VMReal
收藏arXiv2025-12-13 更新2025-12-16 收录
下载链接:
https://pq-yang.github.io/projects/MatAnyone2/
下载链接
链接失效反馈官方服务:
资源简介:
VMReal是由南洋理工大学与商汤科技联合构建的大规模真实世界视频抠像数据集,包含28,000个视频片段和240万帧标注数据,覆盖多样化场景、光照条件和运动模式。该数据集通过自动化双分支标注流程生成,结合了视频抠像模型的语义稳定性和图像抠像模型的边界细节优势,采用创新的抠像质量评估器(MQE)进行像素级质量仲裁。作为当前领域规模最大且唯一基于真实视频的标注集,VMReal旨在解决合成数据与真实场景的域差距问题,推动视频抠像在视觉特效和影视编辑中的应用突破。
VMReal is a large-scale real-world video matting dataset jointly developed by Nanyang Technological University and SenseTime. Comprising 28,000 video clips and 2.4 million annotated frames, it covers diverse scenarios, lighting conditions and motion patterns. This dataset is generated via an automated two-branch annotation pipeline, which combines the semantic stability of video matting models and the edge detail advantages of image matting models, and adopts an innovative matting quality evaluator (MQE) for pixel-level quality arbitration. As the largest and only real-video-based annotated dataset in the current field, VMReal aims to address the domain gap between synthetic data and real-world scenarios, and promote application breakthroughs of video matting in visual effects and film and television editing.
提供机构:
南洋理工大学 S-Lab 和商汤科技研究院
创建时间:
2025-12-13
原始信息汇总
MatAnyone 2 数据集概述
数据集名称
MatAnyone 2
核心贡献
- 提出了一个实用的人类视频抠图框架,能够保留精细细节并增强在挑战性真实世界条件下的鲁棒性。
