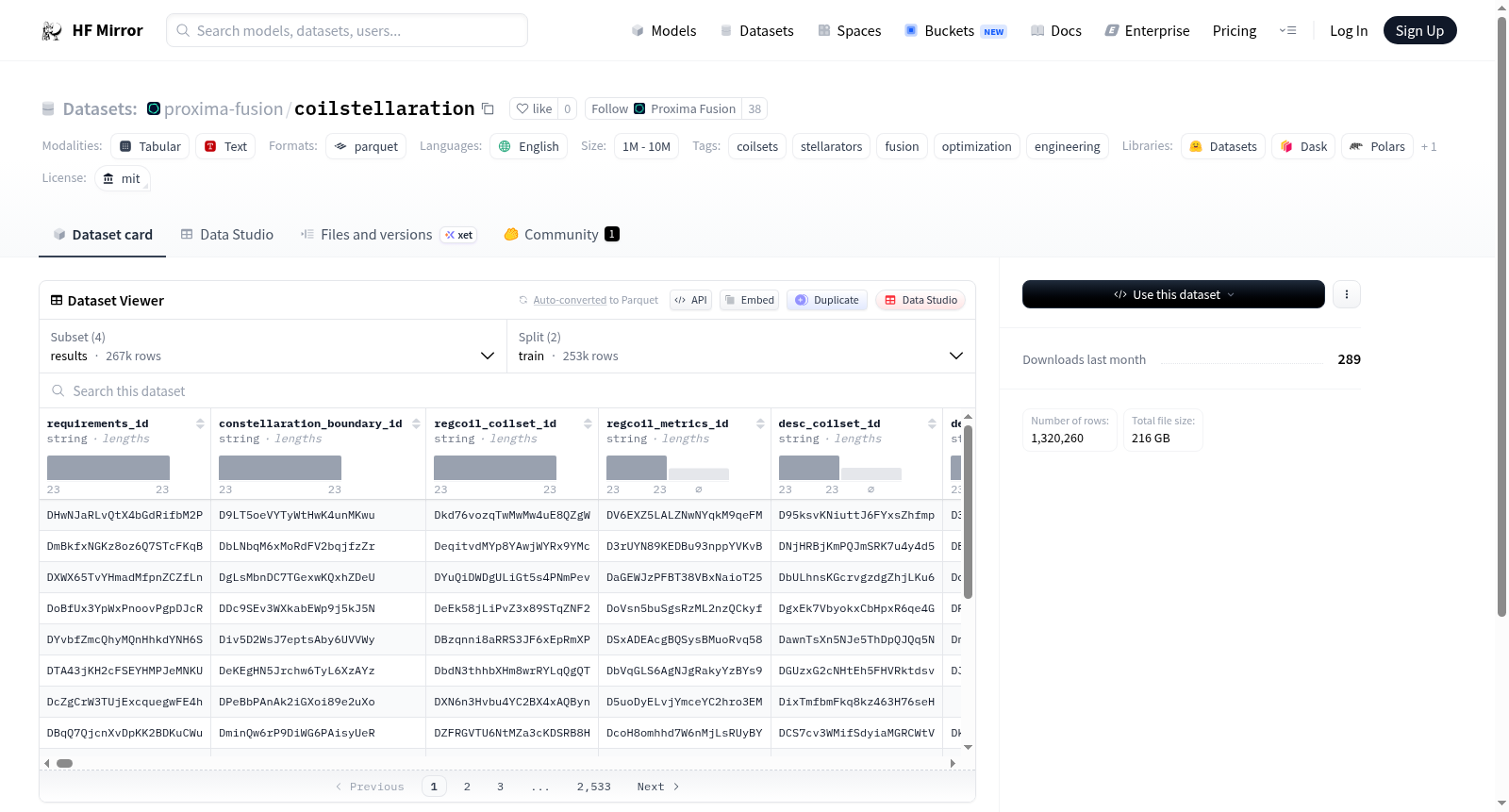
CoilStellaration数据集是一个用于聚变工程和优化研究的数据集,专注于仿星器线圈集的设计与分析。数据集包含多个配置:results(训练和评估数据)、metrics(指标数据)、requirements(需求数据)和coilsets(线圈集数据),数据格式为Parquet。数据集规模中等,条目数量在100万到1000万之间,语言为英语,许可证为MIT。该数据集支持聚变能源、工程优化和线圈设计等领域的研究。
The CoilStellaration dataset is designed for fusion engineering and optimization research, focusing on the design and analysis of stellarator coil sets. It includes multiple configurations: results (training and evaluation data), metrics (metric data), requirements (requirement data), and coilsets (coil set data), with data stored in Parquet format. The dataset is medium-sized, containing between 1 million and 10 million entries, is in English, and is licensed under MIT. It supports research in fusion energy, engineering optimization, and coil design.
