QSBench-Transpilation-v1.0.0-demo
收藏Hugging Face2026-04-03 更新2026-04-04 收录
下载链接:
https://huggingface.co/datasets/QSBench/QSBench-Transpilation-v1.0.0-demo
下载链接
链接失效反馈官方服务:
资源简介:
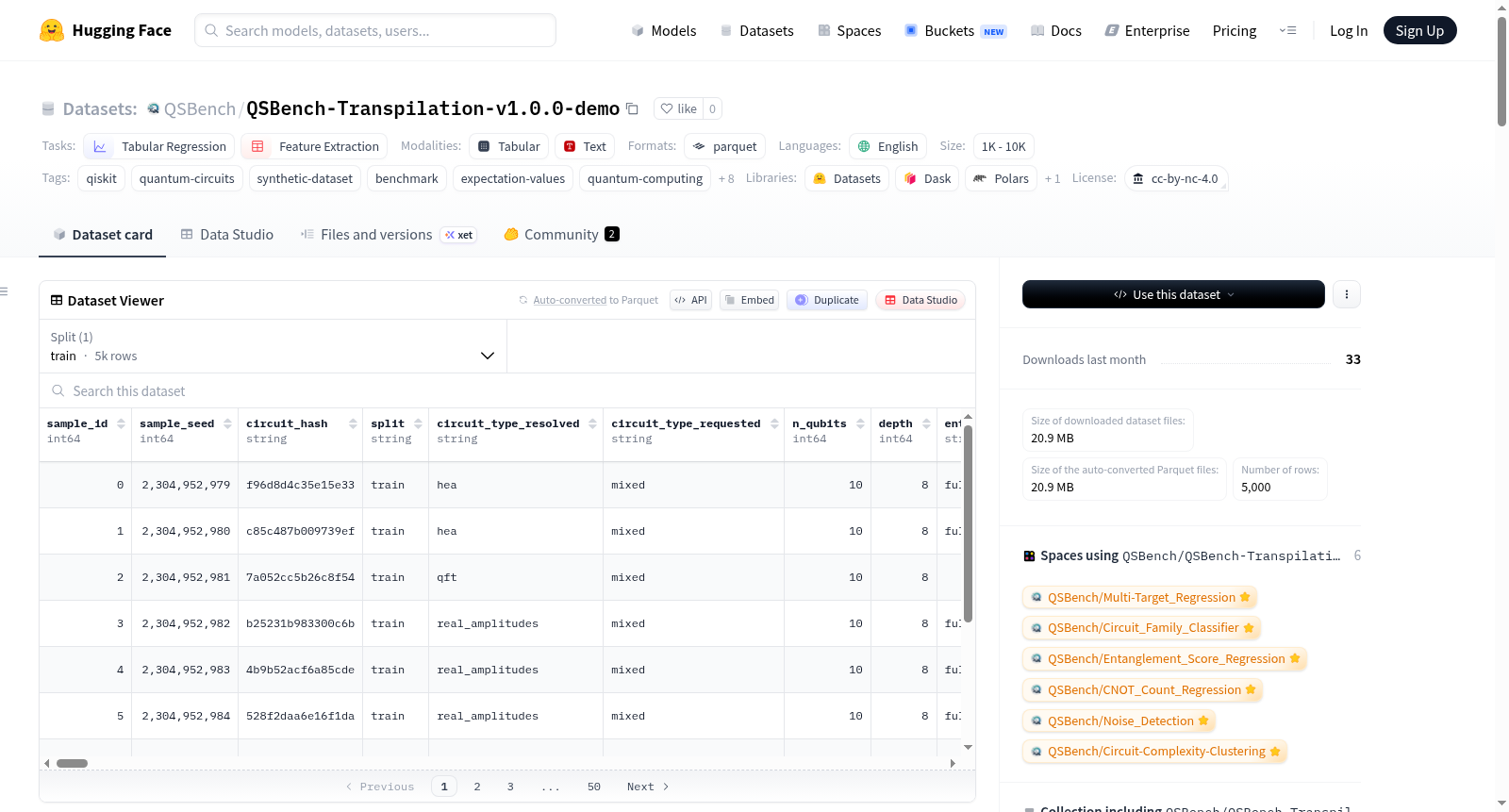
QSBench Transpilation Demo v1.0.0 是一个硬件感知的量子机器学习数据集,专注于电路优化和映射分析。该数据集包含5000个高质量的合成量子电路,每个电路具有10个量子位和深度为8。电路家族包括HEA、RealAmplitudes、QFT、Efficient SU(2)和随机电路,采用完全纠缠和无噪声模拟。数据集提供了原始和转译后的QASM表示、电路邻接矩阵、详细的栅极统计、结构度量以及理想期望值。适用于研究编译器优化、硬件感知机器学习和连接受限的变分算法。数据集还提供了训练、验证和测试的确定性哈希分割。每个样本包含丰富的元数据,如电路家族标签和生成深度。数据集以Parquet格式存储,可通过Hugging Face的datasets库直接加载。该数据集是QSBench系列的一部分,适用于个人和研究用途,采用CC BY-NC 4.0许可。
创建时间:
2026-04-02
原始信息汇总
QSBench Transpilation Demo v1.0.0 数据集概述
基本信息
- 数据集名称:QSBench Transpilation Demo v1.0.0 – Hardware-Aware Quantum Dataset (n=10, depth=8)
- 许可证:CC BY-NC 4.0
- 任务类别:表格回归、特征提取
- 语言:英语
- 标签:qiskit、quantum-circuits、synthetic-dataset、benchmark、expectation-values、quantum-computing、qml-benchmark、quantum dataset、qml dataset、quantum benchmark、hardware-aware、transpilation、circuit-optimization、topology-mapping
- 数据规模:1K<n<10K
- 样本数量:5000
数据集简介
这是一个用于电路优化和映射分析的硬件感知量子机器学习数据集。包含专为研究量子电路转译对电路结构影响而设计的10量子位电路。该数据集是QSBench硬件包的一个演示子集,具有更大的宽度(n=10)和深度(depth=8),适用于从事编译器优化、硬件感知机器学习和连接受限变分算法的研究人员和工程师。
核心价值
量子电路转译是将抽象量子电路映射到物理硬件的关键瓶颈。此数据集允许用户:
- 研究转译后的门数量和电路增长。
- 分析大规模系统的连接性和邻接矩阵。
- 训练模型以预测转译开销。
- 对10量子位电路拓扑的特征提取进行基准测试。
应用场景
- 转译开销预测
- 硬件感知特征工程
- 门数量优化基准测试
- 连接性和交换门分析
- 量子机器学习模型的扩展性研究
数据集详情
- 量子位数量:10
- 电路深度:8
- 电路族:混合(HEA, RealAmplitudes, QFT, Efficient SU(2), Random)
- 纠缠:完全纠缠
