110-PT-BN-KP
收藏github2024-05-23 更新2024-05-31 收录
下载链接:
https://github.com/LIAAD/KeywordExtractor-Datasets
下载链接
链接失效反馈官方服务:
资源简介:
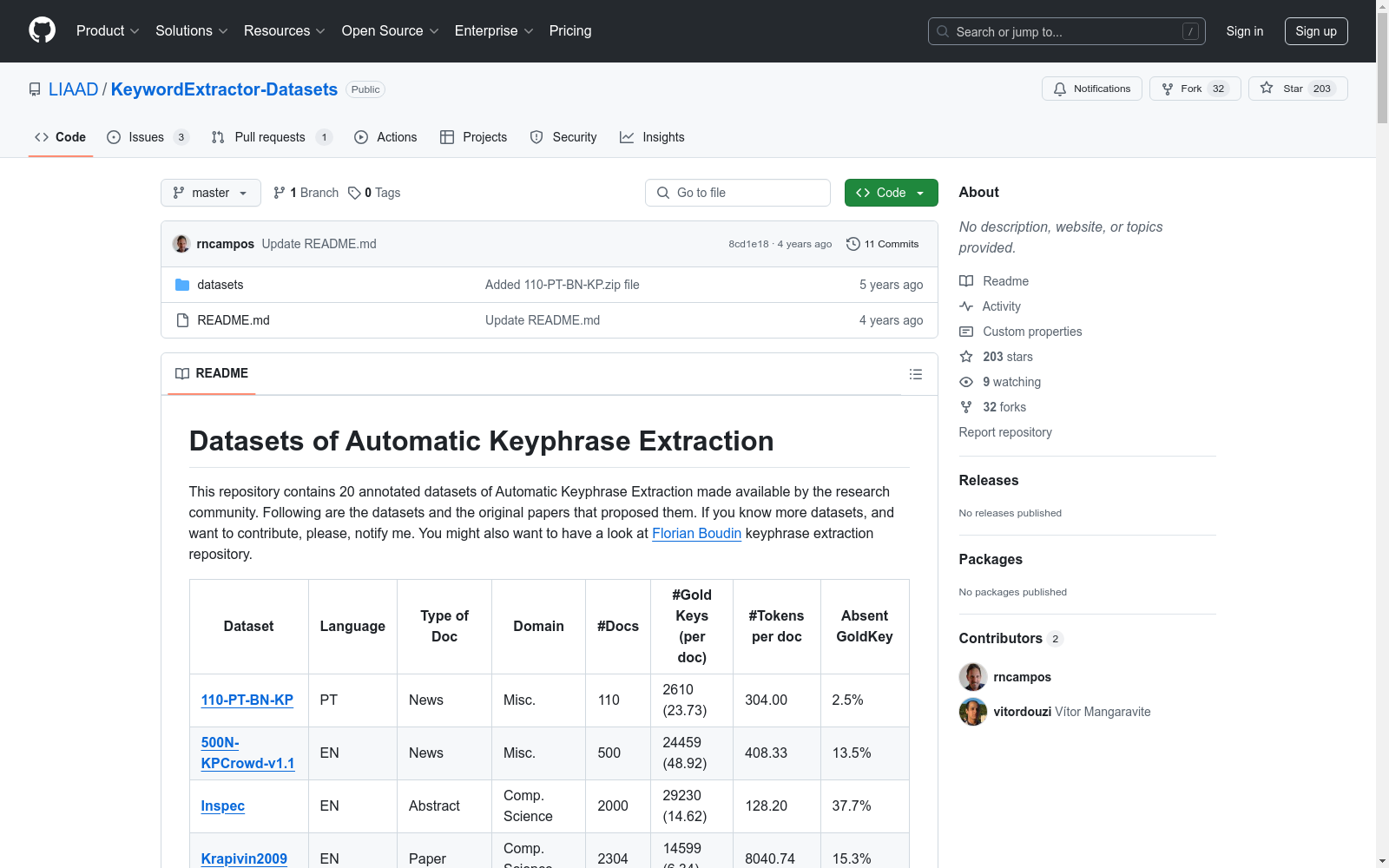
110-PT-BN-KP数据集是葡萄牙语新闻数据集,包含110篇文档,每篇文档平均有2610个关键词(平均23.73个关键词/文档),文档平均长度为304个词,其中2.5%的关键词在文档中未出现。
The 110-PT-BN-KP dataset is a Portuguese news dataset comprising 110 documents. Each document contains an average of 2610 keywords (approximately 23.73 keywords per document), with an average document length of 304 words. Notably, 2.5% of the keywords do not appear within the documents.