- 引入了一个学习的抠图质量评估器,可在没有真实标注的情况下评估alpha遮罩的语义和边界质量。
- 构建了一个大规模的真实世界视频抠图数据集 VMReal。
数据集详情
VMReal 数据集
- 规模:包含28K个视频片段和2.4M帧。
- 特点:大规模、真实世界。
- 标注方式:通过自动化双分支标注流程构建。该流程结合了两个互补的标注分支:
- 时间稳定的BV分支:提供基础标注。
- 细节保留的BI分支:提供精细的边界细节。
- 标注结果:每个alpha标签都配有一个二值评估图。
方法创新
- 训练数据:使用真实世界的 VMReal 数据集进行训练。
- 损失函数:
- 在可靠像素上使用掩码抠图损失 LmatM。
- 学习的抠图质量评估器提供 Leval 损失,用于监督核心和边界区域。
- 训练策略:针对长视频中的大外观变化,引入了参考帧策略,以纳入超出局部窗口的长范围帧线索,提高鲁棒性且无需额外内存成本。
相关资源链接
- 论文:https://arxiv.org/abs/2512.11782
- 代码:即将发布
- 演示:即将发布
- 数据集:即将发布
- 视频:https://pq-yang.github.io/projects/MatAnyone2/
搜集汇总
数据集介绍
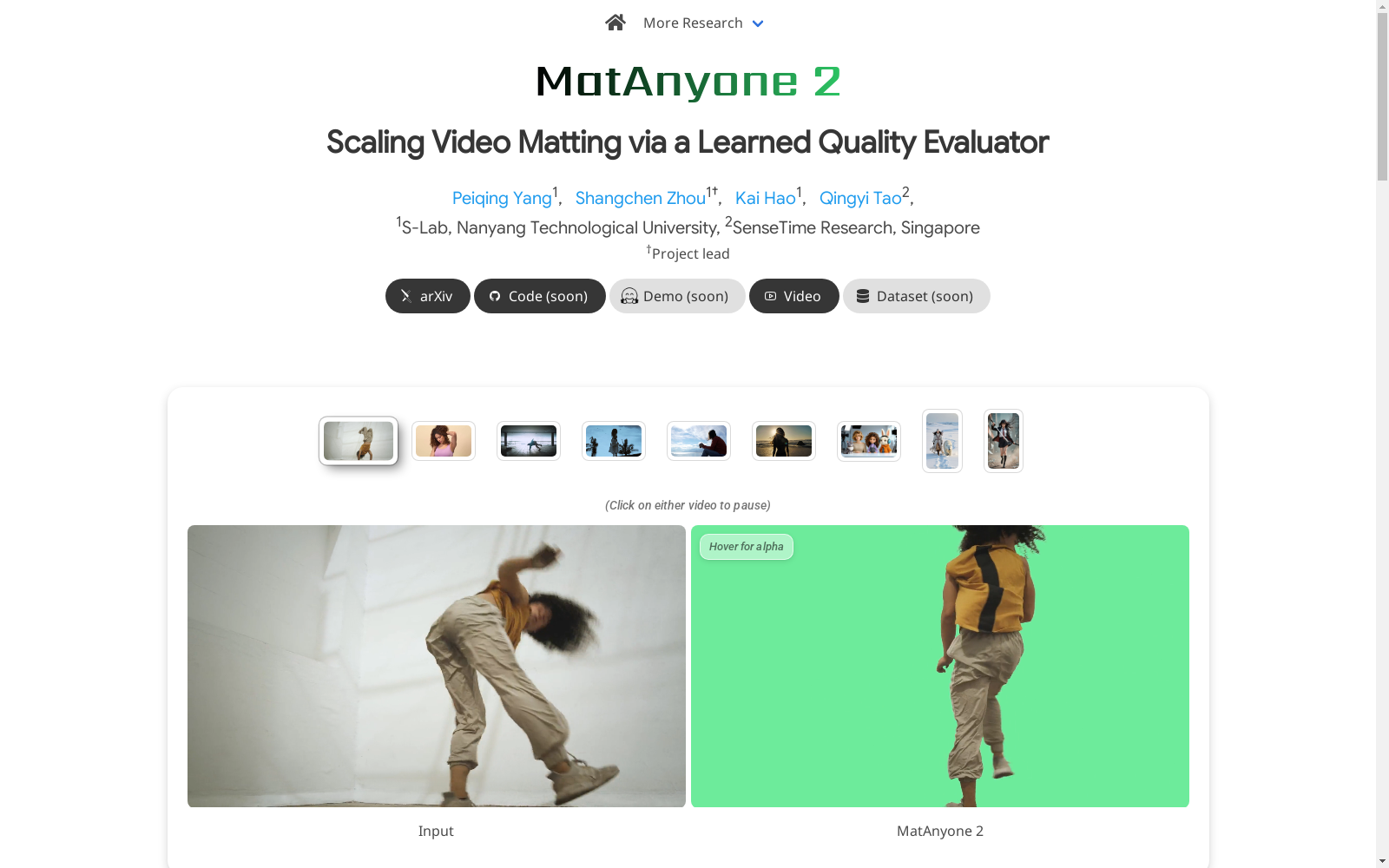
构建方式
VMReal数据集的构建依托于一种创新的自动化双分支标注流程。该流程巧妙融合了视频抠图模型与图像抠图模型的优势,前者擅长维持语义稳定性与时间一致性,后者则能捕捉精细的边界细节。核心在于引入一个无需真实标注即可评估抠图质量的Matting Quality Evaluator(MQE),它作为质量仲裁者,对两个分支的预测结果进行像素级评估,生成可靠性评估图。通过选择性融合视频分支的稳定语义与图像分支的高质量细节,最终自动化生成了包含约28K个视频片段、总计240万帧的大规模真实世界视频抠图数据集。
使用方法
VMReal数据集为视频抠图模型的训练提供了统一的监督范式。数据以三元组⟨Irgb, α, Meval⟩的形式组织,其中Meval标识了每个像素的可靠性。在训练过程中,抠图损失仅作用于被标记为可靠的区域,从而确保模型专注于高置信度的监督信号。这种设计使得模型能够充分利用大规模、异构的真实世界数据源,避免了传统方法中因联合分割数据训练而导致的边界细节丢失问题。数据集可直接用于训练端到端的视频抠图网络,显著提升模型在真实复杂场景下的语义准确性、边界保真度与时间一致性。
背景与挑战
背景概述
VMReal数据集是视频抠图领域的一项突破性成果,由南洋理工大学S-Lab与商汤科技新加坡研究院的研究团队于2025年提出。该数据集旨在解决视频抠图任务中长期存在的数据稀缺与真实性不足问题,核心研究聚焦于如何构建大规模、高质量的真实世界视频抠图标注数据,以推动模型在语义稳定性与边界细节保真度上的双重提升。VMReal包含约2.8万段视频剪辑与240万帧标注,其规模远超先前主流数据集,为视频抠图模型的训练与评估提供了前所未有的真实场景支持,显著提升了模型在复杂光照、动态运动等实际应用中的泛化能力。
