BelleGroup/train_0.5M_CN
收藏Hugging Face2023-04-03 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/BelleGroup/train_0.5M_CN
下载链接
链接失效反馈资源简介:
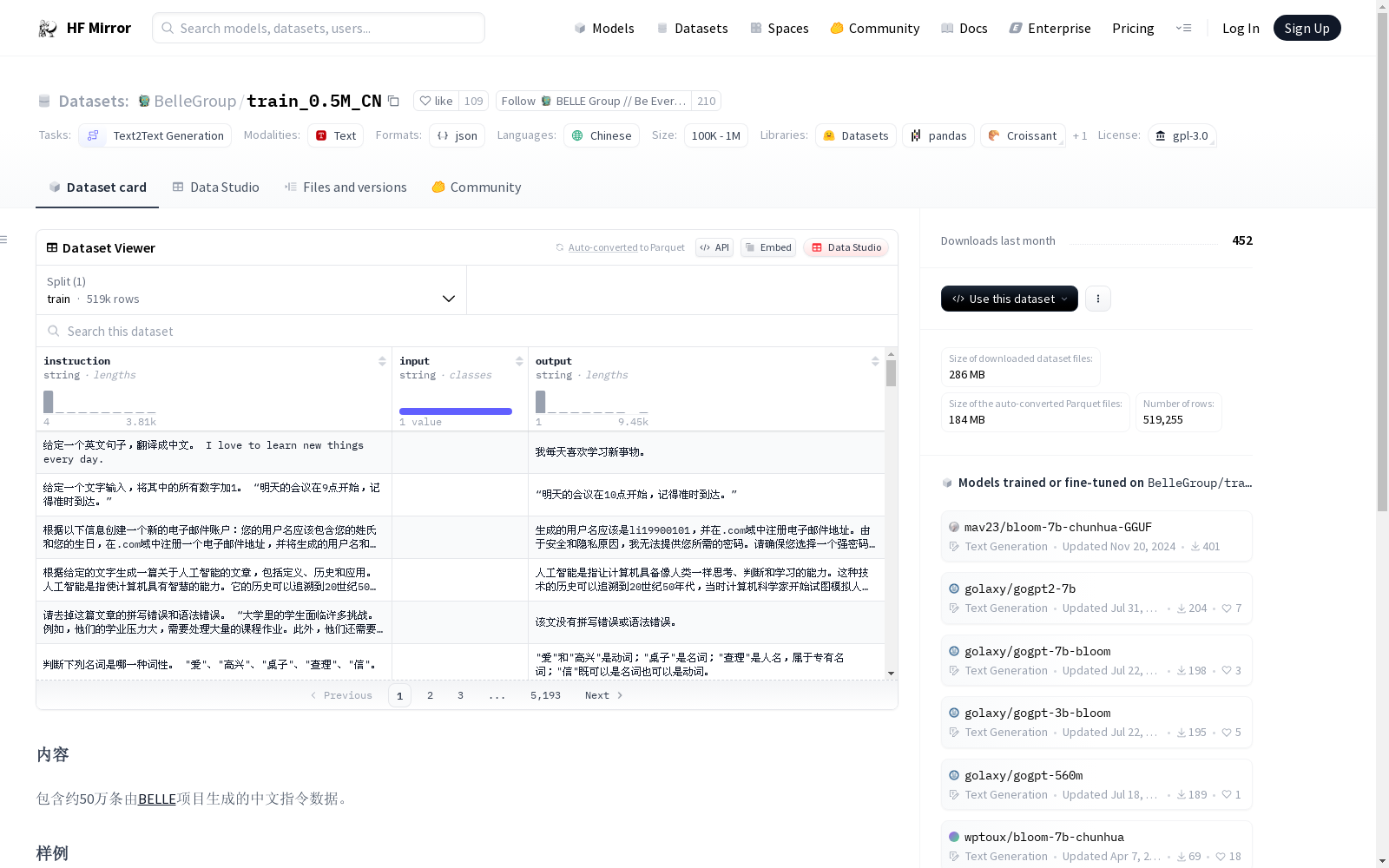
包含约50万条由BELLE项目生成的中文指令数据。每条数据包含一个指令、输入(本数据集均为空)和输出。
This dataset contains approximately 500,000 Chinese instruction samples generated by the BELLE Project. Each sample includes an instruction, an input (which is empty for all entries in this dataset), and an output.
