apple/DataCompDR-1B
收藏Hugging Face2026-04-20 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/apple/DataCompDR-1B
下载链接
链接失效反馈官方服务:
资源简介:
DataCompDR-1B是一个图像-文本数据集,是对DataComp数据集的增强。通过多模态数据集增强策略,生成了DataCompDR-1B和DataCompDR-12M两个版本。数据集包含合成标题、嵌入和元数据,这些元数据是通过在DataComp-1B上使用预训练的图像-文本模型生成的。每个图像生成5个合成标题,并使用两个强大的教师模型计算增强图像以及真实和合成标题的嵌入。数据集的结构包括图像URL、合成标题、增强参数、图像嵌入和文本嵌入等字段。
DataCompDR-1B是一个图像-文本数据集,是对DataComp数据集的增强。通过多模态数据集增强策略,生成了DataCompDR-1B和DataCompDR-12M两个版本。数据集包含合成标题、嵌入和元数据,这些元数据是通过在DataComp-1B上使用预训练的图像-文本模型生成的。每个图像生成5个合成标题,并使用两个强大的教师模型计算增强图像以及真实和合成标题的嵌入。数据集的结构包括图像URL、合成标题、增强参数、图像嵌入和文本嵌入等字段。
提供机构:
apple
原始信息汇总
数据集概述
数据集名称: DataCompDR-1B
数据集描述: DataCompDR-1B是一个增强版的图像-文本数据集,旨在通过多模态数据增强策略强化原始的DataComp数据集。该数据集通过使用预训练的图像-文本模型生成合成标题、嵌入和元数据。每个图像生成5个合成标题,并计算增强图像以及真实和合成标题的嵌入。
数据集特征:
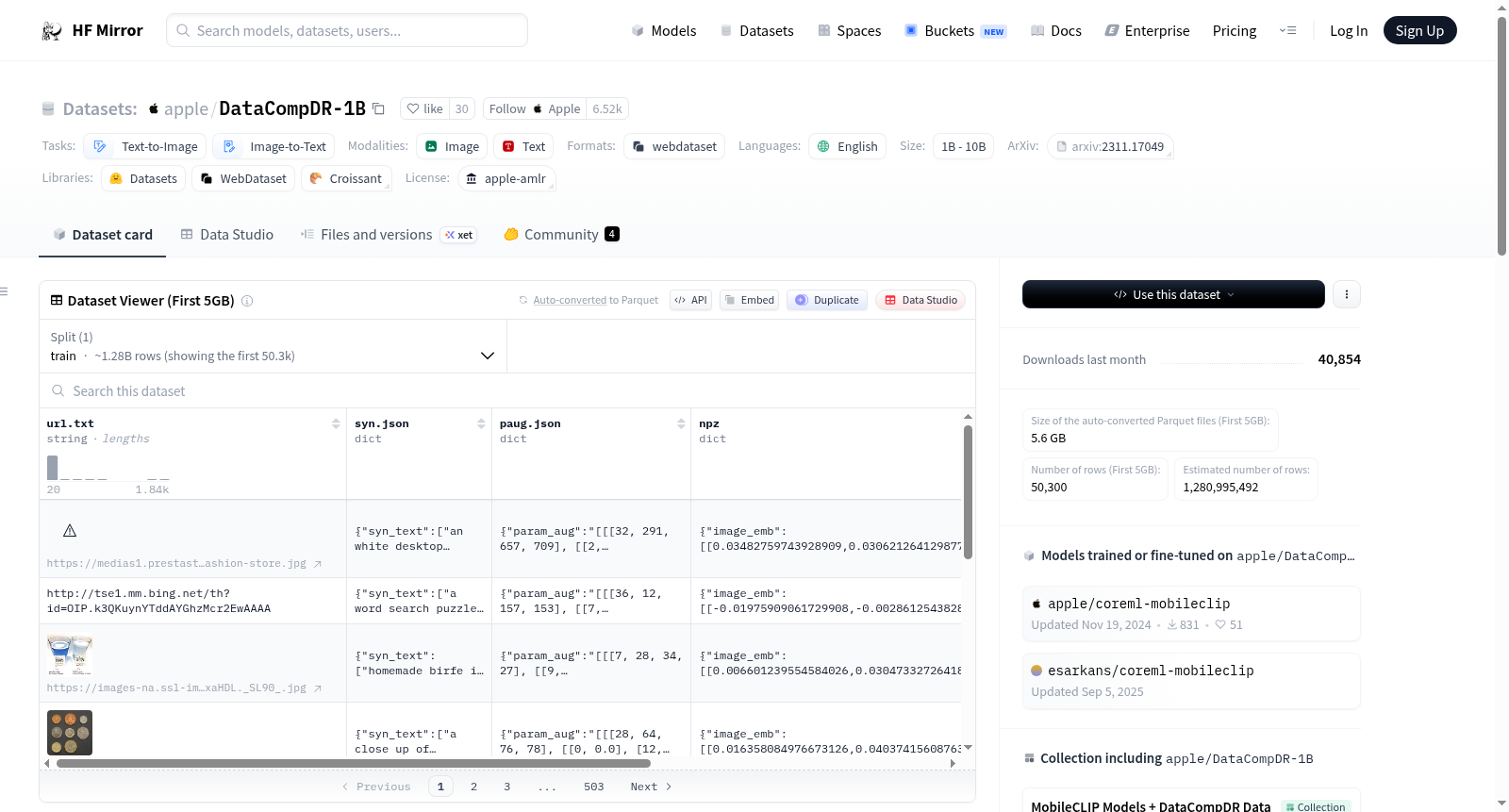
- url.txt: 图像URL,数据类型为字符串。
- syn.json: 包含合成文本的结构,其中
syn_text是一个字符串列表。 - paug.json: 包含参数增强的结构,其中
param_aug是一个字符串。 - npz: 包含图像和文本嵌入的结构,其中
image_emb和text_emb都是浮点数列表的列表。 - json: 包含元数据的结构,其中
uid和sha256都是字符串。
任务类别:
- 文本到图像
- 图像到文本
语言: 英语
许可证: 自定义Apple许可证,详细信息可在此处查看。
数据集用途:
- 用于训练图像-文本模型,显示出比标准CLIP训练更高的学习效率。
- 在单个节点上使用8×A100 GPUs,通过在DataCompDR-12M上训练ViT-B/16基础的CLIP,可以在大约一天内达到61.7%的零样本分类准确率。
数据集结构:
- 每个样本包括一个随机增强的图像、一个真实标题和一个随机选择的合成标题。
引用信息: bibtex @InProceedings{mobileclip2024, author = {Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Raviteja Vemulapalli, Oncel Tuzel}, title = {MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, month = {June}, year = {2024}, }
搜集汇总
数据集介绍
构建方式
在视觉-语言多模态学习领域,DataCompDR-1B数据集通过创新的强化策略构建而成。其核心流程是对原始DataComp-1B数据集进行元数据增强,利用OpenCLIP中的coca_ViT-L-14模型为每幅图像生成五条合成描述,并应用强随机图像增强技术。随后,通过集成两个强大的教师模型(ViT-L-14)对增强后的图像以及真实与合成描述进行嵌入计算,生成1536维的联合表征。每个数据样本最终被构建为一个包含随机增强图像、真实描述和随机选取的合成描述的三元组。
