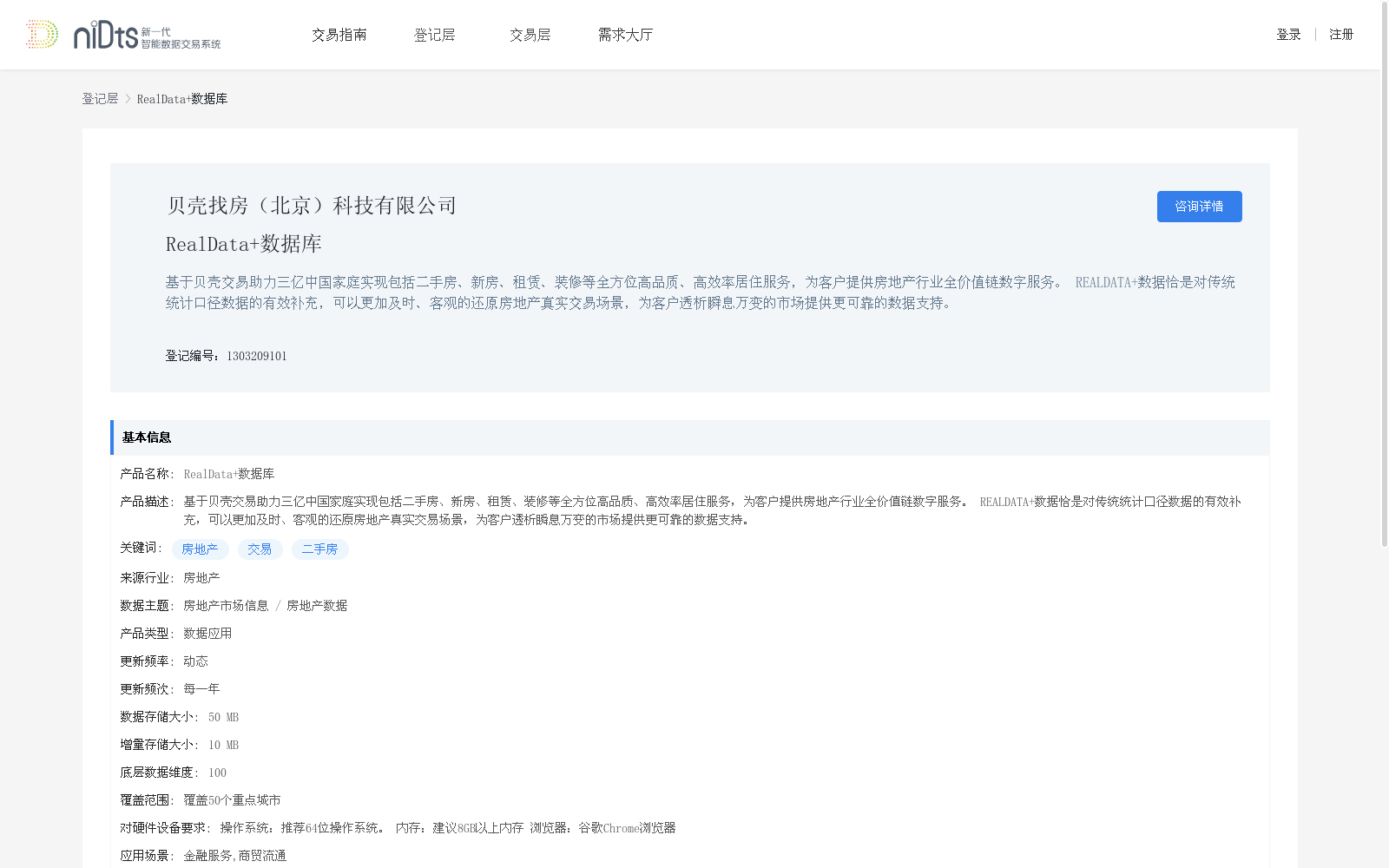
RealData+数据库
收藏上海数据交易所2023-04-12 更新2026-03-21 收录
下载链接:
https://nidts.chinadep.com/reg-hall/product-detail?id=1343
下载链接
链接失效反馈官方服务:
资源简介:
基于贝壳交易助力三亿中国家庭实现包括二手房、新房、租赁、装修等全方位高品质、高效率居住服务,为客户提供房地产行业全价值链数字服务。
REALDATA+数据恰是对传统统计口径数据的有效补充,可以更加及时、客观的还原房地产真实交易场景,为客户透析瞬息万变的市场提供更可靠的数据支持。
Powered by Beike Transactions, it helps 300 million Chinese households access comprehensive high-quality and efficient residential services covering second-hand housing, newly-built housing, rental services and home decoration, and provides customers with digital services spanning the entire value chain of the real estate industry. REALDATA+ data is an effective supplement to traditional statistical caliber data, which can more timely and objectively restore real real estate transaction scenarios, and provide more reliable data support for customers to gain in-depth insights into the rapidly changing market.
提供机构:
贝壳找房(北京)科技有限公司
创建时间:
2023-04-12
搜集汇总
数据集介绍
背景与挑战
背景概述
RealData+数据库是由贝壳找房提供的房地产行业数据集,覆盖50个重点城市,包含二手房、新房、租赁和装修等交易数据,适用于金融服务和商贸流通场景。
以上内容由遇见数据集搜集并总结生成


