BeyondX
收藏Hugging Face2024-07-10 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/Johnson0213/BeyondX
下载链接
链接失效反馈官方服务:
资源简介:
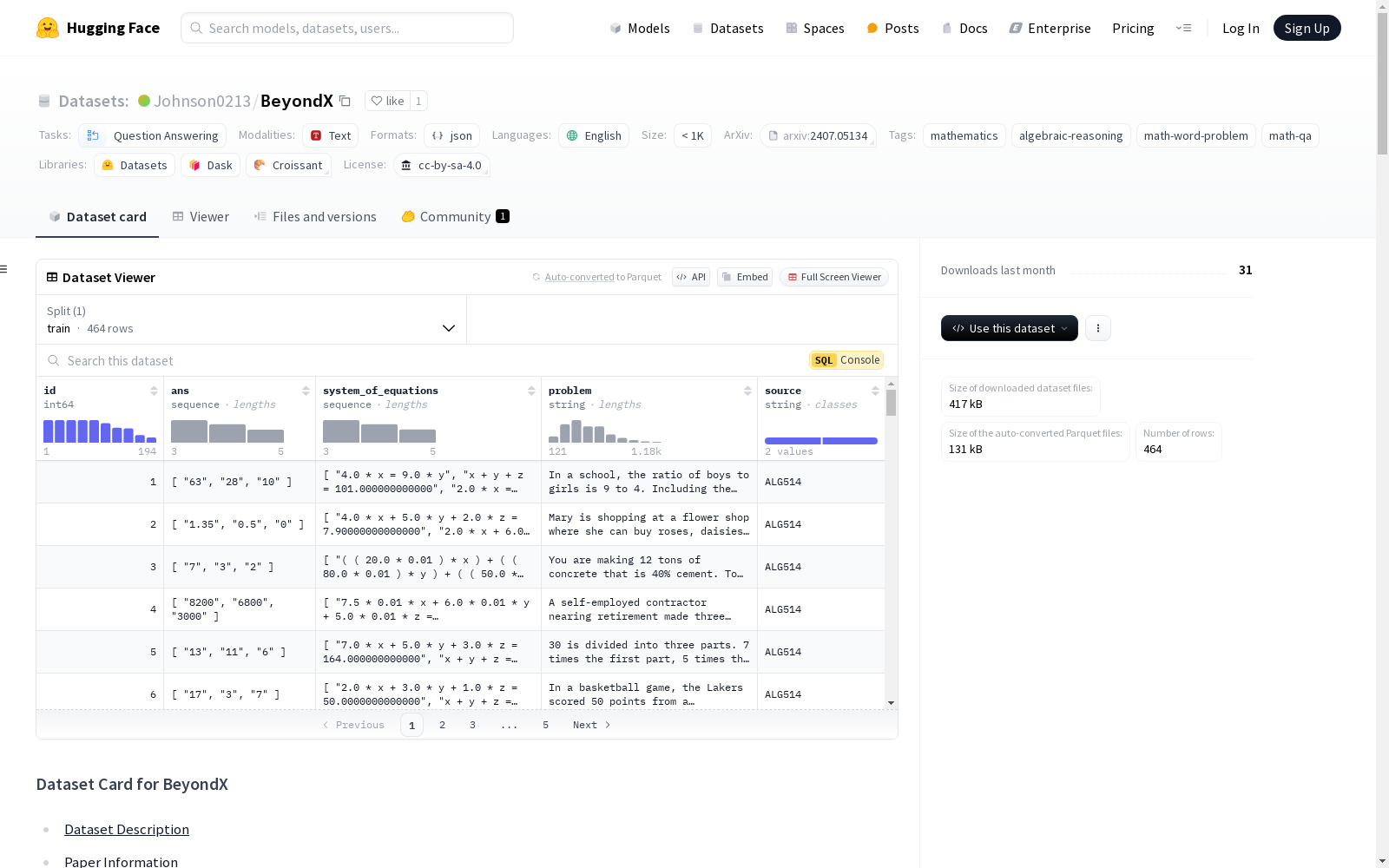
BeyondX数据集是一个新颖的代数推理基准,主要针对多未知数问题,解决了现有数学数据集中最多只有两个未知数的局限性。该数据集包含464个示例,来源于两个不同的源数据集。数据集分为三个子集:BeyondX_3(194个示例,三个未知数)、BeyondX_4(158个示例,四个未知数)和BeyondX_5(112个示例,五个未知数)。数据集的特征包括问题文本、方程系统、答案、问题ID和数据源。数据集的生成基于两个收集的数据集,并通过一个新颖的管道自动扩展现有问题到N个未知数。
创建时间:
2024-07-04
原始信息汇总
数据集概述
基本信息
- 名称: BeyondX
- 许可: CC BY-SA 4.0
- 任务类别: 问答
- 语言: 英语
- 标签: 数学, 代数推理, 数学应用题, 数学问答
- 大小类别: 1K<n<10K
数据集描述
- 包含示例: 464个
- 来源数据集: 2个不同来源的数据集
数据集结构
- 特征:
id: 问题ID,类型为int64ans: 答案,类型为字符串序列system_of_equations: 方程组,类型为字符串序列problem: 问题文本,类型为字符串source: 数据来源,类型为字符串
数据集示例
- 示例类型:
- 两未知数问题
- 三未知数问题
- 四未知数问题
- 五未知数问题
数据集使用
-
数据下载:
- 分为三个子集: BeyondX_3, BeyondX_4, BeyondX_5
- 下载命令: python from datasets import load_dataset dataset = load_dataset("Johnson0213/BeyondX")
-
数据格式:
- 数据以JSON格式提供,包含以下属性: json { "problem": "问题文本", "system_of_equations": "方程组", "ans": "答案", "id": "问题ID", "source": "数据来源" }
数据集构建
- 来源: 从ALG514和DRAW-1K两个数据集衍生
- 构建方法: 开发了一种新流程,自动将现有问题扩展到N个未知数
许可
- 许可类型: CC BY-SA 4.0
- 使用条件:
- 主要用于测试集
- 可用于商业用途作为测试集,但禁止用作训练集
引用
latex @misc{kao2024solvingxbeyondlarge, title={Solving for X and Beyond: Can Large Language Models Solve Complex Math Problems with More-Than-Two Unknowns?}, author={Kuei-Chun Kao and Ruochen Wang and Cho-Jui Hsieh}, year={2024}, eprint={2407.05134}, archivePrefix={arXiv}, primaryClass={cs.AI}, url={https://arxiv.org/abs/2407.05134}, }
搜集汇总
数据集介绍
构建方式
