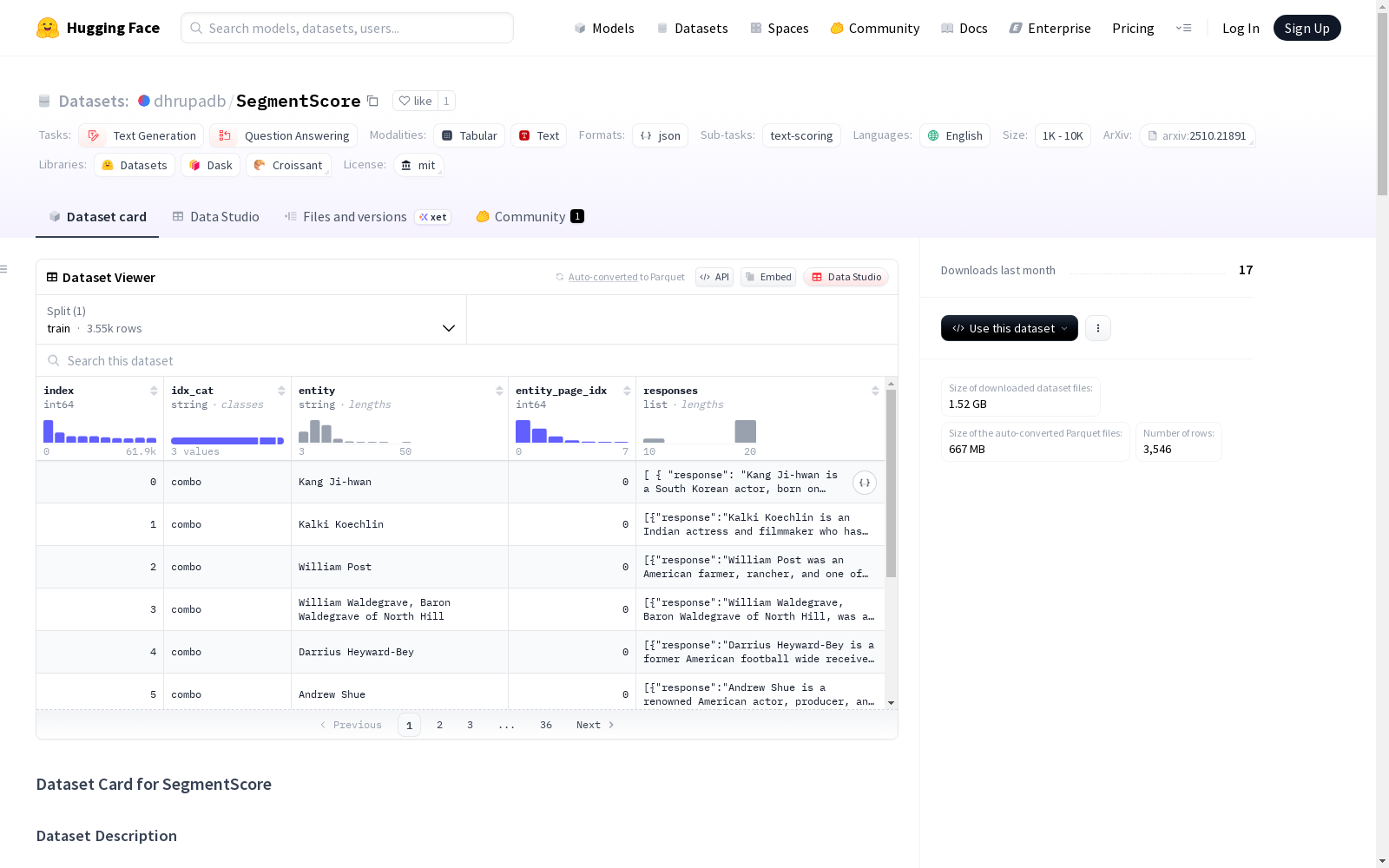
SegmentScore
收藏SegmentScore数据集概述
数据集基本信息
- 名称: SegmentScore: Factuality Scored Long Form Text Generations
- 许可证: MIT
- 语言: 英语
- 任务类别: 文本生成、问答、文本评分
数据集描述
该数据集包含来自多种大语言模型的开放式生成长文本生成结果,使用SegmentScore算法和GPT-4.1-mini作为评判器对事实性进行评分。
数据来源
- 模型来源: OpenAI GPT-4.1-mini、Microsoft Phi-3.5 Mini Instruct、Meta Llama-3.1 8B Instruct
- 主页: https://arxiv.org/abs/TBD
- 代码库: https://github.com/dhrupadb/semantic_isotropy/
数据字段结构
每个JSONL条目对应单个主题/实体,包含该主题的生成响应列表:
index: 整数索引标识符idx_cat: 数据集类别/分割(triviaqa: ["train", "val"]、fsbio: ["combo"])entity: 生成响应的输入主题或实体entity_page_idx: 实体参考页面索引responses: 响应对象列表response: 生成响应的完整文本logprobs: 响应中每个token的对数概率statements: 评分的事实陈述列表text: 单个陈述的文本class: 事实性分类("True"或"False")logprob_raw: 陈述的原始对数概率分数prob_norm: 归一化概率分数top_probs: 包含"0"和"1"键的顶级概率字典
数据统计
目标响应长度500词
TriviaQA数据集
| 模型 | 主题总数 | 平均声明数/响应 | 平均token数 | 平均事实性 |
|---|---|---|---|---|
| Llama-3.1 8B | 1000 | 29.77 | 807.45 | 0.458 |
| Phi-3.5 Mini | 1000 | 24.00 | 621.78 | 0.433 |
| GPT-4.1 Mini | 1000 | 38.76 | 1043.15 | 0.58 |
FS-BIO数据集
| 模型 | 主题总数 | 平均声明数/响应 | 平均token数 | 平均事实性 |
|---|---|---|---|---|
| Llama-3.1 8B | 182 | 28.98 | 811.77 | 0.196 |
| Phi-3.5 Mini | 182 | 28.32 | 626.69 | 0.358 |
| GPT-4.1 Mini | 182 | 21.59 | 593.77 | 0.322 |
数据加载方式
python from datasets import load_dataset
dataset = triviaqa # 或 fsbio models = ["openai", "meta", "msft"] data_files = { "openai": f"data/{dataset}/openai.jsonl", "meta_llama3.1": f"data/{dataset}/meta.jsonl", "msft_phi3.5": f"data/{dataset}/msft.jsonl" } segscore = load_dataset("dhrupadb/SegmentScore", data_files=data_files)
引用信息
bibtex @misc{bhardwaj2025embeddingtrustsemanticisotropy, title={Embedding Trust: Semantic Isotropy Predicts Nonfactuality in Long-Form Text Generation}, author={Dhrupad Bhardwaj and Julia Kempe and Tim G. J. Rudner}, year={2025}, eprint={2510.21891}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2510.21891}, }
联系方式
- Dhrupad Bhardwaj: db4045ATnyuDOTedu
- Tim G.J. Rudner: timATtimrudnerDOTcom