Julian2002/pdp4k
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/Julian2002/pdp4k
下载链接
链接失效反馈官方服务:
资源简介:
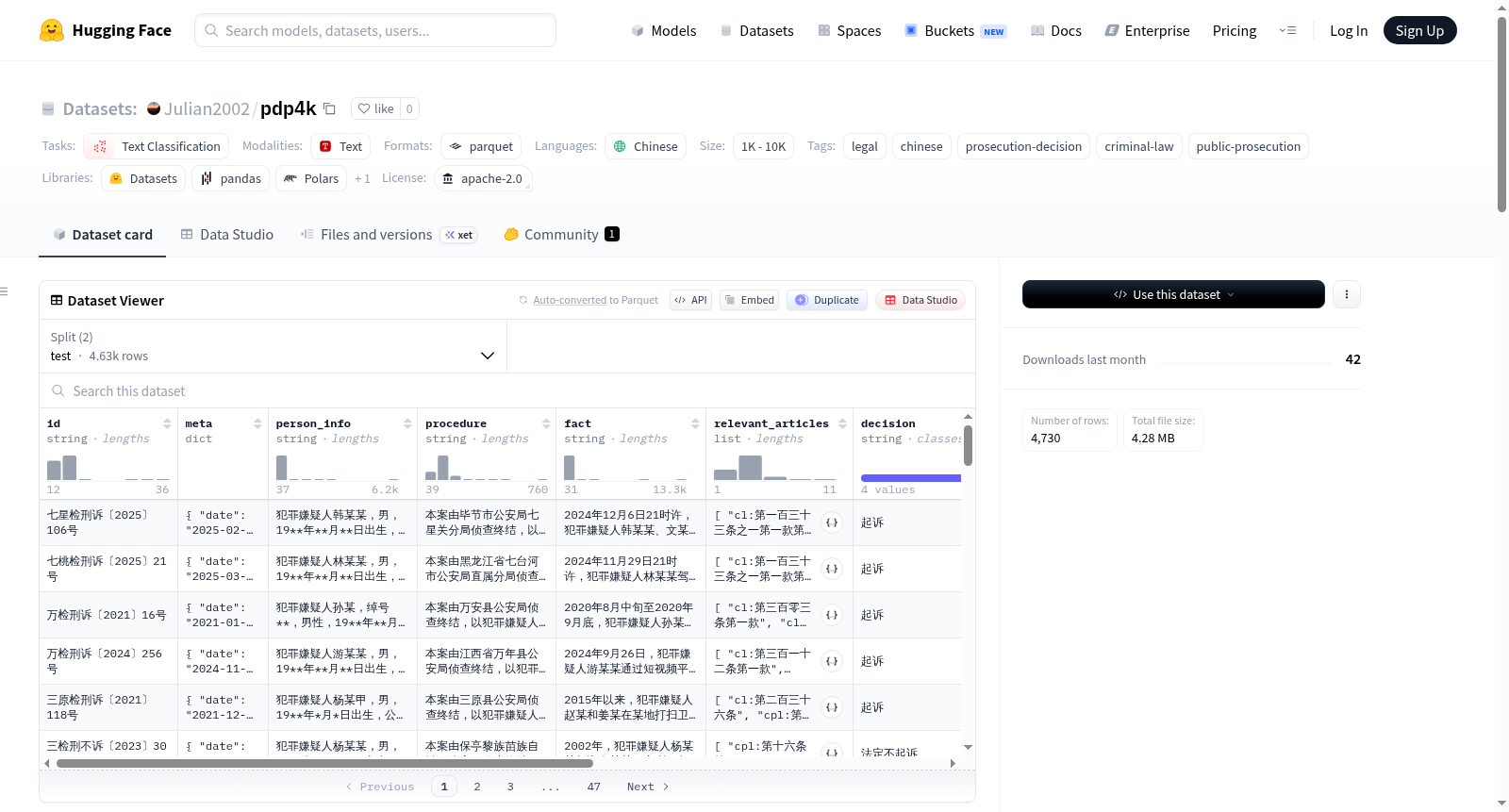
PDP-4K 是一个中文检察机关公诉决定预测数据集,包含 4,730 条结构化检察文书样本。数据集的任务是给定犯罪嫌疑人信息、案件程序和案件事实,预测适用法条和公诉决定。适用法条使用 `cl:`、`cpl:`、`cpr:` 等前缀标识法律来源,公诉决定为四分类标签,包括起诉、相对不起诉、法定不起诉、存疑不起诉。数据集的结构包括多个字段,如id、meta、person_info、procedure、fact、relevant_articles、decision等。数据集还提供了详细的标签说明和注意事项,用于法律 NLP 研究与模型评测,不构成法律意见。
PDP-4K is a Chinese prosecution decision prediction dataset containing 4,730 structured prosecution document samples. The task of the dataset is to predict applicable legal articles and prosecution decisions given suspect information, case procedures, and case facts. The applicable legal articles are identified using prefixes such as `cl:`, `cpl:`, and `cpr:`, and the prosecution decisions are four-class labels including prosecution, relative non-prosecution, statutory non-prosecution, and doubtful non-prosecution. The dataset structure includes multiple fields such as id, meta, person_info, procedure, fact, relevant_articles, decision, etc. The dataset also provides detailed label descriptions and precautions for legal NLP research and model evaluation, and does not constitute legal advice.