BeyondX数据集的构建基于两个现有数据集ALG514和DRAW-1K,通过自动扩展现有问题至多个未知数的方式生成。该数据集采用了一种新颖的管道方法,能够高效地生成包含多个未知数的数学问题。具体构建过程包括从原始数据集中提取问题,并通过算法扩展为包含三、四、五个未知数的问题,最终形成包含464个示例的数据集。
特点
BeyondX数据集专注于代数推理领域,特别针对多未知数问题,弥补了现有数学数据集中最多仅包含两个未知数的局限性。该数据集包含464个示例,分为三个子集:BeyondX_3、BeyondX_4和BeyondX_5,分别对应三、四、五个未知数的问题。每个示例包含问题文本、方程组、答案、问题ID以及数据来源,格式清晰且易于使用。
使用方法
BeyondX数据集可通过Huggingface Datasets库下载,用户可以使用Python代码加载数据集并访问其内容。数据集以JSON格式提供,包含问题文本、方程组、答案、问题ID和数据来源等字段。用户可以通过简单的代码示例查看数据集中的具体内容,并利用其进行代数推理模型的训练与评估。此外,数据集还提供了可视化工具和排行榜,便于用户探索和比较模型性能。
背景与挑战
背景概述
BeyondX数据集由Kuei-Chun Kao、Ruochen Wang和Cho-Jui Hsieh等研究人员于2024年提出,旨在解决现有数学数据集中多未知数问题的不足。该数据集专注于代数推理领域,特别是针对包含三个及以上未知数的数学问题。通过从ALG514和DRAW-1K两个现有数据集中扩展生成,BeyondX共包含464个示例,涵盖三、四、五未知数的问题。这一数据集的推出为代数推理研究提供了新的基准,推动了多未知数问题求解技术的发展。
当前挑战
BeyondX数据集的核心挑战在于解决多未知数数学问题的复杂性。现有数据集大多局限于最多两个未知数的问题,而BeyondX通过扩展至三个及以上未知数,显著增加了问题的难度。构建过程中,研究人员面临的主要挑战是如何高效地从现有数据集中生成大量多未知数问题,同时确保问题的多样性和逻辑一致性。此外,评估模型在多未知数问题上的表现也带来了新的挑战,特别是在如何设计有效的评估指标和基准测试方面。
常用场景
经典使用场景
BeyondX数据集在代数推理领域具有重要应用,尤其是在多未知数问题的求解中。该数据集通过提供包含三至五个未知数的数学问题,填补了现有数学数据集中多未知数问题的空白。研究人员可以利用该数据集训练和评估模型在多未知数场景下的表现,推动代数推理模型的进一步发展。
衍生相关工作
BeyondX数据集的推出催生了一系列相关研究工作,特别是在多未知数代数推理领域。基于该数据集,研究人员提出了多种新的求解方法,如Formulate-and-Solve等。这些方法不仅在BeyondX数据集上取得了显著成果,还为其他复杂数学问题的求解提供了新的思路和工具,推动了代数推理研究的进一步发展。
数据集最近研究
最新研究方向
在数学推理领域,BeyondX数据集的推出标志着对多未知数问题的深入研究。该数据集通过引入三至五个未知数的数学问题,突破了传统数据集仅包含最多两个未知数的限制,为代数推理研究提供了新的挑战和机遇。当前研究热点集中在如何利用先进的大语言模型(LLMs)来解决这些复杂问题,特别是通过创新的提示方法如Formulate-and-Solve来提升模型的解题能力。此外,BeyondX的构建方法也为其他领域的数据集扩展提供了参考,推动了数学问题自动生成技术的发展。这一数据集的应用不仅限于学术研究,还可能在教育技术中发挥重要作用,帮助开发更智能的数学学习工具。
以上内容由遇见数据集搜集并总结生成


