Rehber-CoT-Science
收藏Hugging Face2025-12-24 更新2025-12-25 收录
下载链接:
https://huggingface.co/datasets/batuhanozkose/Rehber-CoT-Science
下载链接
链接失效反馈官方服务:
资源简介:
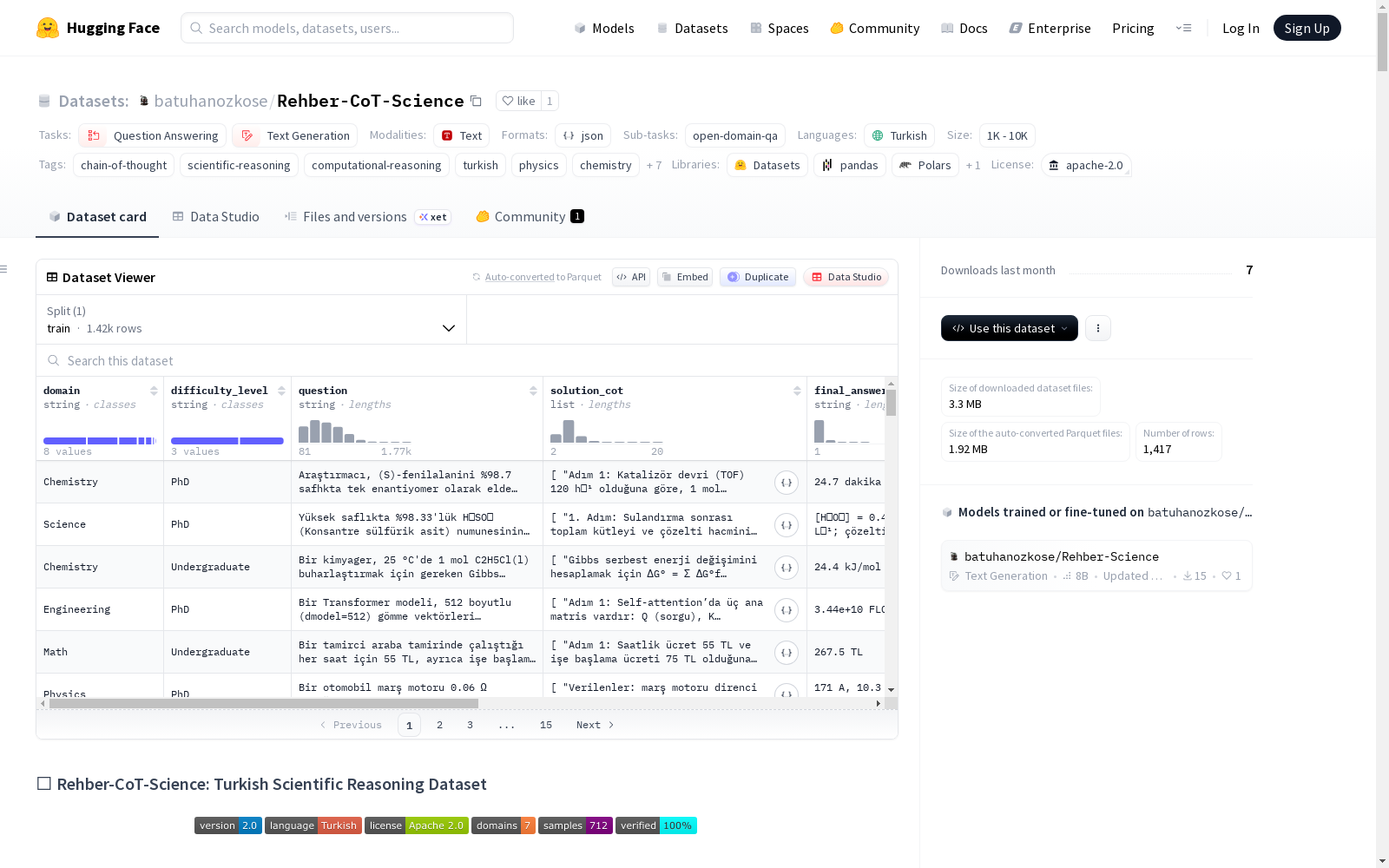
Rehber-CoT-Science是一个高质量的土耳其语科学推理数据集,旨在增强土耳其语在科学领域的计算推理能力。该数据集提供深入的科学解释、逐步推理链和可验证的Python代码。关键特征包括7个科学领域(物理、化学、生物、数学、工程、统计、科学)、增强的难度级别(博士和本科水平)、可验证的Python代码、多步推理链(平均5-7步)、解释性答案以及3阶段混合验证(数值、正则表达式和LLM-Judge)。数据集包含712个样本,质量评分为9.2/10,适用于教育和研究用途。
创建时间:
2025-12-22
原始信息汇总
Rehber-CoT-Science 数据集概述
基本信息
- 数据集名称: Rehber-CoT-Science
- 语言: 土耳其语 (tr)
- 许可证: Apache 2.0
- 版本: 2.0 (发布日期: 2024年12月24日)
- 样本数量: 712
- 任务类别: 问答、文本生成
- 标签: 思维链、科学推理、计算推理、土耳其语、物理学、化学、生物学、数学、工程学、统计学、代码生成、已验证代码、合成数据
核心特性
- 科学领域: 涵盖物理学、化学、生物学、数学、工程学、统计学和科学(跨学科)共7个领域。
- 难度等级: 包含博士水平(约75%)和本科水平(约25%)的问题。
- 思维链: 提供详细的多步骤解决方案链(平均5-7步)。
- 可验证代码: 每个问题均附带可执行且已验证的Python代码。
- 解释性答案: 提供直观的现实世界解释(v2新增字段)。
- 质量验证: 采用三阶段混合验证(数值匹配、正则表达式匹配、LLM判断)。
- 学术土耳其语: 使用专业的科学术语。
数据结构
数据集包含以下字段:
domain: 科学领域(字符串)difficulty_level: 难度等级(字符串)question: 问题文本(字符串)solution_cot: 逐步解决方案链(字符串序列)final_answer: 最终答案(字符串)python_code: 可执行的Python代码(字符串)explained_answer: 直观的现实世界解释(字符串)uuid: 唯一标识符(字符串)source_ref: 匿名化来源引用(字符串)
领域分布
| 领域 | 样本数量 | 描述 |
|---|---|---|
| 物理学 | ~180 | 经典力学、电磁学、热力学、量子物理 |
| 化学 | ~120 | 有机、无机、物理化学 |
| 生物学 | ~130 | 分子生物学、生态学、生理学 |
| 数学 | ~90 | 微积分、代数、数学建模 |
| 统计学 | ~70 | 概率、推断、假设检验 |