提供机构:
proxima-fusion
搜集汇总
数据集介绍
构建方式
CoilStellaration数据集源自聚变能源领域对仿星器线圈优化的前沿研究,通过大规模数值模拟与工程参数耦合构建而成。数据集包含四大核心配置:results配置存储了训练与评估的parquet格式数据,涵盖线圈设计的优化结果;metrics配置记录性能指标;requirements配置保存运行依赖;coilsets配置则收纳线圈集合的几何与拓扑信息。所有数据均以分片parquet文件组织,便于高效分布式处理。
特点
该数据集规模横跨百万至千万量级样本,具备多维度工程特征。results配置提供分拆的训练与验证集,支撑监督学习范式;metrics与requirements配置协同描述优化过程的约束与目标空间。coilsets配置收录的线圈拓扑结构具有高维度几何特征,适用于生成模型与逆向设计。采用MIT开源协议并仅含英文标注,聚焦聚变装置设计中的线圈布局、磁场分布等关键物理量。
使用方法
用户可通过HuggingFace Datasets库加载数据,指定config_name参数选择results、metrics等子集。针对results配置,可使用train与eval分拆构建机器学习管线,适合回归或生成任务。coilsets配置支持序列化拓扑数据的解析,可用于强化学习环境或代理模型训练。建议结合parquet的列式存储特性,对尺寸场、电流密度等连续变量进行归一化预处理,以适配神经网络输入规范。
背景与挑战
背景概述
核聚变作为一种清洁、几乎无限的能源,其实现高度依赖于先进磁约束装置的设计,其中仿星器因其稳定的等离子体特性而备受关注。然而,仿星器设计中关键的线圈优化过程极为复杂,传统方法通常依赖昂贵的数值模拟与人工迭代。CoilStellaration数据集应运而生,由相关研究机构于近期创建,旨在系统性地收集和存储经过优化的仿星器线圈配置数据,涵盖从等离子体边界到三维线圈绕组的映射关系。该数据集以标准化格式提供了数百万个数据样本,为机器学习模型在聚变工程中的应用奠定了坚实基础,显著推动了仿星器设计的自动化和智能化进程,对聚变能源领域具有重要的数据支撑意义。
当前挑战
CoilStellaration数据集所解决的核心领域挑战在于,仿星器线圈优化是一个高维、非凸且计算密集的问题,传统手工设计难以在合理时间内探索广阔的设计空间,导致等离子体约束性能与工程可行性之间的平衡难以达成。在构建过程中,面临的主要挑战包括:生成高质量且物理一致的线圈配置数据需要大量昂贵的磁流体动力学模拟与多目标优化计算;确保数据集覆盖足够多样的等离子体边界形状,同时保持标签(如线圈复杂度、磁场精度)的准确性与一致性;此外,还需处理海量数据的存储、组织与版本控制,以便于后续模型训练和跨机构复用。
常用场景
经典使用场景
CoilStellaration数据集聚焦于聚变能研究领域中的仿星器(stellarator)设计,其经典使用场景在于为磁约束聚变装置的线圈优化提供标准化数据基础。通过包含大量线圈组(coilsets)及其对应的性能指标(metrics),该数据集能够支撑研究人员训练机器学习模型,以替代传统耗时且计算成本高昂的物理仿真过程,从而高效探索线圈拓扑结构与等离子体约束性能之间的复杂映射关系。
实际应用
在实际工程应用中,CoilStellaration数据集服务于聚变反应堆的快速原型设计与迭代优化。工程团队可借助该数据集训练的代理模型,在不依赖全阶仿真器的情况下,快速预筛选出候选线圈配置,从而将设计周期从数月缩短至数天。此外,该数据集还可用于验证新型制造工艺对线圈精度的容差要求,评估工程约束下最优线圈的鲁棒性,加速商用聚变电站从理论走向工程落地。
衍生相关工作
CoilStellaration数据集已衍生出多项代表性工作,包括基于扩散模型的线圈生成框架、结合物理信息的神经网络代理模型,以及多目标进化算法在线圈拓扑搜索中的改进应用。这些工作不仅验证了数据驱动方法在仿星器设计中的有效性,还启发了后续研究者构建包含更多物理场(如磁流体动力学稳定性)的复合数据集,逐步形成聚变领域AI for Science的标准化数据生态。
以上内容由遇见数据集搜集并总结生成


