Qwen-Image-Bench
收藏Hugging Face2026-05-28 更新2026-05-29 收录
下载链接:
https://huggingface.co/datasets/Qwen/Qwen-Image-Bench
下载链接
链接失效反馈官方服务:
资源简介:
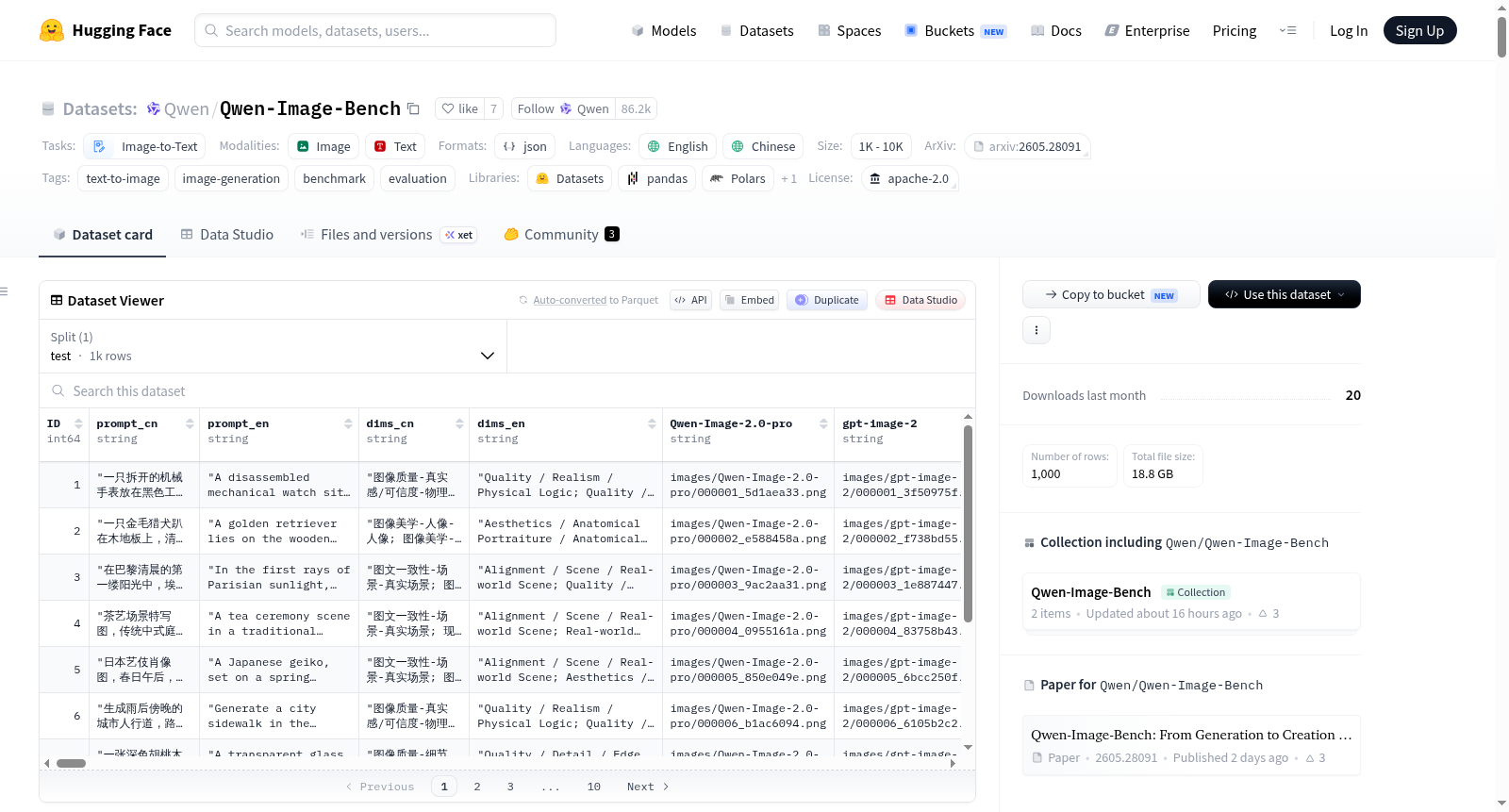
Qwen-Image-Bench 是一个面向创作者的文本到图像生成模型评估基准数据集。它旨在超越传统的语义对齐评估,通过引入“真实世界保真度”和“创意生成”两个应用驱动维度,满足专业创意工作流对真实还原和创意表达的高要求。该数据集包含1,000个由专家精心设计的中英文双语提示词,这些提示词在长度和语言上均衡分布,每个提示词均设计用于联合考察跨多个评估维度的4个以上细粒度方面。数据集采用一个三层层次化评估体系,包含5个顶级支柱(质量、美学、对齐、真实世界保真度、创意生成)、23个子能力和56个具体评估方面。数据集文件为JSONL格式,每条记录包含提示词ID、中英文提示文本、评估维度描述、18个前沿T2I模型(如GPT Image 2、Qwen Image 2.0 Pro等)生成的图像路径,以及一个配套的统一诊断评判模型(Q-Judger)对每个模型在各维度上的原始评估输出。Q-Judger模型基于大量专家标注数据训练,能为每个样本生成覆盖全部56个细粒度方面的得分向量,实现模型能力的精准诊断。该基准适用于对文本到图像生成模型进行全面的、贴近真实创作场景的评估与能力分析。
Qwen-Image-Bench is a benchmark dataset for evaluating text-to-image generation models, aimed at creators. It goes beyond traditional semantic alignment evaluation by introducing two application-driven dimensions: "real-world fidelity" and "creative generation," meeting the high demands of professional creative workflows for realistic restoration and creative expression. The dataset includes 1,000 expertly designed bilingual prompts in Chinese and English, evenly distributed in length and language, with each prompt designed to jointly examine over four fine-grained aspects across multiple evaluation dimensions. It employs a three-tier hierarchical evaluation system comprising five top-level pillars (quality, aesthetics, alignment, real-world fidelity, creative generation), 23 sub-capabilities, and 56 specific evaluation aspects. The dataset files are in JSONL format, with each record containing a prompt ID, Chinese and English prompt texts, evaluation dimension descriptions, image paths generated by 18 cutting-edge T2I models (such as GPT Image 2, Qwen Image 2.0 Pro, etc.), and the raw evaluation output from a unified diagnostic judgment model (Q-Judger) for each model across dimensions. The Q-Judger model is trained on extensive