namuwiki-arknights-asr-preview
收藏Hugging Face2025-09-10 更新2025-09-11 收录
下载链接:
https://huggingface.co/datasets/alchemine/namuwiki-arknights-asr-preview
下载链接
链接失效反馈官方服务:
资源简介:
名日方舟语音识别数据集是一个基于Namuwiki相关文档构建的韩国语语音数据集,专门用于训练自动语音识别(ASR)模型。该数据集包含了名日方舟游戏相关的多样术语和设置,适合用于特定领域的ASR模型开发。
创建时间:
2025-09-08
原始信息汇总
Namuwiki Arknights ASR Dataset (Preview) 数据集概述
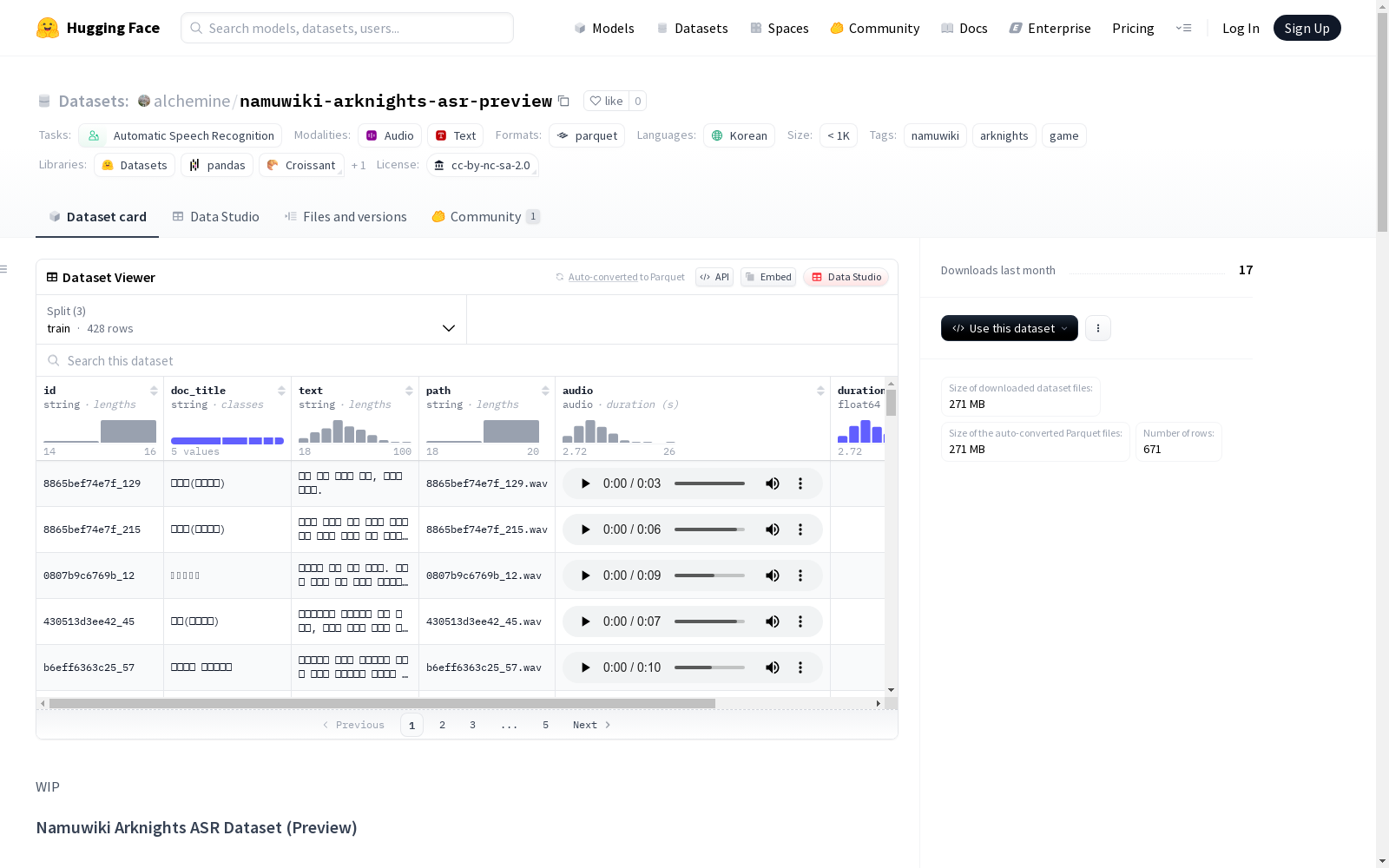
数据集基本信息
- 语言:韩语 (ko)
- 任务类别:自动语音识别 (automatic-speech-recognition)
- 标签:namuwiki, arknights, game
- 许可证:CC BY-NC-SA 2.0 KR
数据集描述
该数据集基于明日方舟 - 纳木维基相关文档中与明日方舟/设定相关的文档构建,是用于语音识别(ASR)模型训练的韩语语音数据集。包含明日方舟游戏的各种术语和设定,对开发特定领域的ASR模型非常有用。
数据集统计信息
- 数据基准日期:2025/09/10
- 总文档数:5
- 总数据量:671条
- 训练数据量:428条
- 验证数据量:108条
- 测试数据量:135条
- 总音频时长:1.69小时
- 平均音频时长:9.07秒
- 音频时长最小值:2.44秒
- 音频时长最大值:25.96秒
- 采样率:16kHz
- 音频通道:单声道
数据结构
每个样本包含以下字段:
id(str):唯一音频标识符 (doc_seq)doc_title(str):文档标题path(str):音频文件路径text(str):对应音频的韩语文本转录audio(dict):16kHz单声道音频文件duration(float):音频时长(秒)created_at(datetime):音频文件创建时间
数据构建过程
1. 文本数据收集
从纳木维基的"明日方舟"相关文档中提取文本内容。
2. 文本预处理
对收集的文本进行以下预处理:
- 选择具有足够句子数量的段落
- 以句号、问号、感叹号为基准分割句子
- 合并过短句子(5个单词以下),分割过长句子(20个单词以上)
- 移除不必要的括号、换行符和特定特殊字符
- 统一将
...替换为. - 排除没有韩语内容的句子
- 移除具有相同文本的句子以确保数据多样性
3. 语音数据生成
使用Higgs Audio V2 TTS模型将预处理后的文本转换为语音:
- 随机选择男性和女性配音演员的声音以多样化数据集的性别分布
- 确保所有音频不超过30秒
版本信息
- v1.0-preview
- 数据基准日期:2025-09-10
- 总数据量:...条
- 总文档数:47个
- 基准文本数据集:alchemine/namuwiki-arknights-text-preview/v1.0-preview
- TTS模型:Higgs Audio V2
许可证
本数据集根据CC BY-NC-SA 2.0 KR许可证分发。
搜集汇总
数据集介绍
构建方式