- 噪声:无(用于基线硬件感知研究的干净模拟)
- 可观测量:Z, X, Y混合模式(全局 + 每量子位)
- 测量次数:1024
- 数据划分:训练集 / 验证集 / 测试集(基于确定性哈希)
样本内容
每个Parquet文件中的样本包含:
- 原始和转译后的QASM表示(n=10)
- 10量子位拓扑的电路邻接矩阵
- 详细的门统计信息(CX, H, RX, RY, RZ和总门数)
- 结构度量:门熵 + Meyer-Wallach纠缠度
- Z, X, Y的理想期望值(全局和每量子位)
- 电路族标签和完整的生成元数据(depth=8)
- 确定性划分标签
机器学习视角
数据集将转译问题构建为图翻译与优化任务:
- 输入(X):
qasm_raw(源语言/原始序列) - 输出(y):
qasm_transpiled(目标语言/编译后序列) - 成本度量:
depth,cx_count(编译后电路的“成本”) - 环境:
n_qubits(硬件设备的约束)
快速开始建议
可将此视为文本复杂度问题。计算qasm_raw和qasm_transpiled的字符长度和门关键字数量,并训练线性回归模型来预测“转译开销”(编译后深度与原始深度的比率)。
数据加载
数据集以Parquet格式存储在data/shards/文件夹中,可通过Hugging Face datasets库直接加载:
python
from datasets import load_dataset
dataset = load_dataset("QSBench/QSBench-Transpilation-v1.0.0-demo", split="train")
仓库结构
QSBench-Transpilation-v1.0.0-demo/ ├── README.md └── data/ └── shards/ └── *.parquet └── *.csv
所有元数据文件(coverage.json, schema.json, meta.json等)位于名为metadata的独立分支中。
相关数据集
- QSBench Lite(20k样本,n=4)
- QSBench Core(75k样本,n=8)
- Depolarizing Noise Pack(150k样本)
- Amplitude Damping Pack(150k样本)
- Full Hardware Pack(200k样本,n=10-12)
重要说明
- 该数据集是完全合成的,使用量子电路模拟生成,不包含任何真实世界或个人数据。
- 许可证为CC BY-NC 4.0,允许个人和研究使用。
搜集汇总
数据集介绍
构建方式
在量子计算领域,硬件感知的数据集对于研究编译优化至关重要。QSBench-Transpilation-v1.0.0-demo数据集通过量子电路模拟技术构建,生成了5000个高质量的合成量子电路样本。这些电路采用10量子比特设计,深度固定为8,并混合了多种电路家族,如HEA、RealAmplitudes、QFT等,以确保多样性。每个样本包含原始QASM表示和经过硬件转译后的版本,同时记录了详细的电路结构指标,如门计数、纠缠度及期望值,所有数据均基于确定性哈希分割为训练、验证和测试子集,为硬件感知的机器学习研究提供了标准化基准。
特点