expert-annotated data and can generate score vectors covering all 56 fine-grained aspects for each sample, enabling precise diagnosis of model capabilities. This benchmark is suitable for comprehensive evaluation and capability analysis of text-to-image generation models in scenarios close to real-world creation.
提供机构:
Qwen
创建时间:
2026-05-21
原始信息汇总
数据集概述:Qwen-Image-Bench
Qwen-Image-Bench 是一个以创作者为中心的文本到图像(T2I)生成模型评估基准,旨在超越传统的语义对齐,评估模型在真实创意工作流中的表现。
核心特性:
- 三层等级分类体系 (Three-Level Hierarchical Taxonomy): 从专业艺术工作流程(构思→风格化→迭代优化)出发,自上而下设计。
- 5 个一级支柱 (L1 Pillars): 质量 (Quality)、美学 (Aesthetics)、对齐 (Alignment)、真实世界保真度 (Real-world Fidelity) 和创意生成 (Creative Generation)。
- 23 个二级子能力 (L2 Sub-capabilities): 例如世界知识、文本渲染、视觉叙事、设计应用等。
- 56 个三级评估细项 (L3 Evaluation Facets): 提供细粒度、可验证的评分细则。其中 28 个细项属于“真实世界保真度”和“创意生成”这两个应用驱动的支柱。
- 1,000 条专家精心设计的双语提示 (Expert-Crafted Bilingual Prompts):
- 在文本长度(500 条长提示 + 500 条短提示)和语言(中文/英文)上分层且均衡。
- 每条提示会同时激活多个支柱下的 4 个以上细粒度评估细项。
- Q-Judger 诊断评估模型:
- 基于 Qwen3.6-27B 模型,为每个样本生成跨越全部 56 个三级细项的完整评分向量。
- 在超过 130,000 个由专家标注的双语提示-图像对上训练。
- 由 80 位来自艺术院校的专业标注员监督,每个样本至少有 3 份独立评审。
- 与人类专家判断的排名一致性达到 Spearman ρ = 0.92。
数据概览:
| 属性 | 描述 |
|---|---|
| 许可协议 | Apache-2.0 |
| 任务类型 | 图像到文本 (image-to-text) |
| 语言 | 英语 (en), 中文 (zh) |
| 数据集规模 | 1K < n < 10K (1000 条提示) |
| 标签 | text-to-image, image-generation, benchmark, evaluation |
| 数据文件 | qwen_image_bench_hf_v0518.jsonl (测试集) |
数据字段:
| 字段名 | 类型 | 描述 |
|---|---|---|
ID |
int | 唯一提示标识符 (1-1000) |
prompt_cn |
str | 中文文本提示 |
prompt_en |
str | 英文文本提示 |
dims_cn |
str | 该提示对应的评估维度 (中文) |
dims_en |
str | 该提示对应的评估维度 (英文) |
<model_name> |
str | 各模型生成的图像相对路径 (对应中文提示) |
quality_response_<model> |
str | 评估模型在“质量”维度的原始输出 |
aesthetics_response_<model> |
str | 评估模型在“美学”维度的原始输出 |
alignment_response_<model> |
str | 评估模型在“对齐”维度的原始输出 |
creative_generation_response_<model> |
str | 评估模型在“创意生成”维度的原始输出 |
real_world_fidelity_response_<model> |
str | 评估模型在“真实世界保真度”维度的原始输出 |
