opendatalab/SA-RxnDiagram-15k
收藏Hugging Face2026-04-02 更新2026-04-05 收录
下载链接:
https://hf-mirror.com/datasets/opendatalab/SA-RxnDiagram-15k
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-nc-4.0
language:
- en
tags:
- biology
- chemistry
- cheminformatics
- computer-vision
- object-detection
- image
size_categories:
- 10K<n<100K
pretty_name: SA-RxnDiagram-15k
configs:
- config_name: default
data_files:
- split: train
path: train_set.zip
- split: test
path: test_set.zip
---
# U-RxnDiagram-15k Dataset (Sci-Align)
## 🌌 The Sciverse Data Foundation
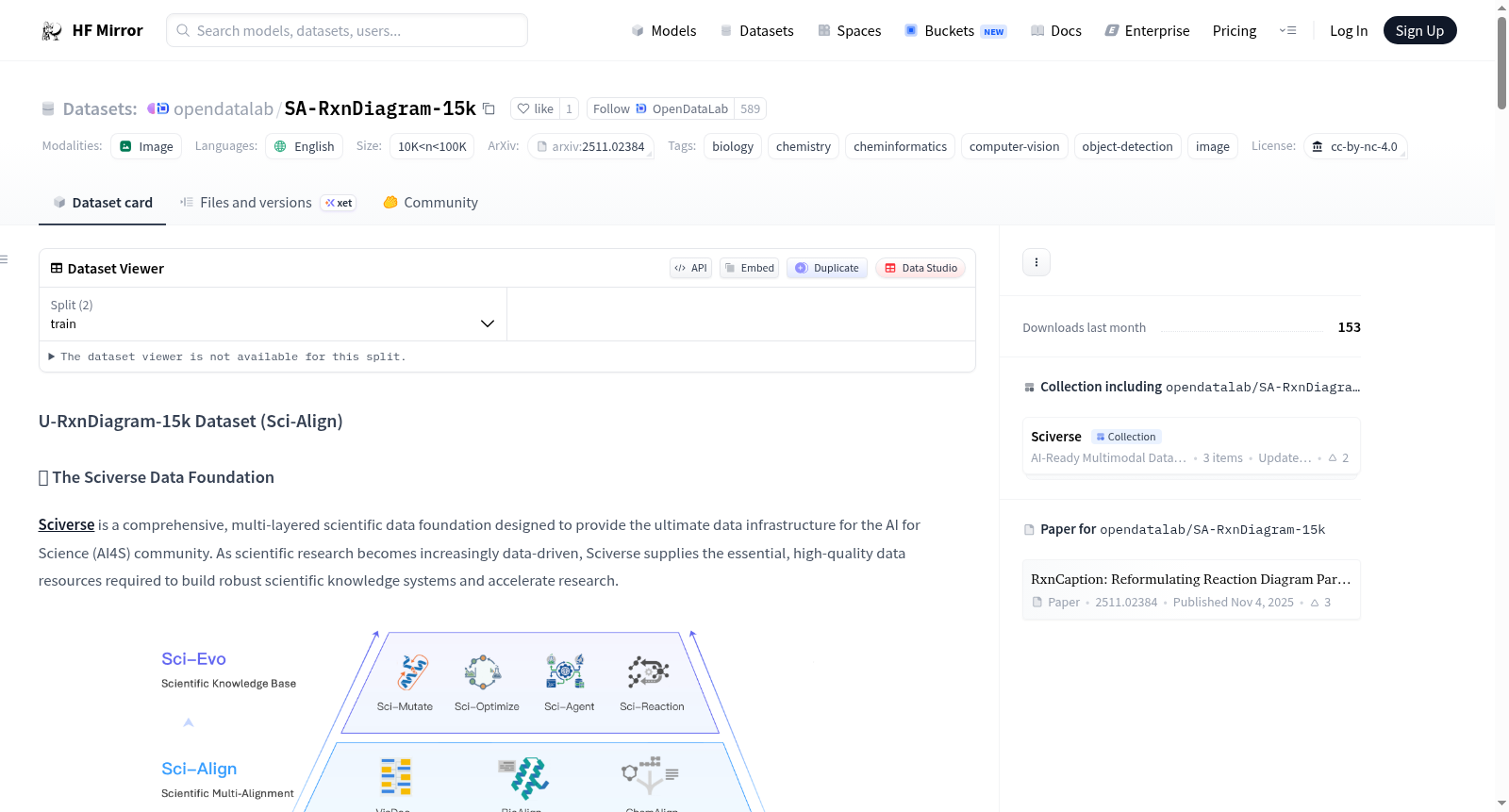
[**Sciverse**](https://Sciverse.opendatalab.com/) is a comprehensive, multi-layered scientific data foundation designed to provide the ultimate data infrastructure for the AI for Science (AI4S) community. As scientific research becomes increasingly data-driven, Sciverse supplies the essential, high-quality data resources required to build robust scientific knowledge systems and accelerate research.
