healthqa-br
收藏Hugging Face2025-06-18 更新2025-06-19 收录
下载链接:
https://huggingface.co/datasets/Larxel/healthqa-br
下载链接
链接失效反馈官方服务:
资源简介:
HealthQA-BR是一个大规模、全面的基准测试数据集,旨在评估大型语言模型在巴西卫生系统(特别是统一卫生系统SUS)中的临床知识。它由5632个多项选择题组成,这些题目来自全国性的专业执照考试和住院医师培训竞赛,涵盖了各种医学专业和卫生领域。数据集以Apache Parquet格式提供,并包含丰富的元数据,以便进行细粒度分析。README还讨论了数据集的创建过程、潜在的偏见、风险和局限性,并提供了使用建议。它强调高准确性不应被解释为临床准备就绪,并鼓励用户专注于识别和解决特定的知识差距。
创建时间:
2025-06-16
原始信息汇总
HealthQA-BR 数据集概述
基本信息
- 名称: HealthQA-BR
- 许可证: Creative Commons Attribution 4.0 Generic License (
cc-by-4.0) - 任务类别: 问答
- 语言: 葡萄牙语 (pt-BR)
- 标签: 医疗保健、医学、护理、心理学、牙科、社会工作、专业考试
- 规模: 1K<n<10K
数据集描述
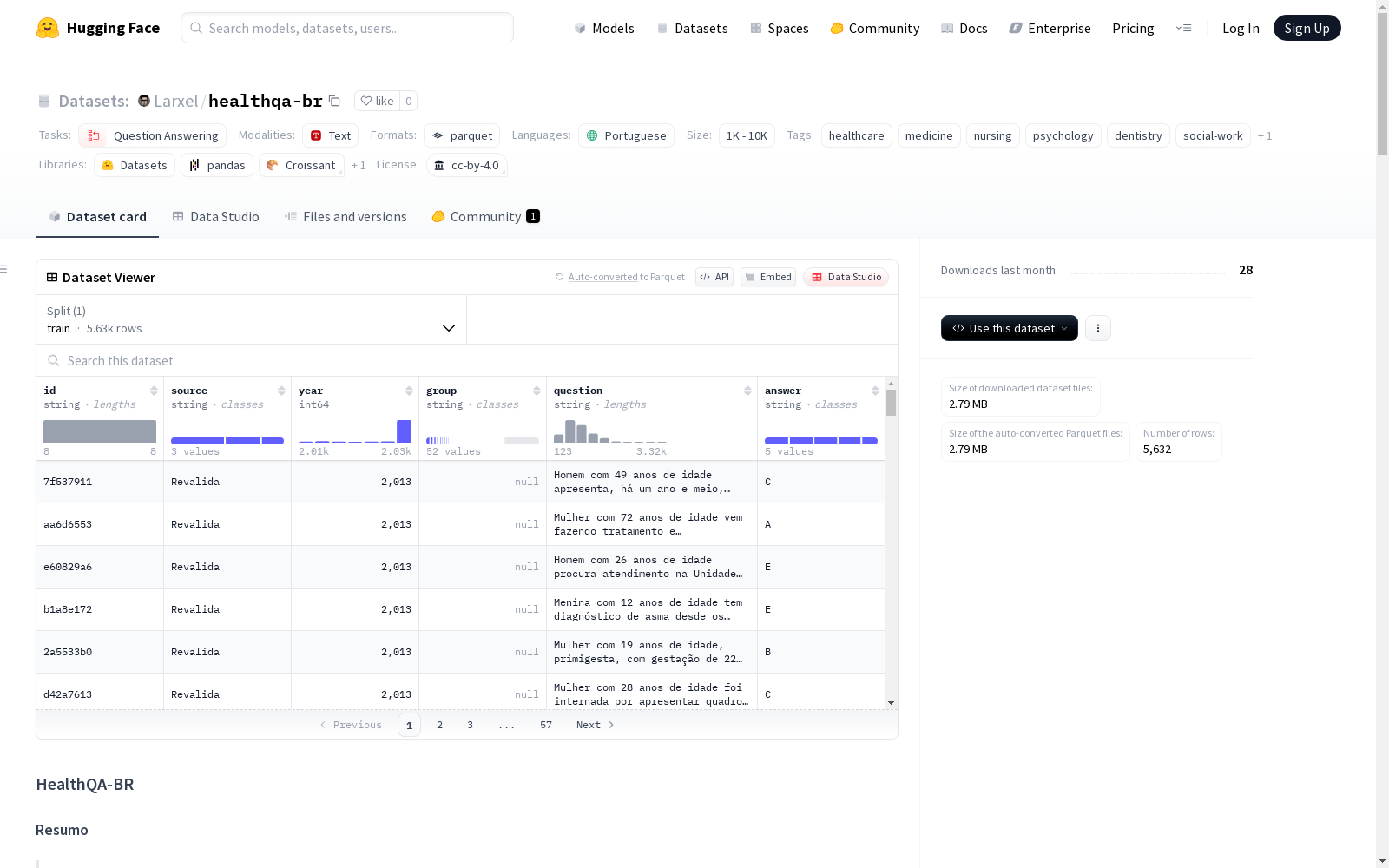
- 简介: HealthQA-BR 是首个针对巴西统一卫生系统 (SUS) 的大规模综合基准测试,旨在评估大型语言模型 (LLMs) 在巴西公共卫生挑战中的临床知识。数据集包含 5,632 道选择题,来源于巴西国家级专业资格考试和住院医师考试。
- 特点: 数据集不仅涵盖医学专业,还包括护理、牙科、心理学、社会工作、药学、物理治疗等多个健康领域,反映了巴西卫生系统的跨专业现实。
数据集结构