包括的模型 (18个): Qwen-Image-2.0-pro, Gpt-Image-2, FLUX.2-Max, Nano-Banana-2.0, Nano-Banana-Pro, Seedream-4.0, Seedream-4.5, Seedream-5.0, GLM-Image, Kling-v2.1, Qwen-Image-2512, Qwen-Image, GPT-Image-1, GPT-Image-1.5, HunyuanImage-3.0, Imagen-4.0, Imagen-4.0-Ultra, FLUX.2-Pro
评估维度 (三级评分体系):
- 质量 (Quality): 包含现实主义(物理逻辑、材质纹理)、细节(噪点、边缘清晰度、自然度)、分辨率。
- 美学 (Aesthetics): 包含构图、色彩和谐、光影、解剖学肖像、情感表达、风格控制。
- 对齐 (Alignment): 包含属性(数量、面部表情、材质属性、颜色、形状、大小)、动作(接触互动、非接触互动、全身动作)、布局(2D空间、3D空间)、关系(构成关系、差异/相似、包含关系)、场景(真实场景、虚拟场景)。
- 真实世界保真度 (Real-world Fidelity): 包含公平性(社会偏见、文化公平)、安全与合规、世界知识(动物、物体、信息可视化、时间特征、文化元素)。
- 创意生成 (Creative Generation): 包含想象力、特征匹配、逻辑解析、文本渲染(文本准确性、文本布局、字体、跨语言生成)、设计应用(平面设计、产品设计、空间设计、时尚造型、游戏设计、艺术设计)、视觉叙事(电影风格、镜头/镜头风格、故事板创作、镜头尺寸、构图、角度、漫画创作)。
评分方法:
- 原始分数映射:
0(失败) →0;1(通过) →60;2(优秀) →100;N/A(不适用) → 排除。 - 评分流水线: 分数自下而上聚合:三级细项 → 二级子能力 → 一级支柱 → 总体得分。每个样本的总体得分是其激活的一级支柱得分的未加权平均值。模型级得分是所有 1000 条提示的平均值。
主要排行榜结果: 在评估的 18 个前沿模型中,GPT Image 2 以 64.69 的总体得分位居榜首,领先第二名近 5 分。模型自然分为 5 个性能梯队。研究发现,“创意生成”和“真实世界保真度”这两个应用驱动支柱表现出最大的模型间方差,而物理逻辑、解剖学保真度等细项是整个 T2I 技术的系统性能力天花板。
获取更多信息:
- 论文: http://arxiv.org/abs/2605.28091
- GitHub 仓库: https://github.com/QwenLM/Qwen-Image-Bench
- 模型 (HuggingFace): https://huggingface.co/Qwen/Qwen-Image-Bench
- 模型 (ModelScope): https://modelscope.cn/models/Qwen/Qwen-Image-Bench
- 数据集 (ModelScope): https://www.modelscope.cn/datasets/Qwen/Qwen-Image-Bench
搜集汇总
数据集介绍
构建方式
Qwen-Image-Bench 是一个以创作者为中心的文本到图像生成模型评估基准,其构建过程严格遵循专业艺术创作的实际流程。该数据集与专业艺术家协同设计,基于一个三级层次化分类体系,从构思、风格化到迭代精炼的创作逻辑出发,构建了包含5个一级支柱(质量、美学、对齐、真实世界保真度、创意生成)、23个二级子能力和56个三级评估维度的全面评估框架。数据集的提示词部分包含1000条精心策划的中英文双语提示,经过分层平衡,确保长短提示(各500条)和语言分布均匀,每条提示需联合考察4个以上的细粒度维度,以有效测试模型在从简单描述到专业规格不同层次上的表现。
使用方法
使用 Qwen-Image-Bench 进行模型评估的流程清晰简便。用户首先根据 README 中的安装指南配置环境,包括创建虚拟环境并安装 PyTorch 及相关依赖。若需基于预生成的模型响应计算得分,可直接运行 compute_scores.py 脚本,指定本地 JSONL 文件或通过 Hugging Face 仓库路径下载数据,脚本将自动生成包含详尽评分结果的 Excel 和 JSON 文件。对于希望评估自定义生成图像的场景,用户需准备包含 ID、提示词和图像路径的输入文件,其中 ID 必须与基准元数据中的1至1000编号相匹配,随后可调用 Q-Judger 模型进行推理,获取该模型在所有56个维度上的细粒度评分向量,从而完成全面诊断。