| 工程学 | ~80 | 电气、计算机、机械工程 |
| 科学 | ~42 | 跨学科科学问题 |
质量与统计
- 质量评分: 9.2/10
- 平均问题长度: ~350字符
- 平均解释长度: ~200词
- 验证成功率: 100%
- 验证方法分布: 数值匹配 (~42%)、正则表达式匹配 (~28%)、LLM判断 (~30%)
使用方法
可通过Hugging Face datasets库加载:
python
from datasets import load_dataset
dataset = load_dataset("batuhanozkose/Rehber-CoT-Science")
许可证与引用
- 许可证: Apache 2.0
- 引用: 可使用提供的BibTeX条目进行引用。
数据源
数据集源自16种精选材料,包括:
- 教科书: OpenStax Physics、Chemistry、Biology、Astronomy、Microbiology、Statistics。
- 研究论文: Attention Is All You Need、LoRA Paper、GPT技术报告、Llama-2 Paper、ResNet、Google Quantum Supremacy。
- 技术文档: MPU-6000数据手册、Raspberry Pi BCM2835、RISC-V ISA手册。
搜集汇总
数据集介绍
构建方式
在科学计算推理领域,构建高质量数据集需要严谨的方法论支撑。Rehber-CoT-Science数据集的构建采用了混合动态难度系统,以75%博士级和25%本科级的比例动态生成问题,确保覆盖不同深度的科学推理需求。其核心流程包括从精选的16种科学教科书、研究论文和技术文档中提取内容,通过PDF解析与文本分块后,利用先进的大语言模型生成问题与解答。生成过程严格遵循自包含原则,所有问题均提供完整解题所需信息,并实施了严格的反硬编码规则,确保附带的Python代码包含实际计算而非直接输出答案。整个流程通过并行处理系统高效运行,并经过三阶段混合验证,包括数值匹配、正则表达式匹配以及大语言模型科学判断,以保证答案的科学等效性。
特点
该数据集在科学推理数据资源中展现出多维度特色。其覆盖物理学、化学、生物学、数学、统计学、工程学及跨学科科学七大领域,共计712个样本,其中约75%为博士级复杂问题,25%为本科级基础应用,形成了深度与广度兼备的学科分布。每个样本均包含土耳其语问题描述、多步思维链解答、可验证的Python代码以及直观的现实世界解释,构成了四位一体的完整推理单元。思维链平均包含5至7个步骤,细致拆解科学问题的求解逻辑;Python代码均通过沙箱执行验证,确保计算正确性;新增的explained_answer字段以通俗语言阐释抽象概念背后的物理直觉与实际意义,显著提升了数据集的教育价值。数据集整体质量评分达9.2分,在科学深度、推理链质量和代码可靠性方面均表现优异。
使用方法