在游戏领域语音识别技术日益重要的背景下,该数据集通过系统化流程构建而成。首先从韩国知名游戏《明日方舟》的Namuwiki相关文档中提取文本内容,经过严格的文本预处理流程,包括句子分割、长度调整、特殊字符清理及去重处理。随后采用Higgs Audio V2 TTS模型将筛选后的文本转换为语音数据,通过随机选择男女声优配音确保音色多样性,并严格控制单条音频时长在30秒以内。
特点
作为专门针对游戏领域的语音识别数据集,其显著特点在于高度专业化的领域适应性。数据集包含671条韩语语音样本,总时长1.69小时,平均每条音频9.07秒,采样率为16kHz的单声道格式。内容涵盖《明日方舟》游戏特有的术语和设定描述,具有明确的训练、验证和测试集划分,为领域特异性ASR模型开发提供了高质量的语音-文本配对数据。
使用方法
在语音识别研究领域,该数据集可通过Hugging Face datasets库直接加载使用。研究人员只需指定数据集名称即可获取包含训练集、验证集和测试集的完整数据,每个样本均提供音频文件路径、文本转录、时长等关键信息。支持使用标准音频处理工具进行播放和分析,为开发针对游戏术语优化的韩语语音识别模型提供了便捷的数据接入方案。
背景与挑战
背景概述
随着语音识别技术在特定领域应用的深入,专业化数据集的需求日益凸显。2025年,研究机构alchemine基于韩国知名游戏《明日方舟》的namuwiki文本资料,构建了namuwiki-arknights-asr-preview数据集。该数据集专注于游戏领域的自动语音识别任务,通过系统化的文本挖掘与语音合成技术,为韩语游戏术语识别提供了高质量的训练资源,推动了领域适应性语音模型的发展。
当前挑战
该数据集旨在解决游戏领域专业术语的语音识别挑战,包括复杂专有名词的准确辨识和领域特定表达的理解。构建过程中面临多重挑战:需要从非结构化的wiki文本中提取适合语音合成的连贯语句,确保文本的语法正确性和语义完整性;通过TTS技术生成自然语音时需平衡音质与多样性,避免合成语音的机械感影响模型训练效果。
常用场景
经典使用场景
在语音识别技术领域,该数据集专门针对游戏术语和设定内容进行优化,为训练领域特定的自动语音识别模型提供高质量语料。其核心应用场景包括构建能够准确识别《明日方舟》游戏专有名词的语音识别系统,通过包含角色名称、技能术语等游戏特定词汇的语音文本对,显著提升模型在游戏领域的识别准确率。
衍生相关工作
基于该数据集衍生的研究工作主要集中在领域自适应语音识别模型的开发,包括使用迁移学习技术将通用语音识别模型适配到游戏特定领域。相关成果推动了合成语音数据在低资源场景下的应用研究,为其他垂直领域的语音识别系统建设提供了可借鉴的方法论和技术路径。
数据集最近研究
最新研究方向
在游戏领域语音识别技术快速发展的背景下,namuwiki-arknights-asr-preview数据集代表了领域自适应ASR研究的最新趋势。该数据集聚焦于《明日方舟》游戏术语的韩语语音识别,通过高质量TTS合成技术构建专业领域语料库,为低资源场景下的领域特异性模型训练提供了创新解决方案。当前研究热点集中于利用此类合成数据增强跨语言游戏语音识别性能,特别是在处理游戏专有名词和文化特定表达方面。该数据集的建立不仅推动了游戏本地化技术的进步,更为多模态人机交互系统在娱乐产业的应用奠定了重要基础,对促进韩语语音技术在国际游戏市场的适配具有显著意义。
以上内容由遇见数据集搜集并总结生成