使用方法
该数据集旨在高效训练如CLIP架构的视觉-语言模型。使用者可直接加载预计算的图像与文本嵌入,或结合原始URL获取图像,并利用提供的合成描述与增强参数进行数据扩增。在训练流程中,模型可同时学习来自真实描述与多样化合成描述的文本对齐信号,以及经过强增强的图像表征。实践表明,采用此数据集进行训练,能在显著减少计算预算的前提下,于单节点GPU配置下快速达到优异的零样本分类性能,实现相比原始数据十倍至千倍的学习效率提升,为快速迭代与模型轻量化提供了有力支持。
背景与挑战
背景概述
在计算机视觉与自然语言处理交叉的多模态学习领域,高质量的大规模图文数据集是推动模型性能突破的关键。DataCompDR-1B数据集由苹果公司于2024年基于DataComp-1B数据集构建,旨在通过多模态数据增强策略强化原始数据。该数据集的核心研究问题聚焦于提升对比语言-图像预训练的效率与效果,通过生成合成标题与计算强教师模型的嵌入,为CLIP类模型提供更丰富的监督信号。其创新性方法在MobileCLIP等工作中得到验证,显著加速了模型训练过程,并在零样本分类等任务上设立了新的性能标杆,对高效多模态学习研究产生了深远影响。
当前挑战
DataCompDR-1B数据集致力于解决多模态表示学习中数据质量与训练效率的挑战。具体而言,其旨在克服传统CLIP训练对海量计算资源的依赖,通过增强数据多样性来提升模型的学习效率。在构建过程中,研究团队面临多重挑战:一是合成标题的生成需依赖高性能图文模型以确保语义准确性;二是强随机图像增强与多教师模型嵌入的计算涉及复杂的工程优化与资源调度;三是数据版权与许可的合规性管理,需协调原始DataComp数据的CC-BY-4.0协议与苹果自有许可。这些挑战的应对体现了大规模增强数据集构建的技术复杂性。
常用场景
经典使用场景
在视觉-语言预训练领域,DataCompDR-1B数据集通过其增强的元数据架构,为多模态模型的高效训练提供了典范。该数据集的核心应用场景在于支撑对比性语言-图像预训练(CLIP)模型的快速迭代与优化,尤其适用于资源受限的研究环境。其经典使用方式体现在利用合成标题、图像增强嵌入以及教师模型生成的文本嵌入,构建一个强化训练三元组,从而在有限计算预算下显著提升模型的学习效率与泛化性能。
解决学术问题
该数据集有效应对了大规模多模态预训练中数据质量参差与计算成本高昂的学术挑战。通过引入多模态数据集强化策略,DataCompDR-1B解决了原始数据中标题噪声与语义稀疏性问题,同时通过预计算嵌入大幅降低了训练时的前向传播开销。其意义在于为社区提供了一种可复现的高效训练范式,使得在单节点GPU集群上也能实现接近前沿的零样本分类性能,推动了视觉-语言对齐研究在计算可及性方面的进步。
实际应用
在实际部署中,DataCompDR-1B为移动端与边缘设备的轻量级视觉-语言模型开发提供了关键数据支持。基于该数据集训练的模型,如MobileCLIP,能够高效地服务于图像检索、跨模态内容理解以及实时视觉问答等应用场景。其预计算嵌入机制使得模型在资源受限环境下仍能保持高精度,促进了智能摄影、辅助驾驶以及增强现实等领域中多模态交互技术的落地与普及。
数据集最近研究
最新研究方向
在视觉-语言多模态学习领域,DataCompDR-1B数据集凭借其强化合成元数据机制,正推动高效训练范式的革新。该数据集通过集成合成描述与增强嵌入,显著提升了模型在有限计算资源下的学习效率,成为轻量化多模态模型(如MobileCLIP)研发的关键支撑。前沿研究聚焦于利用此类强化数据优化跨模态对齐,探索在移动设备上部署高性能图像-文本模型的可行路径,同时为减少大规模预训练对计算资源的依赖提供了新思路。其影响延伸至边缘智能应用,促进了高效多模态学习在实际场景中的落地与普及。
以上内容由遇见数据集搜集并总结生成