当前挑战
视频抠图领域面临的核心挑战在于如何精确分离前景与背景,特别是在物体边界处(如发丝、透明材质)生成细腻且时间一致的Alpha蒙版。传统方法常受限于合成数据与真实视频间的域差异,导致模型在真实场景中表现不佳。在构建VMReal数据集过程中,研究团队需克服两大难题:一是缺乏大规模真实标注数据,手动标注视频Alpha蒙版成本极高且难以保证一致性;二是如何有效融合视频抠图模型的时序稳定性与图像抠图模型的边界细节优势,避免因直接结合而产生语义漂移或边界伪影。为此,团队设计了基于学习化抠图质量评估器的双分支自动标注流程,通过像素级质量仲裁实现高质量标注的规模化生成。
常用场景
经典使用场景
在视频抠图领域,VMReal数据集作为首个大规模真实世界视频抠图数据集,其经典使用场景在于为视频抠图模型的训练与评估提供高质量、多样化的监督信号。该数据集包含约28,000个视频片段和240万帧标注,覆盖了复杂光照、动态运动及多人物交互等真实场景,使得研究者能够基于此训练出具备强泛化能力的模型,有效缓解了以往合成数据导致的域差距问题。
解决学术问题
VMReal数据集解决了视频抠图研究中长期存在的训练数据规模不足、真实性与质量有限的核心学术问题。通过引入基于学习的抠图质量评估器(MQE)驱动的自动化标注流程,该数据集实现了对语义稳定性与边界细节的双重优化,从而为模型提供了兼具时序一致性与高保真细节的监督信号。这不仅显著提升了模型在复杂真实场景下的语义准确性与边界精细度,还推动了视频抠图从依赖合成数据向真实世界应用的范式转变。
实际应用
在实际应用层面,VMReal数据集为影视特效、视频编辑及实时交互系统提供了关键技术支持。基于该数据集训练的模型能够高效处理真实视频中的人物抠图任务,例如在动态光照、复杂背景及快速运动条件下仍能保持清晰的发丝细节与自然过渡。这直接赋能了专业级视频后期制作、虚拟直播背景替换以及移动端实时抠图应用,大幅提升了视觉内容的制作效率与质量。
数据集最近研究
最新研究方向
在视频抠图领域,VMReal数据集的推出标志着该领域在数据规模与真实性方面取得了突破性进展。该数据集通过引入学习的抠图质量评估器(MQE),实现了无需真实标注即可对预测的alpha遮罩进行语义与边界质量的像素级评估。这一创新不仅解决了传统合成数据存在的域鸿沟问题,还通过双分支标注流程,融合了视频抠图模型的语义稳定性与图像抠图模型的精细边界细节,从而构建了包含28K视频片段和240万帧的大规模真实世界视频抠图数据集。VMReal的建立推动了视频抠图模型在复杂光照、动态场景下的泛化能力,为生成式视频编辑、视觉特效等应用提供了高质量的训练基础,并促进了基于扩散模型的视频抠图方法与参考帧训练策略等前沿研究方向的发展。
相关研究论文
- 1MatAnyone 2: Scaling Video Matting via a Learned Quality Evaluator南洋理工大学 S-Lab 和商汤科技研究院 · 2025年
以上内容由遇见数据集搜集并总结生成


