COSMUS
收藏Hugging Face2025-06-10 更新2025-06-11 收录
下载链接:
https://huggingface.co/datasets/YShynkarov/COSMUS
下载链接
链接失效反馈官方服务:
资源简介:
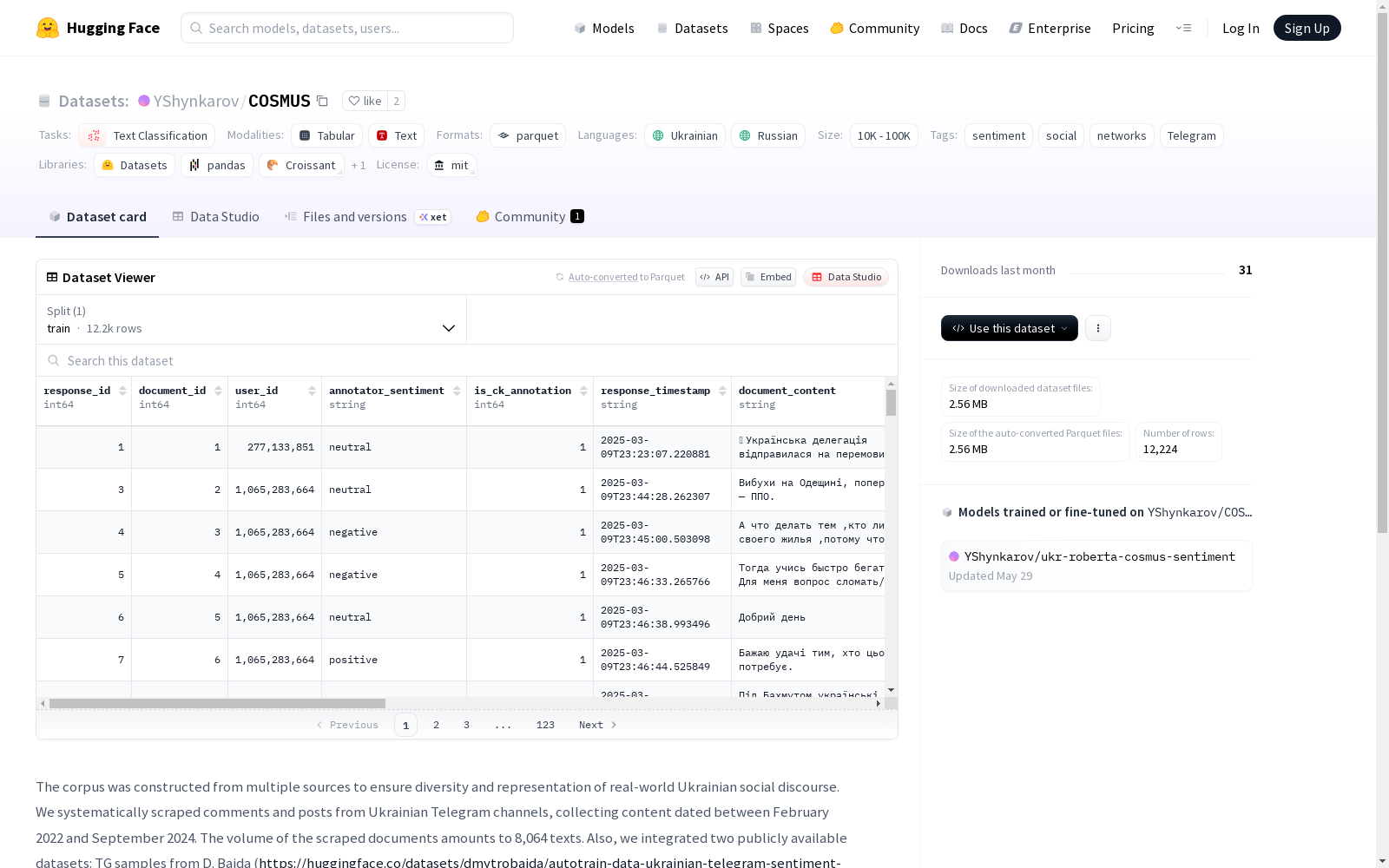
该数据集是由多个来源构建而成,旨在确保多样性和代表性,反映真实世界的乌克兰社交话语。它包括从乌克兰Telegram频道抓取的评论和帖子,时间跨度为2022年2月至2024年9月。数据集还整合了两个公开可用的数据集:D. Baida的Telegram样本和Yakaboo书评,以及Hotline.ua的1000条产品评论,以丰富内容领域。经过删除重复和无关内容后,最终语料库包含了12,224条涉及政治、政府服务、娱乐、日常生活和消费者评论等不同主题的文本。所有非乌克兰语和俄语的文本都被过滤掉了。五种情感类别:积极、消极、中性、混合。
创建时间:
2025-05-30
搜集汇总
数据集介绍
构建方式
在社交媒体情感分析领域,COSMUS数据集的构建体现了多源异构数据的整合策略。通过系统爬取2022年2月至2024年9月期间乌克兰Telegram频道的用户评论与帖子,获得8064条原始文本,并融合D.Baida提供的3000条Telegram样本、1000条Yakaboo图书评论及1000条Hotline.ua商品评价。经过去重与模板内容清理,最终形成12224条覆盖政治、民生、娱乐等多领域的双语语料,非乌俄语种文本因统计显著性不足被剔除。
特点
该数据集显著特征在于其真实反映乌克兰社会话语的多样性,包含乌克兰语与俄语双语内容,涵盖社交媒体、商品评价等多维度场景。标注体系采用四分类情感维度(积极、消极、中立与混合),其中混合类别精准捕捉了人类情感表达的复杂性。所有文本由五位乌俄双语母语者参与标注,确保文化语境与语言细微差别的准确性,为跨语言情感分析提供高质量基准。
使用方法
