Look Into Person (LIP)
收藏www.sysu-hcp.net2024-11-02 收录
下载链接:
http://www.sysu-hcp.net/lip/
下载链接
链接失效反馈官方服务:
资源简介:
Look Into Person (LIP) 数据集是一个用于人体解析任务的数据集,包含50,000张高质量的人体图像,每张图像都有详细的人体解析标注,包括身体部位和服装类别。该数据集旨在推动人体解析和相关计算机视觉任务的研究。
The Look Into Person (LIP) dataset is a specialized dataset for human parsing tasks. It contains 50,000 high-quality human images, each with detailed human parsing annotations covering body parts and clothing categories. This dataset aims to advance research in human parsing and related computer vision tasks.
提供机构:
www.sysu-hcp.net
搜集汇总
数据集介绍
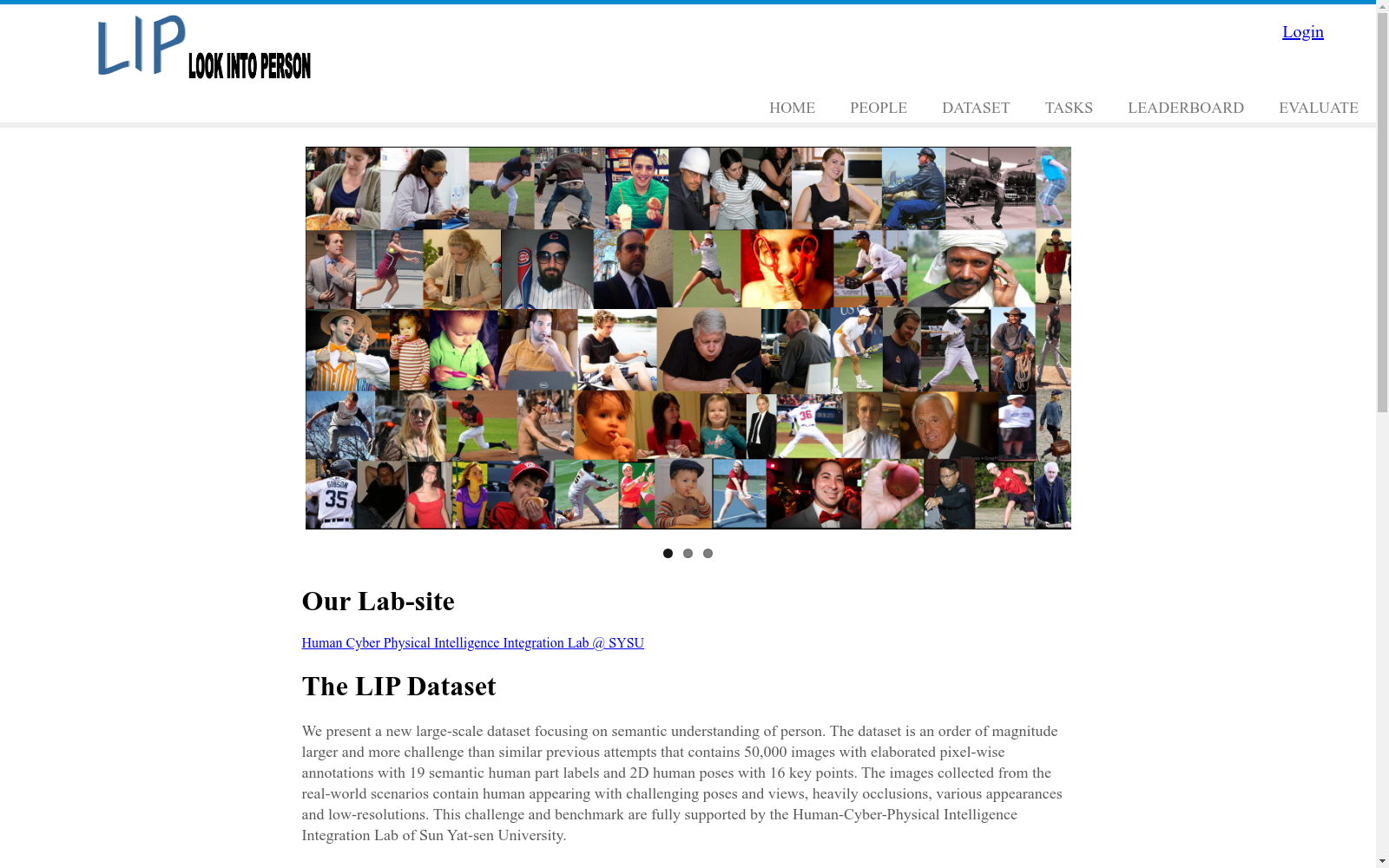
构建方式
Look Into Person (LIP) 数据集的构建基于对多视角人体图像的深度分析。该数据集通过采集大量不同场景下的人体图像,并结合先进的图像处理技术,如语义分割和实例分割,对图像中的人体部位进行精细标注。这些标注不仅包括人体的基本结构,还涵盖了复杂的服装和配饰细节,从而为研究者提供了丰富且多样化的数据资源。
特点
LIP 数据集的显著特点在于其高精度和多样性。首先,数据集中的每张图像都经过多层次的标注,确保了数据的准确性和完整性。其次,LIP 包含了多种复杂场景和不同姿态的人体图像,这使得该数据集在处理实际应用中的复杂性时表现出色。此外,数据集还特别关注了服装和配饰的细节,这对于时尚分析和个性化推荐等应用具有重要价值。
使用方法
LIP 数据集适用于多种计算机视觉任务,包括但不限于人体姿态估计、服装识别和场景理解。研究者可以通过加载数据集中的图像和标注文件,进行模型训练和验证。为了充分利用数据集的多样性,建议采用数据增强技术,如随机裁剪和旋转,以提高模型的泛化能力。此外,LIP 数据集的详细标注信息也适合用于开发和测试新的图像分割算法。
背景与挑战
背景概述
Look Into Person (LIP) 数据集是由中国科学院自动化研究所的研究团队于2017年创建的,专注于人体解析任务。该数据集包含了50,000张高质量的人体图像,每张图像都经过精细标注,涵盖了20个不同的人体部位。LIP数据集的推出,极大地推动了人体解析领域的发展,为研究人员提供了一个标准化的基准,促进了算法性能的提升和创新。其核心研究问题是如何在复杂背景下准确地分割和识别人体各部位,这对于计算机视觉和人工智能领域具有重要的应用价值。
当前挑战
