sled-umich/2D-ATOMS
收藏Hugging Face2023-10-31 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/sled-umich/2D-ATOMS
下载链接
链接失效反馈官方服务:
资源简介:
2D-ATOMS数据集是一个新颖的基于文本的数据集,用于评估机器在情境理论心智(Theory of Mind, ToM)设置下的推理过程。该数据集包括9种不同的ToM评估任务和1个现实检查任务,用于测试大型语言模型(LLMs)对世界的理解。数据集是零样本版本,用于相关论文的研究。
提供机构:
sled-umich
原始信息汇总
2D-ATOMS: 2D Abilities in Theory of Mind Space 数据集
概述
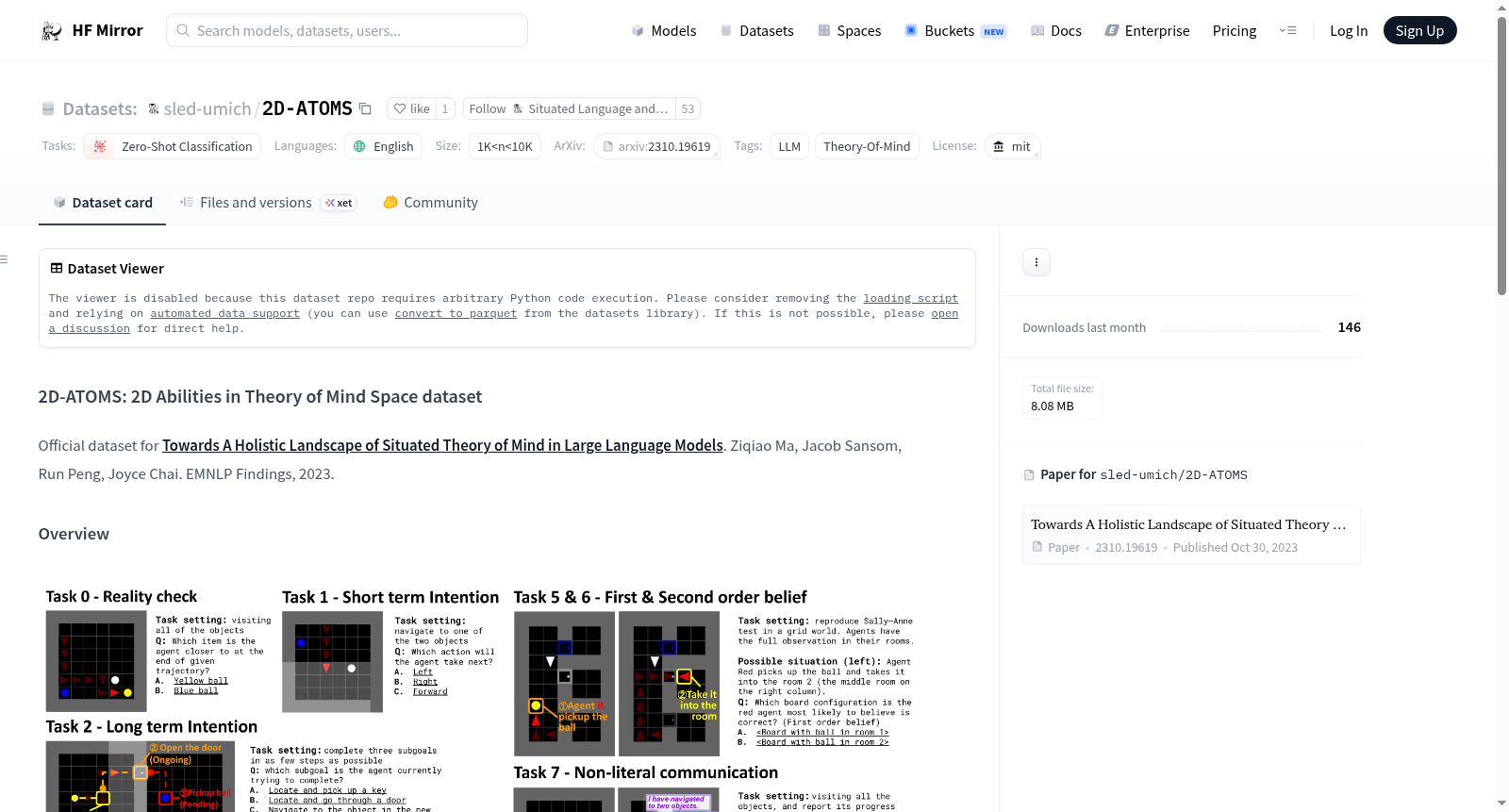
2D-ATOMS 数据集是一个新颖的基于文本的数据集,用于评估机器在情境化心智理论(Theory of Mind, ToM)设置下的推理过程。该数据集包含9种不同的ToM评估任务,每种任务对应ATOMS[1]中的每种心理状态,以及1项现实检查任务,用于测试大型语言模型(LLMs)对世界的理解。需要注意的是,本实验作为概念验证,并不旨在涵盖机器ToM的整个范围,因为我们的案例研究远非详尽或系统。
数据集详情
- 任务类别: zero-shot-classification
- 语言: 英语(en)
- 标签: LLM, Theory-Of-Mind
- 数据集大小: 1K<n<10K
- 许可证: MIT
引用
如果您的研究使用了本数据集,请引用以下论文:
bibtex @inproceedings{ma2023towards, title={Towards A Holistic Landscape of Situated Theory of Mind in Large Language Models}, author={Ma, Ziqiao and Sansom, Jacob and Peng, Run and Chai, Joyce}, booktitle={Findings of the Association for Computational Linguistics: EMNLP 2023}, year={2023} }
搜集汇总
数据集介绍
构建方式
2D-ATOMS数据集由密歇根大学团队构建,旨在评估大型语言模型在情境化心智理论推理中的表现。该数据集基于ATOMS框架,系统性地涵盖了九种不同的心智状态评估任务,每种任务均对应一个独立的ToM评测维度。此外,数据集还包含一项现实检验任务,用于测试模型对世界理解的准确性。所有样本均采用文本形式呈现,并设计为零样本学习场景,以确保评估的公平性与泛化能力。数据集的构建过程严格遵循理论驱动原则,从心理学文献中提取核心概念,并转化为可量化的自然语言推理任务,从而为机器心智理论的系统性评测提供支撑。
特点
该数据集的核心特点在于其多维度的心智理论评测架构,能够全面刻画模型在情境化推理中的认知能力。不同于传统单一任务的ToM数据集,2D-ATOMS通过九种不同任务覆盖了信念、意图、情绪等心理状态,同时引入现实检验任务以区分模型对物理世界与心理世界的理解。数据集规模介于1千至1万样本之间,采用英文标注,适用于零样本分类任务。此外,其设计强调“情境化”特征,每个样本均嵌入丰富的上下文信息,要求模型在动态场景中推断他人心理状态,从而更贴近真实交互场景中的认知挑战。