研究者可借助该数据集开展乌克兰语与俄语的情感分类模型训练,尤其适用于社交媒体文本的多领域迁移学习。预处理时需注意保留原文本的编码特征与特殊符号,标注文件采用标准JSON格式存储。建议通过分层抽样划分训练集与测试集,以保持领域分布均衡。该数据集兼容Transformer架构,可直接接入HuggingFace生态系统进行微调实验。
背景与挑战
背景概述
COSMUS数据集由乌克兰研究团队于2024年构建,专注于社交媒体文本情感分析领域。该数据集整合了Telegram频道内容与公开评论数据,涵盖2022年至2024年乌克兰社会话语,包含政治、民生、消费等多领域文本。其核心研究在于通过双语(乌克兰语与俄语)情感标注,捕捉冲突时期社会情绪动态,为东欧地区NLP研究提供了重要基准数据。
当前挑战
该数据集需解决社交媒体文本中情感极性模糊与跨文化语境解读的难题,例如混合情感文本的分类一致性。构建过程中面临多源数据融合的技术挑战,包括重复内容去重、非乌俄语料过滤以及双语标注者间一致性维护,需通过严格标注协议确保四分类体系的可靠性。
常用场景
经典使用场景
在社交媒体情感分析领域,COSMUS数据集凭借其乌克兰语和俄语双语标注特性,为研究者提供了丰富的多源文本资源。该数据集广泛应用于情感极性分类模型的训练与评估,特别是在跨语言情感迁移学习和低资源语言处理研究中展现出色性能。其覆盖政治、消费评论等多领域内容,有效支撑了细粒度情感分类任务的实验需求。
实际应用
在实际应用层面,COSMUS支撑了乌克兰政府部门的社会情绪监测系统开发,助力公共政策效果评估。商业机构利用其消费者评论数据优化产品推荐算法,而新闻媒体则借助该数据集构建假新闻检测模型。这些应用显著提升了东欧地区数字化服务的情感智能水平,为多语言社会计算提供了实践范本。
衍生相关工作
基于该数据集衍生的经典工作包括UA-SentimentBERT跨语言预训练模型和Telegram舆情监测框架UASocialMeter。研究者还开发了融合政治语言学特征的混合分类器,这些成果先后发表于ACL和EMNLP等顶级会议。后续研究进一步扩展了数据集的时空维度,构建了动态情感演化图谱,推动了社会计算与NLP领域的交叉创新。
以上内容由遇见数据集搜集并总结生成


