ViInfographicsVQA
收藏Hugging Face2025-03-30 更新2025-03-31 收录
下载链接:
https://huggingface.co/datasets/Namronaldo2004/ViInfographicsVQA
下载链接
链接失效反馈官方服务:
资源简介:
ViInfographicsVQA是一个基于越南语infographic的视觉问答数据集,包含了图片、问题、答案、解释和问题类型等信息。数据集旨在用于训练和评估视觉问答系统,支持多种类型的问答任务。
创建时间:
2025-03-30
原始信息汇总
ViInfographicsVQA数据集概述
数据集基本信息
- 名称: ViInfographicsVQA
- 类型: 越南语视觉问答(VQA)数据集
- 语言: 越南语
- 许可证: Apache 2.0
- 开发者: @Namronaldo2004, @Kiet2302, @Mels22, @JoeCao
数据来源
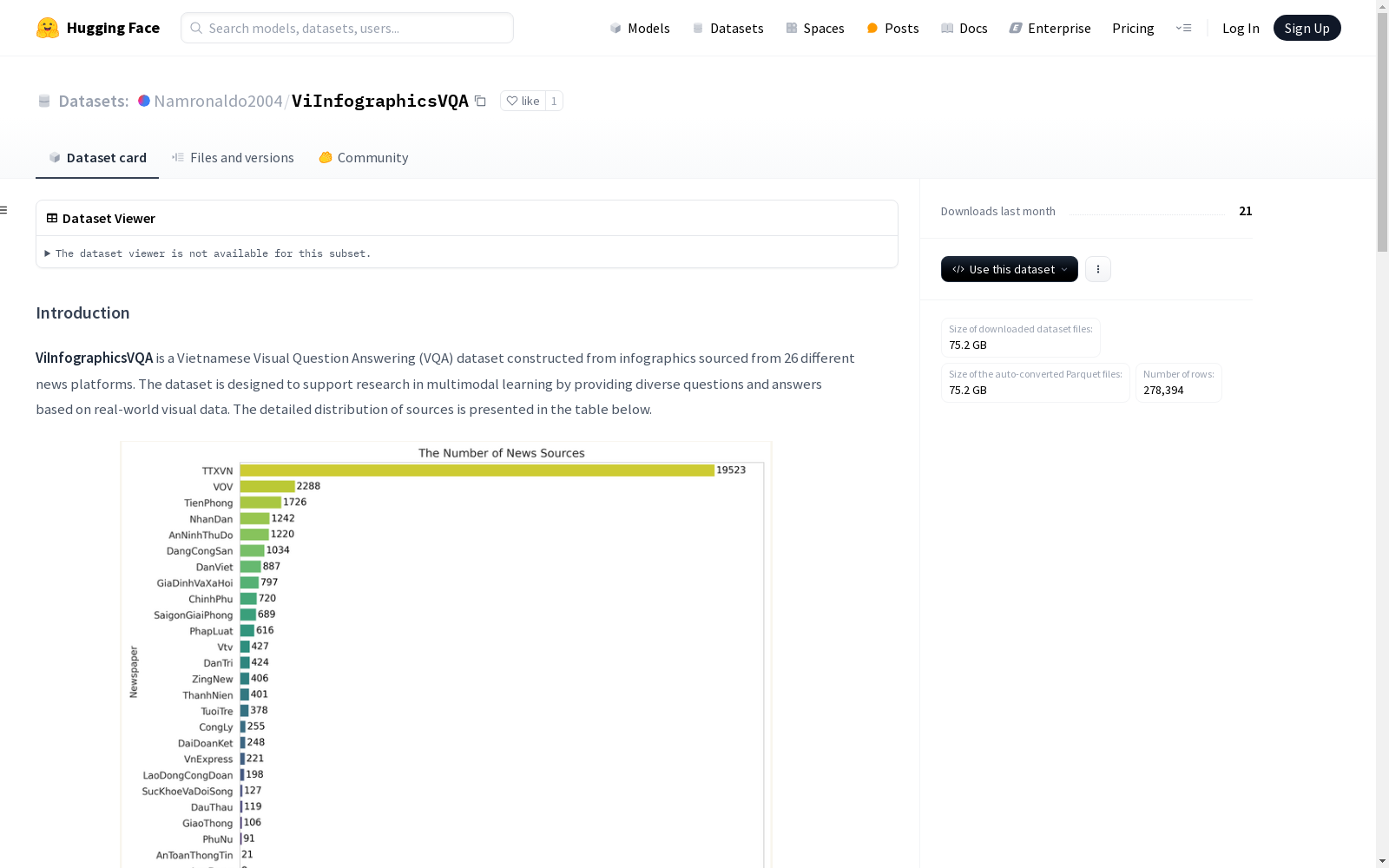
- 从26个不同新闻平台的信息图表中构建。
数据集结构
特征
- image: 图像
- question: 问题
- answer: 答案
- explanation: 解释
- type: 问题类型
数据分割
- 训练集: 20部分(train_part1至train_part20),共100,000个示例(train_part20为2,306个示例)
- 验证集: 3部分(val_part1至val_part3),共13,890个示例
- 测试集: 6部分(test_part1至test_part6),共28,001个示例
数据集大小
- 下载大小: 122,545,172,839字节
- 数据集大小: 152,137,946,434.784字节
数据分类
- Text QA: 基于文本信息的问题
- Non-text QA: 不依赖文本信息的问题
规则与约束
问题生成规则
- 每张图像生成约5个问题(3个Text QA和2个Non-text QA)
- 问题和答案不超过30个单词
问题约束
- 避免是/非问题和选择性问题
- 不涉及深度分析或超出信息图表数据的推断
- 确保问题有足够的数据支持
答案约束
- 答案应为完整句子
- 包含清晰的解释(不超过100字)
数据构建流程
- 严格遵循预定义的构建流程
搜集汇总
数据集介绍
构建方式
ViInfographicsVQA数据集基于26个新闻平台的信息图表构建而成,旨在支持多模态学习研究。构建过程中严格遵循预设规则,每张图像生成约5个问答对,包括3个文本相关问题和2个非文本问题。问题与答案长度均控制在30词以内,并避免使用是非题或深度推理问题。数据采集流程经过精心设计,确保问答对与视觉内容高度相关,且每个答案均附有详细的解释说明。
特点