- 格式: Apache Parquet
- 字段:
id: 8字符唯一键source: 问题来源 (Revalida,Enare Residência Médica,Enare Multiprofissional)year: 考试年份 (2011 - 2025)group: 专业或健康领域 (如Cardiologia,Enfermagem,Serviço social)question: 问题文本及选项 (选项为 "A", "B", "C", "D", "E")answer: 正确答案选项
数据组成
| 来源 | 描述 | 问题数量 |
|---|---|---|
| Revalida | 针对国外毕业医生的执照考试 | 1,777 |
| Enare - Médica | 针对医生的住院医师考试 | 2,691 |
| Enare - Multiprofissional | 针对多专业健康人员的住院医师考试 | 1,164 |
| 总计 | 5,632 |
创建过程
- 数据来源: 巴西国家级公开考试 (Revalida 和 Enare)
- 处理步骤:
- 从公开PDF文档中自动提取问题
- 与官方答案核对并验证
- 去重处理 (精确去重和语义相似度去重)
- 元数据标记
- 质量审核 (1.5%样本手动审核)
限制与风险
- 地理偏差: 数据集专为巴西卫生系统设计,可能不适用于其他国家
- 方法限制: 基于选择题格式和准确率指标,不能全面评估LLMs在复杂临床工作流程中的能力
推荐用途
建议利用详细的元数据进行专业和健康领域的细分分析,而非依赖单一总体准确率得分。
引用
Vancouver格式: Daddario AMV. HealthQA-BR: A System-Wide Benchmark Reveals Critical Knowledge Gaps in Large Language Models. arXiv [Preprint]. 2025.
