WebPerson
收藏arXiv2025-09-11 更新2025-09-13 收录
下载链接:
https://huggingface.co/datasets/Kaichengalex/WebPerson-5M
下载链接
链接失效反馈官方服务:
资源简介:
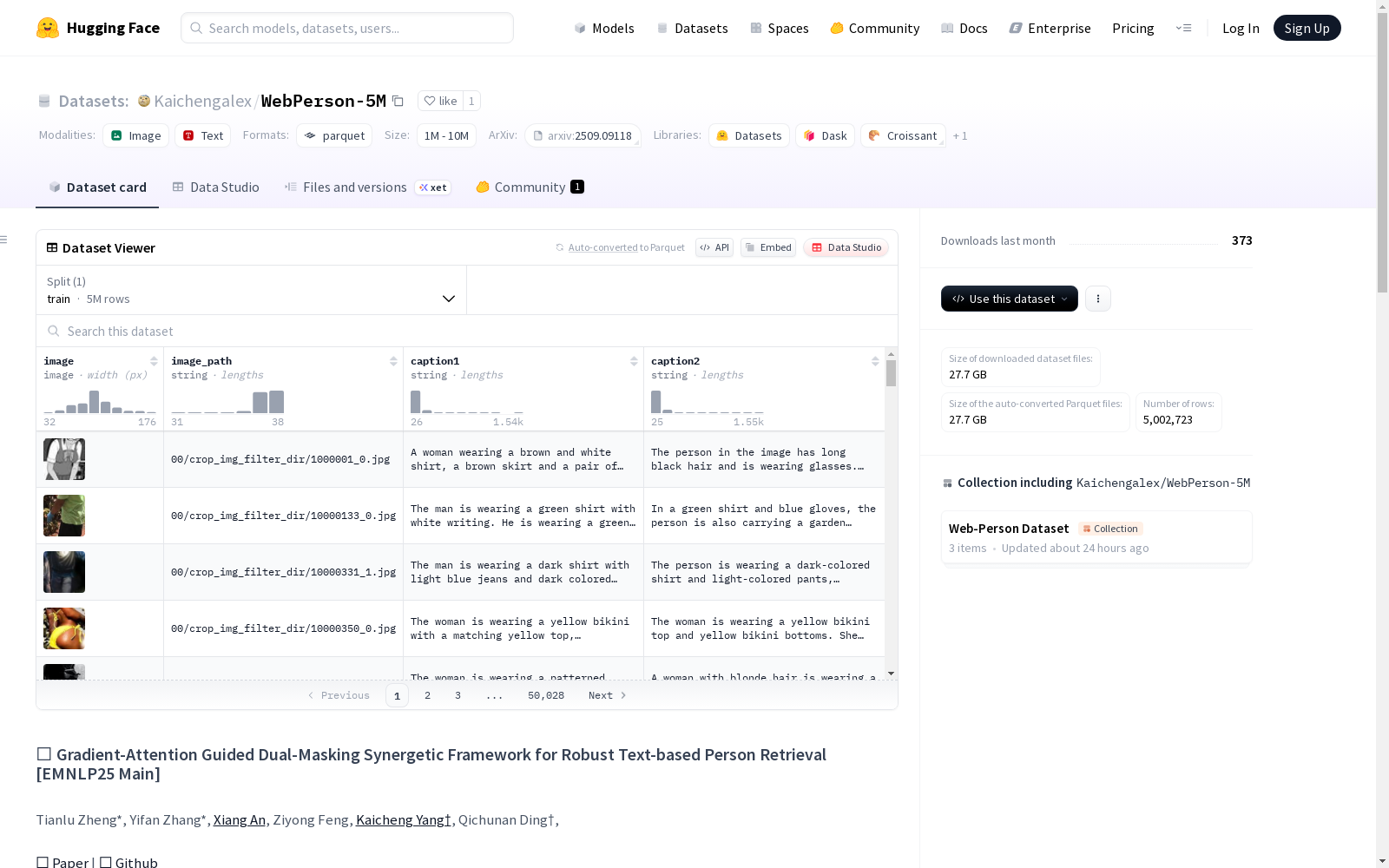
WebPerson是一个大型的人物中心数据集,由5百万高质量的人像文本对组成,来源于网络图像。数据集通过利用多模态大语言模型(MLLMs)的上下文学习能力,自动过滤和描述网络来源的图像。创建过程包括使用YOLOv11模型检测人体并提取边界框坐标,然后使用YOLOv11-Pose模型验证姿态完整性。数据集适用于人物检索任务,旨在解决现有数据集规模小、数据噪声大、难以学习细粒度语义表示的问题。
WebPerson is a large-scale person-centric dataset composed of 5 million high-quality image-text pairs sourced from web images. This dataset automatically filters and describes web-sourced images by leveraging the in-context learning capability of Multimodal Large Language Models (MLLMs). Its construction process involves using the YOLOv11 model to detect human bodies and extract bounding box coordinates, followed by using the YOLOv11-Pose model to verify the integrity of human poses. This dataset is applicable to person retrieval tasks, aiming to address the common issues of existing datasets including small scale, high data noise, and difficulty in learning fine-grained semantic representations.