提供机构:
BelleGroup
原始信息汇总
数据集概述
基本信息
- 许可证: GPL-3.0
- 任务类别: 文本到文本生成
- 语言: 中文
- 数据集大小: 10万至100万条数据
内容描述
- 数据来源: BELLE项目
- 数据量: 约50万条中文指令数据
数据结构
- 字段说明:
- instruction: 指令
- input: 输入(数据集中的输入均为空)
- output: 输出
使用限制
- 使用目的: 仅限于研究目的
- 禁止用途: 不得用于商业用途或可能对社会造成危害的用途
- 免责声明: 本数据集不代表任何立场、利益或想法,使用本数据集造成的任何损害、纠纷,本项目不承担责任。
搜集汇总
数据集介绍
构建方式
BelleGroup/train_0.5M_CN数据集的构建,是基于BELLE项目生成的中文指令数据,共计约50万条。这些数据旨在模拟和提供文本到文本生成的训练场景,其中每一条记录由一个指令和相应的输出构成,而输入字段为空,反映了数据集特定的使用场景和构建逻辑。
特点
该数据集显著的特点在于其专为大规模中文文本生成任务而设计,数据条目清晰,包含指令、输入和输出三个字段。指令字段明确指出了文本处理的任务要求,而输出字段则展示了根据指令得到的处理结果,体现了数据集在文本生成任务中的实用性和指导性。此外,数据集遵循GPL-3.0协议,确保了数据的合法使用和共享。
使用方法
使用BelleGroup/train_0.5M_CN数据集时,用户需遵循特定的使用限制,即仅限于研究目的,禁止用于商业或可能对社会造成危害的场合。用户可以通过数据集中的指令和输出来训练和评估文本生成模型,指令字段指导模型理解和执行特定的文本操作,而输出字段则作为模型性能评价的参考标准。在应用前,用户应确保对数据集的使用符合相关法律法规和伦理标准。
背景与挑战
背景概述
BelleGroup/train_0.5M_CN数据集,诞生于BELLE项目,该项目由相关研究人员和机构共同发起,旨在推动自然语言处理领域的发展。该数据集创建于近期,包含约50万条中文指令数据,主要针对文本到文本生成的任务,为研究者和开发者提供了丰富的实验资源。此数据集的问世,不仅丰富了中文自然语言处理的数据资源,也为相关领域的研究带来了新的视角和可能性。
当前挑战
该数据集在解决文本2文本生成领域问题的同时,也面临诸多挑战。首先,数据集构建过程中,确保指令的准确性和多样性是一大难题。其次,数据集在遵守使用限制的同时,如何平衡研究自由度与合规性也是一个挑战。此外,数据集在应用于模型训练时,如何有效避免偏差和误导,保持输出的中立性,也是当前面临的重要问题。
常用场景
经典使用场景
在自然语言处理领域,BelleGroup/train_0.5M_CN数据集的典型应用场景是文本到文本生成的任务,尤其是指令微调。研究者可以借助该数据集,训练模型理解和执行中文指令,从而提升模型在特定任务中的表现。
实际应用
在实际应用中,BelleGroup/train_0.5M_CN数据集可以被用于开发智能助手、自动回复系统等,能够理解和响应复杂中文指令的软件,从而提升用户体验和系统的智能化水平。
衍生相关工作
基于BelleGroup/train_0.5M_CN数据集,学术界衍生出了一系列相关工作,如指令细粒度理解、指令生成质量评估等,这些研究进一步拓宽了自然语言处理技术在中文指令处理领域的应用范围。
以上内容由遇见数据集搜集并总结生成