尽管LIP数据集在人体解析领域取得了显著进展,但仍面临诸多挑战。首先,数据集中的人体图像背景复杂多样,增加了分割任务的难度。其次,不同人体部位的形状和大小差异较大,导致模型在处理这些多样性时表现不佳。此外,数据集的标注过程耗时且复杂,需要高度专业化的知识和技能,这限制了数据集的扩展和更新速度。最后,如何在保持高精度的同时提高算法的实时性能,是LIP数据集面临的另一大挑战。
发展历史
创建时间与更新
Look Into Person (LIP) 数据集于2017年首次发布,旨在推动人体姿态估计和语义分割领域的发展。该数据集自发布以来,经历了多次更新,以适应不断演进的算法需求和研究方向。
重要里程碑
LIP数据集的重要里程碑之一是其首次引入的多人姿态估计任务,这一创新为后续研究提供了丰富的数据资源。此外,LIP还引入了高分辨率图像和复杂背景,显著提升了数据集的挑战性和实用性。2018年,LIP数据集在CVPR(计算机视觉与模式识别会议)上被广泛讨论,进一步巩固了其在学术界的影响力。
当前发展情况
当前,LIP数据集已成为人体姿态估计和语义分割领域的重要基准之一。其高分辨率图像和复杂场景的设计,使得研究人员能够开发出更加鲁棒和精确的算法。LIP数据集的持续更新和扩展,不仅推动了相关算法的进步,也为实际应用场景提供了强有力的支持。此外,LIP数据集的开源性质,促进了全球范围内的合作与交流,进一步提升了其在计算机视觉领域的地位。
发展历程
- Look Into Person (LIP) 数据集首次发表,由北京大学的研究人员提出,旨在解决人体姿态估计和语义分割问题。
- LIP 数据集在多个国际计算机视觉会议上被广泛讨论,成为人体姿态估计和语义分割领域的重要基准。
- LIP 数据集的应用扩展到其他相关领域,如动作识别和人体行为分析,进一步验证了其数据质量和多样性。
- LIP 数据集的改进版本发布,增加了更多的标注信息和样本,提升了数据集的实用性和研究价值。
- LIP 数据集被多个研究团队用于开发新的深度学习模型,显著提升了人体姿态估计和语义分割的准确性。
常用场景
经典使用场景
在计算机视觉领域,Look Into Person (LIP) 数据集被广泛用于人体姿态估计和语义分割任务。该数据集包含了大量高质量的人体图像,每张图像都标注了详细的姿态关键点和语义区域。研究人员利用这些标注信息,开发和验证了多种先进的人体姿态估计和语义分割算法,显著提升了模型在复杂场景下的表现。
实际应用
在实际应用中,LIP 数据集的应用场景广泛,包括但不限于视频监控、人机交互、虚拟现实和增强现实等领域。例如,在视频监控系统中,利用LIP数据集训练的模型可以实时检测和跟踪人体姿态,提高安全性和效率。在虚拟现实和增强现实中,精确的人体姿态估计和语义分割技术为用户提供了更加沉浸和自然的交互体验。
衍生相关工作
基于LIP数据集,研究人员开发了多种衍生工作,如改进的姿态估计模型、多任务学习框架和跨域迁移学习方法。这些工作不仅在学术界引起了广泛关注,还在工业界得到了实际应用。例如,一些公司利用LIP数据集训练的模型,开发了智能健身应用和虚拟试衣间,为用户提供了个性化的服务体验。
以上内容由遇见数据集搜集并总结生成