使用方法
用户可通过HuggingFace Datasets库便捷地加载该数据集,使用一行代码即可实现数据获取:`from datasets import load_dataset; dataset = load_dataset("sled-umich/2D-ATOMS")`。加载后的数据集可直接用于零样本分类任务,用户无需额外标注即可评估模型的ToM推理能力。建议研究者将数据集划分为训练与测试子集,以验证模型在不同心智状态任务上的泛化性能。此外,数据集附带的现实检验任务可作为基线指标,用于区分模型对客观事实与主观心理的推理差异。使用时需注意,该数据集为研究导向,不适用于商业场景,引用时应参照提供的BibTeX格式进行学术致谢。
背景与挑战
背景概述
在人工智能领域中,心智理论(Theory of Mind, ToM)是衡量机器理解他人信念、意图与情感能力的重要维度。2023年,密歇根大学的研究团队由Ziqiao Ma、Jacob Sansom、Run Peng与Joyce Chai共同构建了2D-ATOMS数据集,旨在填补大型语言模型(LLM)在情境化心智理论评估方面的空白。该数据集基于ATOMS框架,针对九种不同心理状态设计了评估任务,并引入现实检验任务以考察模型对世界的理解。其核心研究问题在于能否通过文本驱动的情境测试,系统性地揭示LLM在模拟人类心智推理时的局限性。该工作发表于EMNLP 2023 Findings,为后续机器心智理论研究提供了可复现的基准,推动了认知科学与自然语言处理的交叉探索。
当前挑战
2D-ATOMS数据集面临的核心挑战在于心智理论评估的全面性与真实性。一方面,现有领域问题聚焦于LLM对他人心理状态的推断能力,但模型常依赖表面统计模式而非深层认知推理,导致在复杂社会情境中表现不稳定。另一方面,数据集构建过程中需应对任务设计的生态效度问题——如何通过有限文本案例覆盖人类心智理论的多样性,并避免测试数据与训练语料的重叠。此外,零样本设定下的评估要求模型具备强大的泛化能力,而当前LLM在区分信念、意图等抽象概念时仍存在混淆,这为构建高质量基准带来了持续性挑战。
常用场景
经典使用场景
2D-ATOMS数据集专为评估大语言模型在情境化心理理论推理中的能力而设计,其经典使用场景聚焦于零样本分类任务。通过模拟九种不同的心理状态评估任务与一项现实检验任务,该数据集能够系统性地探测模型在理解他人信念、意图与情感等心理状态时的推理深度,尤其适用于检验模型是否具备类似人类的心理理论能力,为机器认知研究提供了标准化评估框架。
解决学术问题
该数据集有效解决了当前大语言模型研究中缺乏精细化、多维度的情境化心理理论评估工具这一关键问题。传统评估方法多局限于一阶或二阶信念推断,而2D-ATOMS通过引入ATOMS框架中的多种心理状态类别,构建了更全面的评估体系,使研究者能够深入剖析模型在复杂社交情境中的推理缺陷,推动了认知科学与自然语言处理交叉领域的理论进展。
衍生相关工作
该数据集衍生了一系列关于大语言模型心理理论能力的经典工作,包括对其推理机制的可解释性分析、跨模型规模的能力对比研究,以及基于情境化心理理论评估的模型训练策略改进。这些工作不仅深化了对模型认知边界的理解,还启发了诸如多轮对话中的信念追踪、叙事理解中的意图归因等研究方向,形成了以2D-ATOMS为核心的学术脉络。
以上内容由遇见数据集搜集并总结生成