背景与挑战
背景概述
文本到图像(Text-to-Image, T2I)生成技术已从基础图像合成演进为专业创意工作流中的核心能力。然而,现有基准评测多聚焦于语义对齐等基础指标,难以有效区分前沿模型的表现,且评估流程常依赖单一多模态大语言模型作为评判,偏离了专业人类标准。在此背景下,由Qwen团队携手专业艺术家共同设计的Qwen-Image-Bench于2025年应运而生。该数据集以创作者为中心,在质量、美学与文本-图像对齐的传统支柱之上,创新性地引入了现实世界保真度与创意生成两大应用驱动维度,构建了包含5个一级支柱、23个二级子能力及56个三级评估面的三层分级评估体系。数据集包含1000条经专家精心设计的双语提示,并配套了基于Qwen3.6-27B的Q-Judger评判模型,在13万条专家标注数据上训练,与人类判断的斯皮尔曼相关系数达0.92。通过对18个前沿T2I模型的全面评测,该基准成功将模型区分为五个性能梯队,识别出物理逻辑、解剖学保真度等系统性瓶颈,为T2I领域的研究提供了更具区分力与诊断性的评估工具。
当前挑战
Qwen-Image-Bench所应对的核心领域挑战在于,现有T2I基准难以反映真实创作场景中的复杂需求,尤其是对现实世界忠实重构与创意表达的评估缺失,导致模型间能力差异无法被有效捕捉。该数据集通过引入现实世界保真度与创意生成两大新维度,揭示了传统指标所忽视的能力鸿沟——创意生成维度的方差是质量的11倍以上,成为最具区分力的评估面。在构建过程中,团队面临多重挑战:首先,需要与专业艺术家协作设计涵盖高频创作场景的三级评估体系,将抽象的艺术创作流程拆解为可量化的56个细粒度评估面;其次,标注过程涉及80位来自艺术学院的专业评审,对每个样本进行至少三轮盲标,以确保评判标准的一致性与专业性;此外,还需训练一个统一的诊断评判模型Q-Judger,使其能忠实复现人类专家的多维度评价,并保障评估结果的鲁棒性与可解释性。
常用场景
经典使用场景
在文本到图像生成研究领域,Qwen-Image-Bench的经典用途在于对前沿模型进行多层次、细粒度的能力诊断。该基准构建了涵盖质量、美学、语义对齐、真实世界保真度与创意生成五个支柱的三级分类体系,共包含56个精细评估维度。研究者可利用其1000条专家精心设计的中英双语提示词,对模型进行全面的压力测试,并通过专用的Q-Judger评估模型获取每个样本在全部维度上的分数向量,从而系统性地揭示模型在诸如物理逻辑、解剖学准确性等系统性天花板能力上的表现优劣。
解决学术问题
该数据集精准回应了现有评估基准难以区分顶级模型、且易受单一评判模型偏见影响的学术困境。它通过引入以创作者为中心的应用驱动维度,填补了传统评估框架在真实世界保真度与创意生成方面的空白。Qwen-Image-Bench的提出有力地推动了图像生成评估从粗粒度的语义对齐向精细化的能力剖面分析演进,其揭示的模型性能分层与系统性能力瓶颈,为学术界理解当前技术边界、明确未来攻关方向提供了坚实的定量依据,具有引领性的学术意义。
实际应用
在实际应用层面,Qwen-Image-Bench为专业创意工作者和AI内容生成平台提供了可靠的模型遴选与能力审计工具。从业者可以依据该基准在图形设计、影视分镜、动漫创作、信息可视化、跨文化内容制作等高频现实场景中的评测结果,精准匹配适合自身工作流的生成模型。例如,一个需要高精度文本渲染和故事板创作的影视团队,可依据基准中创意生成支柱下的具体得分,选择表现最佳的模型,从而避免在真实项目中因模型能力短板而导致的返工与效率损失。
数据集最近研究
最新研究方向
围绕Qwen-Image-Bench这一以创作者为中心的图像生成评估基准,当前前沿研究方向聚焦于超越传统语义对齐的细粒度、多层次图生文模型能力诊断。该基准通过构建五维支柱、二十三项子能力与五十六个第三级评估面,并结合基于Qwen3.6-27B的Q-Judger评判模型,实现了对图像质量、美学、对齐、真实世界保真度与创意生成能力的全方位量化分析。研究发现,创意生成与真实世界保真度成为区分前沿模型能力层级的关键维度,物理逻辑、解剖保真度等系统性天花板揭示了现有技术瓶颈。该基准已对GPT Image 2、Qwen Image 2.0 Pro等18个代表性模型进行评测,结果明确划分出五个性能梯队,为理解模型能力差异与指导未来研究提供了重要参考。
以上内容由遇见数据集搜集并总结生成