BibTeX格式: bibtex @article{daddario2025healthqabr, title={{HealthQA-BR: A System-Wide Benchmark Reveals Critical Knowledge Gaps in Large Language Models}}, author={Daddario, Andrew Maranhão Ventura}, journal={arXiv preprint}, year={2025}, note={数据集和评估代码公开于: https://huggingface.co/datasets/Larxel/healthqa-br} }
搜集汇总
数据集介绍
构建方式
HealthQA-BR数据集的构建过程体现了严谨的科学态度与系统化设计理念。研究团队从巴西国家统一医疗系统(SUS)的实际需求出发,通过多阶段流程精心构建这一专业基准测试工具。数据来源覆盖了巴西国家医师资格认证考试(Revalida)和国家住院医师考试(Enare)的公开题库,采用自动化解析与人工审核相结合的方式,确保5632道选择题的质量与准确性。特别值得注意的是,数据集经过专业级的去重处理,包括精确匹配和语义相似度双重检测,并由领域专家进行最终校验,形成了涵盖30余个医疗专业的完整知识体系。
特点
该数据集最显著的特点是专注于巴西公共卫生体系的专业评估需求。不同于常见的医学问答数据集,它不仅包含传统临床医学内容,更创新性地整合了护理、牙科、心理学、社会工作等多学科专业领域,真实反映了巴西医疗系统的跨专业协作特点。数据集采用Apache Parquet格式存储,每个条目包含完整的问题文本、五个选项、正确答案及丰富的元数据,支持从考试来源、年份到具体专业领域的多维度分析。这种精细的结构设计使其成为评估AI模型在复杂医疗场景下知识掌握程度的理想工具。
使用方法
在使用HealthQA-BR数据集时,研究人员可通过HuggingFace平台直接获取Parquet格式的数据文件。建议使用者充分利用数据集提供的元数据信息,按照不同医疗专业或考试类型进行分层分析,而非仅关注整体准确率指标。该数据集特别适合用于评估大型语言模型在巴西医疗语境下的知识掌握程度,可作为模型微调或知识补全的基准测试工具。需要注意的是,由于数据集具有鲜明的巴西公共卫生体系特征,在跨地域应用时需考虑其特定的流行病学和文化背景因素。
背景与挑战
背景概述
HealthQA-BR数据集是首个针对巴西统一医疗系统(SUS)的大规模综合性基准测试,旨在评估大型语言模型(LLM)在巴西公共卫生挑战中的临床知识水平。该数据集由5,632道多选题组成,源自巴西全国性专业资格考试和住院医师考试,涵盖了医学、护理、牙科、心理学、社会工作等多个健康领域。由Andrew Maranhão Ventura D'addario主导,并得到巴西卫生部、国家科学技术发展委员会和盖茨基金会的支持,该数据集填补了非英语医疗评估工具的空白,为巴西本土医疗AI的发展提供了重要基准。
当前挑战
HealthQA-BR数据集面临的主要挑战包括:1) 领域问题方面,该数据集旨在解决多专业医疗知识评估的复杂性,特别是在巴西公共卫生系统的独特背景下,如何准确衡量LLM在跨学科团队协作中的表现;2) 构建过程中,数据集需要克服多源异构数据的整合难题,包括从不同格式的PDF文档中精确提取题目、确保与官方答案的一致性,以及通过高级去重技术消除重复或近似题目。此外,数据集还需平衡各专业领域的代表性,以反映巴西医疗系统的实际需求。
常用场景
经典使用场景
在医疗人工智能研究领域,HealthQA-BR数据集为评估大型语言模型在巴西统一医疗系统(SUS)环境下的临床知识水平提供了标准化测试平台。该数据集通过5632道涵盖医学、护理、牙科等多专业的选择题,系统性地检验模型对巴西公共卫生挑战的理解深度,特别是在跨专业协作场景中的表现。
实际应用
在实际医疗场景中,该数据集可指导开发适用于巴西基层医疗的智能辅助系统。医疗机构可依据模型在不同专业领域的表现分数,针对性部署AI分诊助手或继续教育工具。其包含的全国性执业考试真题,特别适合用于培训即将进入巴西医疗体系的从业人员。
衍生相关工作
基于该数据集已催生多项重要研究,包括跨专业医疗知识迁移学习框架、葡萄牙语临床语言模型微调技术等。其中最具代表性的是采用分层评估策略的工作,通过分析模型在Revalida和ENARE等子测试的表现差异,揭示了专业领域知识转移的规律性特征。
以上内容由遇见数据集搜集并总结生成