该数据集的核心特点在于其硬件感知的设计理念,专注于量子电路转译过程的分析。它提供了10量子比特规模的电路拓扑结构,包括完整的邻接矩阵和门统计信息,使得研究者能够深入探究转译对电路深度和门数量的影响。数据集涵盖了多种电路家族,并采用全局与单量子比特混合的观测模式,增强了其在量子机器学习基准测试中的适用性。所有电路均在无噪声的清洁模拟环境下生成,确保了基线研究的可靠性,同时通过结构化特征如门熵和纠缠度量,为图神经网络或序列模型的应用奠定了数据基础。
使用方法
使用该数据集时,研究者可将其视为图翻译或序列到序列的学习任务。通过加载Parquet格式的数据文件,可以直接访问原始与转译后的QASM代码,以及相关的成本指标和拓扑约束。典型的应用包括训练模型预测转译开销,例如基于电路原始特征估计编译后的深度或CX门数量。数据集兼容Hugging Face的datasets库,支持快速加载和预处理,也可通过pandas进行灵活的数据分析。对于机器学习实践,建议从计算文本复杂度或图结构特征入手,构建回归或分类模型,以优化量子电路的硬件映射效率。
背景与挑战
背景概述
量子计算领域的发展日益依赖于硬件感知的算法优化,其中量子电路转译(transpilation)作为连接抽象算法与物理硬件的关键环节,已成为制约计算效率的核心瓶颈。QSBench-Transpilation-v1.0.0-demo数据集由QSBench团队于近期创建,旨在为研究者和工程师提供一个专注于10量子比特电路转译分析的基准平台。该数据集包含5000个高质量合成电路,覆盖多种电路家族(如HEA、QFT等),并提供了原始与转译后的量子汇编代码(QASM)、电路拓扑邻接矩阵及详细的栅极统计信息。其核心研究问题聚焦于量化转译过程对电路结构的影响,例如栅极数量增长与深度扩展,从而推动编译器优化、硬件感知机器学习以及连接受限变分算法的前沿探索。
当前挑战
在量子计算领域,转译过程所面临的核心挑战在于如何高效地将抽象量子算法映射到具有特定连通性约束的物理硬件上,同时最小化电路深度与栅极开销,以缓解噪声累积并提升计算保真度。QSBench-Transpilation数据集针对这一挑战,旨在通过大规模合成数据支持转译开销预测模型的训练与评估。在构建过程中,数据集需克服多维度难题:一是生成兼具多样性与真实性的电路拓扑,以涵盖不同硬件架构的映射场景;二是精确模拟转译后的电路指标,确保数据在无噪声环境下的基准可靠性;三是设计可扩展的数据结构,以支持从序列到序列模型到图神经网络等多种机器学习范式的直接应用。
常用场景
经典使用场景
在量子计算领域,硬件感知的量子电路编译(即量子电路转译)是提升计算效率的关键环节。QSBench-Transpilation-v1.0.0-demo数据集通过提供5000个10量子比特的合成电路,为研究者构建了一个标准化的基准平台。该数据集的核心应用场景在于分析量子电路在转译过程中的结构变化,例如门数量增长和深度扩展,从而支持编译器优化算法的开发与评估。
解决学术问题
该数据集针对量子机器学习中的硬件约束问题,提供了系统性的解决方案。它使研究者能够量化转译开销,探索电路拓扑与硬件连接性之间的映射关系,并推动预测模型的构建。这些工作有助于缓解量子计算中的编译瓶颈,为硬件感知的算法设计奠定实证基础,促进了量子软件栈的优化与标准化。
衍生相关工作
围绕该数据集,学术界衍生了一系列经典研究,主要集中在图神经网络和序列到序列模型的应用。例如,研究者将原始电路与转译后电路视为图结构或文本序列,训练模型学习转译规则,以预测电路深度或门数量变化。这些工作不仅拓展了量子编译的自动化方法,也为跨领域的图翻译与优化任务提供了新的思路。
以上内容由遇见数据集搜集并总结生成