在自然语言处理与教育技术研究中,该数据集为土耳其语科学推理模型的训练与评估提供了标准化资源。研究者可通过Hugging Face的datasets库直接加载数据集,支持加载最新版本或指定历史分支。数据集中每个样本的结构化字段便于针对不同任务进行格式化处理,例如将思维链步骤、Python代码和最终答案组合为训练文本,用于微调大语言模型的链式推理能力。其可执行的Python代码为验证模型生成的计算结果提供了客观基准,而多难度层级的设计使得模型性能评估能够区分基础概念应用与高级科学问题求解能力。该资源特别适用于开发土耳其语科学辅导系统、增强大语言模型在STEM领域的推理准确性,以及推动计算思维与科学教育交叉领域的研究进展。
背景与挑战
背景概述
Rehber-CoT-Science数据集于2025年12月由研究人员Batuhan Ozkose创建并发布,旨在应对土耳其语科学计算推理领域的数据稀缺问题。该数据集聚焦于链式思维推理能力的增强,覆盖物理学、化学、生物学、数学、工程学、统计学及跨学科科学等七大领域,核心研究问题在于如何构建高质量、多步骤的科学问题求解资源,以支持土耳其语大型语言模型在复杂科学任务中的训练与评估。其特色在于整合了可验证的Python代码、详细的推理链条以及直观的现实世界解释,对土耳其语自然语言处理及科学教育领域具有显著的推动作用,为相关模型的微调与基准测试提供了重要支撑。
当前挑战
该数据集致力于解决科学问题解答与计算推理领域的核心挑战,即如何促使模型进行多步骤、可解释的逻辑推演,而非仅生成最终答案。构建过程中的挑战具体体现在:首先,确保生成内容的科学准确性与深度,需从权威教科书及研究论文中提取并转化复杂概念;其次,实施严格的质量控制机制,包括三阶段混合验证与反硬编码规则,以杜绝惰性代码并保证代码可执行性;此外,维护土耳其语学术术语的规范性与一致性,以及通过语义去重避免内容冗余,均为数据集构建的关键难点。
常用场景
经典使用场景
在科学计算推理领域,Rehber-CoT-Science数据集为土耳其语科学问题求解提供了标准化评估框架。该数据集最经典的应用场景在于训练和评估大语言模型的多步推理能力,特别是针对物理学、化学、生物学等七个核心科学领域的复杂问题。研究者利用其包含的思维链标注和可验证Python代码,能够系统性地测试模型从问题理解、分步推导到最终求解的全过程,为土耳其语科学教育智能化奠定了数据基础。
实际应用
在实际应用层面,该数据集为土耳其语科学教育辅助系统开发提供了核心训练素材。教育科技公司可基于其结构化标注构建智能解题助手,帮助学生理解复杂科学问题的推导过程。科研机构则能利用其可执行代码特性,开发自动化科学计算工具。数据集的多领域覆盖特性还支持跨学科知识融合应用的开发,为土耳其语科学社区的数字化转型提供了关键基础设施。
衍生相关工作
围绕该数据集已衍生出多个重要研究方向,包括土耳其语科学大语言模型微调框架的构建,以及基于思维链的跨语言知识迁移方法研究。部分工作专注于扩展数据集的领域覆盖范围,开发工程学与统计学等专业领域的增强版本。另有研究利用其验证机制设计新型评估指标,推动科学推理评估从结果导向向过程导向的范式转变,促进了计算推理与科学教育的深度融合。
以上内容由遇见数据集搜集并总结生成