该数据集以越南语信息图表为核心,涵盖丰富的视觉问答场景。其显著特点在于对问题类型的精细分类,将每个问答划分为文本类和非文本类,便于针对性研究。数据集包含超过10万条样本,每一条数据均包含图像、问题、答案、解释和类型标注,结构清晰完整。信息图表来源多样,确保了数据分布的广泛性和代表性,为多模态理解提供了优质的研究素材。
使用方法
使用ViInfographicsVQA时,可通过HuggingFace平台加载分块数据,包括训练集、验证集和测试集。数据以图像-文本对形式组织,支持端到端的视觉问答模型训练。研究人员可根据'type'字段筛选特定类别的问题进行专项分析,或利用'explanation'字段增强模型的可解释性。该数据集特别适合用于测试模型在跨模态理解、越南语处理以及复杂视觉场景推理等方面的能力。
背景与挑战
背景概述
ViInfographicsVQA数据集是专为越南语视觉问答(VQA)研究设计的多模态数据集,由来自26个不同新闻平台的信息图表构建而成。该数据集由Namronaldo2004、Kiet2302、Mels22和JoeCao等研究人员开发,旨在通过真实世界视觉数据支持多模态学习研究。数据集包含丰富的问答对,涵盖文本和非文本两类问题,为越南语自然语言处理与计算机视觉的交叉研究提供了重要资源。其Apache 2.0许可促进了学术界的广泛使用,对推动东南亚语言的多模态理解具有重要意义。
当前挑战
ViInfographicsVQA数据集面临的核心挑战包括多模态对齐的复杂性,即如何有效融合越南语文本信息与视觉元素。构建过程中的挑战体现在数据采集的多样性控制,需平衡26个新闻平台的风格差异;问答对标注需严格遵守5个问题/图的规则,其中3个文本问题和2个非文本问题的比例控制增加了标注复杂度。问题设计需规避是非题和深度推理问题,同时确保答案可从图表直接推导,这对标注人员的专业素养提出了较高要求。
常用场景
经典使用场景
ViInfographicsVQA数据集在视觉问答领域具有重要价值,尤其适用于越南语环境下的多模态学习研究。该数据集通过结合新闻平台的信息图表,构建了丰富的视觉和文本问答对,为研究者提供了真实场景下的多模态数据。在经典使用场景中,该数据集常被用于训练和评估视觉问答模型,特别是在处理越南语文本和视觉信息的联合理解任务中表现出色。
解决学术问题
ViInfographicsVQA数据集解决了多模态学习中的关键问题,尤其是在越南语环境下缺乏高质量视觉问答数据的问题。通过提供多样化的问答对和详细的解释,该数据集为研究者提供了研究视觉与文本联合理解的实验基础。其意义在于填补了越南语多模态数据集的空白,推动了跨语言视觉问答研究的发展。
衍生相关工作
ViInfographicsVQA数据集衍生了许多相关研究,尤其是在多模态学习和视觉问答领域。基于该数据集,研究者开发了多种先进的视觉问答模型,如基于Transformer的多模态融合模型和跨语言视觉问答系统。这些工作不仅提升了模型在越南语环境下的表现,还为其他低资源语言的视觉问答研究提供了借鉴。
以上内容由遇见数据集搜集并总结生成