创建时间:
2018-11-05
原始信息汇总
数据集概述
110-PT-BN-KP
- 语言: 葡萄牙语 (PT)
- 类型: 新闻
- 领域: 杂项
- 文档数量: 110
- 黄金关键词数量: 2610 (平均每文档23.73个)
- 每文档平均词数: 304.00
- 缺失黄金关键词比例: 2.5%
500N-KPCrowd-v1.1
- 语言: 英语 (EN)
- 类型: 新闻
- 领域: 杂项
- 文档数量: 500
- 黄金关键词数量: 24459 (平均每文档48.92个)
- 每文档平均词数: 408.33
- 缺失黄金关键词比例: 13.5%
Inspec
- 语言: 英语 (EN)
- 类型: 摘要
- 领域: 计算机科学
- 文档数量: 2000
- 黄金关键词数量: 29230 (平均每文档14.62个)
- 每文档平均词数: 128.20
- 缺失黄金关键词比例: 37.7%
Krapivin2009
- 语言: 英语 (EN)
- 类型: 论文
- 领域: 计算机科学
- 文档数量: 2304
- 黄金关键词数量: 14599 (平均每文档6.34个)
- 每文档平均词数: 8040.74
- 缺失黄金关键词比例: 15.3%
Nguyen2007
- 语言: 英语 (EN)
- 类型: 论文
- 领域: 计算机科学
- 文档数量: 209
- 黄金关键词数量: 2369 (平均每文档11.33个)
- 每文档平均词数: 5201.09
- 缺失黄金关键词比例: 17.8%
PubMed
- 语言: 英语 (EN)
- 类型: 论文
- 领域: 计算机科学
- 文档数量: 500
- 黄金关键词数量: 7620 (平均每文档15.24个)
- 每文档平均词数: 3992.78
- 缺失黄金关键词比例: 60.2%
Schutz2008
- 语言: 英语 (EN)
- 类型: 论文
- 领域: 计算机科学
- 文档数量: 1231
- 黄金关键词数量: 55013 (平均每文档44.69个)
- 每文档平均词数: 3901.31
- 缺失黄金关键词比例: 13.6%
SemEval2010
- 语言: 英语 (EN)
- 类型: 论文
- 领域: 计算机科学
- 文档数量: 243
- 黄金关键词数量: 4002 (平均每文档16.47个)
- 每文档平均词数: 8332.34
- 缺失黄金关键词比例: 11.3%
SemEval2017
- 语言: 英语 (EN)
- 类型: 段落
- 领域: 杂项
- 文档数量: 493
- 黄金关键词数量: 8969 (平均每文档18.19个)
- 每文档平均词数: 178.22
- 缺失黄金关键词比例: 0.0%
WikiNews
- 语言: 法语 (FR)
- 类型: 新闻
- 领域: 杂项
- 文档数量: 100
- 黄金关键词数量: 1177 (平均每文档11.77个)
- 每文档平均词数: 293.52
- 缺失黄金关键词比例: 5.0%
cacic
- 语言: 西班牙语 (ES)
- 类型: 论文
- 领域: 计算机科学
- 文档数量: 888
- 黄金关键词数量: 4282 (平均每文档4.82个)
- 每文档平均词数: 3985.84
- 缺失黄金关键词比例: 2.2%
citeulike180
- 语言: 英语 (EN)
- 类型: 论文
- 领域: 杂项
- 文档数量: 183
- 黄金关键词数量: 3370 (平均每文档18.42个)
- 每文档平均词数: 4796.08
- 缺失黄金关键词比例: 32.2%
fao30
- 语言: 英语 (EN)
- 类型: 论文
- 领域: 农业
- 文档数量: 30
- 黄金关键词数量: 997 (平均每文档33.23个)
- 每文档平均词数: 4777.70
- 缺失黄金关键词比例: 41.7%
fao780
- 语言: 英语 (EN)
- 类型: 论文
- 领域: 农业
- 文档数量: 779
- 黄金关键词数量: 6990 (平均每文档8.97个)
- 每文档平均词数: 4971.79
- 缺失黄金关键词比例: 36.1%
kdd
- 语言: 英语 (EN)
- 类型: 论文
- 领域: 计算机科学
- 文档数量: 755
- 黄金关键词数量: 3831 (平均每文档5.07个)
- 每文档平均词数: 75.97
- 缺失黄金关键词比例: 53.2%
pak2018
- 语言: 波兰语 (PL)
- 类型: 摘要
- 领域: 杂项
- 文档数量: 50
- 黄金关键词数量: 232 (平均每文档4.64个)
- 每文档平均词数: 97.36
- 缺失黄金关键词比例: 64.7%
theses100