提供机构:
东北大学, 华南理工大学, DeepGlint
创建时间:
2025-09-11
原始信息汇总
WebPerson-5M 数据集概述
数据集基本信息
- 名称:WebPerson-5M
- 来源:从COYO700M数据集中筛选
- 数量:5,002,723个样本
- 下载大小:27,023,995字节
- 数据集大小:5,002,723
- 许可协议:CC-BY-4.0
数据特征
- 图像数据:image(图像格式)
- 图像路径:image_path(字符串格式)
- 描述文本1:caption1(字符串格式)
- 描述文本2:caption2(字符串格式)
数据划分
- 训练集:5,002,723个样本
数据筛选流程
人物中心图像筛选
- 使用YOLOv11检测人体并提取边界框
- 筛选标准:
- 短边≥90像素
- 宽高比在1:2至1:4之间
- 人体检测置信度>85%
- 使用YOLOv11-Pose进一步筛选:
- 至少8个可见关键点
- 至少包含一个髋部和两个头部关键点
合成描述生成
- 使用Qwen2.5-72B-Instruct将CUHK-PEDES、ICFG-PEDES和RSTPReid的描述转换为结构化模板
- 使用OPENCLIP ViT-bigG/14提取文本嵌入,应用k-means聚类
- 从每个聚类中选择最具代表性的模板和五个随机样本
- 使用Qwen2.5-72B-Instruct多样化模板
- 最终生成1,000个高质量模板
- 使用MLLMs通过上下文学习生成描述:为每张图像分配随机模板,Qwen2.5-VL模型生成结构化描述
相关资源
- 论文:https://arxiv.org/pdf/2509.09118
- 代码库:https://github.com/Multimodal-Representation-Learning-MRL/GA-DMS
引用信息
latex @misc{zheng2025gradientattentionguideddualmaskingsynergetic, title={Gradient-Attention Guided Dual-Masking Synergetic Framework for Robust Text-based Person Retrieval}, author={Tianlu Zheng and Yifan Zhang and Xiang An and Ziyong Feng and Kaicheng Yang and Qichuan Ding}, year={2025}, eprint={2509.09118}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2509.09118}, }
搜集汇总
数据集介绍
构建方式
在人物表征学习领域,数据稀缺与噪声干扰长期制约模型性能。WebPerson数据集通过创新流程构建:首先从COYO-700M网络源图像中筛选高质量人物中心图像,采用YOLOv11检测模型设定分辨率、宽高比及置信度阈值,并结合姿态关键点验证确保人体完整性;随后基于多模态大语言模型的上下文学习能力,将现有数据集的标注转化为结构化模板,通过聚类筛选和模板增强生成多样化文本描述,最终形成500万对高质量图文数据。
特点
该数据集显著特点体现在三方面:规模上涵盖500万图像与1000万文本描述,是当前最大规模自动生成的人物中心图文数据集;质量上通过严格过滤流程确保图像清晰度与文本准确性,噪声控制优于同期生成式数据集;多样性上融合网络源图像的场景、视角、服饰等多维变化,配合大语言模型生成的精细化属性描述,为细粒度语义学习提供丰富表征空间。
使用方法
数据集适用于人物检索任务的预训练与微调场景。研究者可加载图像-文本对至CLIP架构模型,通过对比学习实现跨模态对齐;针对噪声敏感任务,建议采用梯度注意力引导的掩码策略,动态过滤文本噪声令牌并强化信息令牌预测。下游应用时,可直接迁移预训练特征至CUHK-PEDES等基准数据集,或通过微调适配特定场景的检索需求,显著提升模型对服饰、配件等局部属性的感知能力。
背景与挑战
背景概述
WebPerson数据集由东北大学与深度视觉科技(DeepGlin)等机构于2025年联合发布,旨在解决基于文本的行人检索任务中大规模高质量数据稀缺的核心问题。该数据集包含500万张网络爬取的行人中心图像及其文本描述,通过多模态大语言模型(MLLMs)自动过滤与标注生成。其创新性在于利用上下文学习能力构建抗噪声数据管道,显著提升了行人表征学习的泛化能力,为跨模态预训练模型提供了关键数据支撑。
当前挑战
WebPerson需应对两大挑战:其一为领域问题挑战,即细粒度语义对齐困难,传统全局对比学习难以捕捉局部特征(如服饰纹理),导致相似行人区分能力不足;其二为构建过程挑战,包括网络源图像噪声过滤、多模态大语言模型生成文本的语义偏差校正,以及大规模数据标注中的计算资源与质量平衡问题。
常用场景
经典使用场景
在智能监控与安防领域,WebPerson数据集为基于文本的行人检索任务提供了关键支撑。该数据集通过大规模网络图像与高质量文本描述的精准配对,有效解决了传统方法在跨模态匹配中的语义鸿沟问题。其典型应用场景包括通过自然语言描述快速定位特定行人图像,显著提升了监控系统中跨摄像头追踪的准确性与效率。
解决学术问题
WebPerson数据集主要解决了行人重识别领域的两大学术难题:一是缓解了人工标注数据规模受限导致的模型泛化能力不足,通过500万高质量图像-文本对突破了数据稀缺性瓶颈;二是针对多模态预训练中噪声文本干扰问题,提出了梯度注意力引导的掩码机制,显著提升了细粒度语义对齐的精度,为跨模态表示学习提供了新的理论范式。
衍生相关工作
基于WebPerson数据集衍生了多项创新性研究,包括梯度注意力双掩码协同框架(GA-DMS)和噪声抵抗型数据构建管道。这些工作推动了跨模态对齐技术的发展,其中掩码令牌预测目标机制被后续研究广泛采纳,显著提升了文本-图像匹配任务的性能。相关技术方案已成为行人检索领域的新基准,促进了多模态学习范式的迭代升级。
以上内容由遇见数据集搜集并总结生成