提供机构:
Julian2002
搜集汇总
数据集介绍
构建方式
PDP-4K数据集源于对中国检察机关公开法律文书的系统采集与结构化处理,共涵盖4730条分布于全国31个省级行政区的检察文书样本。数据构建过程中,研究团队从原始文书中提取犯罪嫌疑人信息、案件程序、案件事实等关键维度,并依据《中华人民共和国刑法》《刑事诉讼法》等法律体系,以‘cl:’、‘cpl:’、‘cpr:’等前缀为法条进行精细化标注。公诉决定被划分为起诉、相对不起诉、法定不起诉、存疑不起诉四类,所有样本均附带来源URL以确保可溯源性。
特点
该数据集以公诉决定预测为核心任务,具备多层次结构化特征,包括人员信息、程序描述、事实文本以及15,013条法条标注,展现出高度的法律领域专业性。其独特的标签体系精准映射了中国刑事司法实践中四种公诉情形,test_rq2子集按类别均匀分布(各25例),为公平性评测提供基准。此外,数据覆盖2014年至2026年间的文书,包含31个省级地区,尤以内蒙古、山西、云南样本量最为丰富,体现了地域多样性与时间跨度。
使用方法
PDP-4K当前仅开放测试集,适于零样本学习、提示工程、上下文学习及模型评测任务。研究人员可将person_info、procedure、fact字段作为模型输入,令模型预测relevant_articles与decision两个目标变量,其中decision为四分类标签。数据集以标准格式加载,支持直接通过HuggingFace Datasets库进行调用,适用于法律文本挖掘与司法智能化辅助系统的性能评估。
背景与挑战
背景概述
PDP-4K数据集创建于2024年,由国内法律人工智能研究机构开发,旨在推动中文司法文书智能处理领域的发展。该数据集聚焦于检察机关公诉决定预测这一核心研究问题,通过结构化整合4730条真实检察文书样本,覆盖31个省级地区,时间跨度自2014年至2026年。在司法信息化建设与智慧检务快速推进的背景下,PDP-4K为法律NLP模型在罪名适用、程序处理与公诉决策方面的能力评估提供了标准化基准,对提升司法领域文本理解和预测技术具有重要影响。
当前挑战
数据集所解决的领域问题为司法文本中的公诉决定预测,其挑战包括:一是案件事实与法律条文间的复杂映射关系,模型需从非结构化文本中准确识罪并匹配法条;二是公诉决定类别分布极度不均衡(起诉样本占86.6%),易导致模型偏向多数类。在构建过程中,面临的挑战有:原始检察文书中涉及大量敏感个人信息,需在脱敏处理与保持语义完整性间取得平衡;多源数据的时间跨度与地域差异增加了数据清洗和标准化难度;法条标注需同时识别刑法、刑事诉讼法等多部法律体系,标注一致性要求极高。
常用场景
经典使用场景
在智慧司法与法律人工智能的交叉领域中,PDP-4K数据集为检察机关公诉决定预测任务提供了高质量的结构化语料。研究者通常基于犯罪嫌疑人信息、案件程序及案件事实,构建多任务学习模型以同时预测适用法条与四分类公诉决定,包括起诉、相对不起诉、法定不起诉及存疑不起诉。该数据集凭借其精细的标签体系和丰富的文本特征,成为验证法律文本理解与推理能力的基准平台,尤其在零样本学习与上下文学习范式下展现出独特价值。
衍生相关工作
基于PDP-4K衍生的工作主要聚焦于法律专用大语言模型的评测与微调,研究者利用其构建了兼具判别性与生成性的司法智能体,探索通过在Prompt中注入法条知识来增强预测准确性。该数据集也催生了针对不均衡分类问题的分层学习框架,以及融合外部法律知识图谱的增强推理方法。部分工作进一步将其扩展为跨任务基准,支持法条预测、决定分类与案情摘要的联合优化,推动了法律NLP从单任务范式向多任务协同的转型。
数据集最近研究
最新研究方向
在智慧司法与法律人工智能的浪潮中,PDP-4K数据集为中文检察机关公诉决定预测这一前沿课题奠定了关键基准。该数据集聚焦于给定犯罪嫌疑人信息、案件程序与事实后,联合预测所涉法条与四分类公诉决定(起诉、相对不起诉、法定不起诉、存疑不起诉),其结构化字段与31个省级行政区的广泛覆盖,使其成为探索法律文本零样本学习、提示工程及上下文学习的理想实验场。当前研究正围绕如何利用该数据集模拟复杂司法推理,推动模型在兼具精细化与稳健性的法律决策中逼近真实检察官的裁量逻辑,尤其是在证据不足、情节轻微等边缘案例上的判别能力,从而为司法辅助系统的可信性与可解释性提供突破性支撑。
以上内容由遇见数据集搜集并总结生成