- 语言: 英语 (EN)
- 类型: 硕士/博士论文
- 领域: 杂项
- 文档数量: 100
- 黄金关键词数量: 767 (平均每文档7.67个)
- 每文档平均词数: 4728.86
- 缺失黄金关键词比例: 47.6%
wicc
- 语言: 西班牙语 (ES)
- 类型: 论文
- 领域: 计算机科学
- 文档数量: 1640
- 黄金关键词数量: 7498 (平均每文档4.57个)
- 每文档平均词数: 1955.56
- 缺失黄金关键词比例: 2.7%
wiki20
- 语言: 英语 (EN)
- 类型: 研究报告
- 领域: 计算机科学
- 文档数量: 20
- 黄金关键词数量: 730 (平均每文档36.50个)
- 每文档平均词数: 6177.65
- 缺失黄金关键词比例: 51.8%
www
- 语言: 英语 (EN)
- 类型: 论文
- 领域: 计算机科学
- 文档数量: 1330
- 黄金关键词数量: 7711 (平均每文档5.80个)
- 每文档平均词数: 84.08
- 缺失黄金关键词比例: 55.0%
搜集汇总
数据集介绍
构建方式
110-PT-BN-KP数据集源自欧洲葡萄牙ALERT BN数据库中的8个广播新闻节目,涵盖政治、体育、财经等多个领域。该数据集包含110个转录文本文档,每个文档经过语音转文字后,由专业人员手动校正分段错误,并由一名标注者提取总结文档内容的关键词。这种构建方式确保了数据集的高质量和准确性,为自动关键词提取研究提供了可靠的基础。
特点
110-PT-BN-KP数据集的主要特点在于其多样性和专业性。首先,数据集涵盖了多个新闻领域,确保了样本的广泛代表性。其次,每个文档的关键词由专业人员手动标注,保证了关键词的高质量。此外,数据集中的关键词缺失率仅为2.5%,显示了其标注的完整性和一致性。这些特点使得该数据集在自动关键词提取研究中具有重要的应用价值。
使用方法
110-PT-BN-KP数据集适用于多种自动关键词提取算法的训练和评估。研究者可以通过加载数据集中的文档和对应的关键词,进行模型训练和性能测试。此外,该数据集还可用于跨语言关键词提取研究,特别是针对葡萄牙语和多语言环境下的关键词提取任务。通过对比不同算法在该数据集上的表现,研究者可以进一步优化和验证其关键词提取模型。
背景与挑战
背景概述
110-PT-BN-KP数据集是由欧洲葡萄牙语广播新闻数据库中的110个转录文本文档组成,涵盖政治、体育、财经等多个领域。该数据集由主要研究人员通过众包方式创建,旨在解决新闻故事的关键短语提取问题。通过语音转文本技术生成初步文本后,每个新闻文档都经过手动校正以修复分段错误,并由一名标注者提取总结文档内容的关键词。这一数据集的创建不仅丰富了自动关键短语提取领域的资源,还为相关研究提供了宝贵的数据支持。
当前挑战
110-PT-BN-KP数据集在构建过程中面临的主要挑战包括:首先,语音转文本技术生成的初步文本存在分段错误,需要大量手动校正,这增加了数据处理的复杂性和成本。其次,关键词的提取依赖于单一标注者的判断,可能存在主观性和一致性问题。此外,数据集中的关键词缺失率为2.5%,表明在某些文档中可能遗漏了重要的关键词。这些挑战需要在未来的研究和应用中加以解决,以提高数据集的质量和可靠性。
常用场景
经典使用场景
在自动关键词提取领域,110-PT-BN-KP数据集因其独特的广播新闻文本特性而成为经典。该数据集包含110篇来自欧洲葡萄牙语广播新闻的转录文本,涵盖政治、体育、财经等多个领域。研究者常利用此数据集开发和评估关键词提取算法,特别是在处理广播新闻文本时,如何准确捕捉和提取关键信息,成为该数据集的核心应用场景。
衍生相关工作
基于110-PT-BN-KP数据集,研究者们开发了多种关键词提取算法,并在此基础上衍生出一系列相关工作。例如,有研究提出了基于深度学习的广播新闻关键词提取模型,显著提升了提取的准确性和效率。此外,还有研究将该数据集与其他多语言数据集结合,探索跨语言关键词提取的通用方法,进一步扩展了该数据集的应用范围和影响力。
数据集最近研究
最新研究方向
在自动关键词提取领域,110-PT-BN-KP数据集的研究方向主要集中在利用多模态数据融合和深度学习技术提升关键词提取的准确性和效率。随着自然语言处理技术的进步,研究者们正探索如何结合文本、音频和视频数据,通过跨模态学习来增强关键词识别的鲁棒性。此外,基于预训练语言模型(如BERT和GPT-3)的微调策略也被广泛应用于该数据集,以期在不同语言和领域中实现更精准的关键词提取。这些前沿技术的融合,不仅提升了关键词提取的效果,也为跨语言和跨领域的知识表示与检索提供了新的可能性。
以上内容由遇见数据集搜集并总结生成