<p align="center">
<img src="https://cdn-uploads.huggingface.co/production/uploads/643e60d96db6ba8c5ee177ad/ugVRh4ckRm4a-fsc5k7n1.png" alt="Sciverse" width="700">
</p>
Sciverse consists of three core data pillars:
* **Sci-Base (Scientific Knowledge Base Data):** The massive-scale, purely objective scientific knowledge base. Comprising over 25 million deeply cleaned and parsed Open Access documents, it provides the comprehensive, purely factual scientific corpus that serves as the universal foundation for all downstream scientific applications.
* **Sci-Align (Scientific Multi-Alignment Data):** A highly curated, structured dataset mapping direct scientific relationships and precise factual alignments. It focuses on well-defined entity interactions—such as mapping specific chemical reaction pathways (e.g., via SMILES strings), condition-to-result pairings, and standardized structural descriptions. This layer provides the structured factual alignment needed for models to accurately connect and ground foundational scientific concepts.
* **Sci-Evo (Scientific Evolution Data):** A multi-layered, high-density reasoning dataset designed for complex problem-solving and deep scientific evaluation. Going beyond basic facts, this layer captures deep, causal descriptions—detailing not just the 'what', but the underlying reasoning for specific experimental designs, multi-step mathematical derivations, and the complex logic of how modifying specific conditions alters outcomes. It is constructed to rigorously measure a model's advanced scientific reasoning accuracy and logical depth.
---
## U-RxnDiagram-15k Dataset Overview (Sci-Align)
U-RxnDiagram-15k Dataset is a large-scale dataset specifically designed for chemical reaction diagram parsing, containing chemical reaction images extracted from scientific literature PDFs along with detailed annotations. This dataset aims to support research in cheminformatics, document analysis, and computer vision fields.
## Dataset Statistics
- **Total Images**: 15,400 images
- Train set: 15,000 images
- Test set: 400 images
- **Total Reactions**: 48,255 reactions
- Train set: 45,426 reactions
- Test set: 2,829 reactions
- **Data Source**: Scientific literature PDF files
- **Image Format**: PNG
- **Total Annotations**: Approximately 165,468 annotation instances
## Dataset Structure
```
U-RxnDiagram-15k/
├── train_set/
│ ├── ground_truth.json # Train set annotation file
│ └── images/ # Train set image directory
└── test_set/
├── ground_truth.json # Test set annotation file
└── images/ # Test set image directory
```
## Annotation Category Definitions
The dataset defines 4 main categories, each containing multiple fine-grained attributes:
### 1. Structure - category_id: 1
- **P-reactant**: Reactant molecular structures
- **P-product**: Product molecular structures
- **P-reaction condition**: Reaction condition molecular structures
### 2. Text - category_id: 2
- **T-reaction condition**: Reaction condition text
- **T-reactant**: Reactant text
- **T-product**: Product text
### 3. Identifier - category_id: 3
- Chemical identifiers and numbers
### 4. Supplement - category_id: 4
- Other supplementary information
## Annotation Statistics
### Train Set
| Attribute Type | Annotation Count | Percentage |
|---------------|------------------|------------|
| T-reaction condition | 56,377 | 35.84% |
| P-reactant | 31,779 | 20.20% |
| P-product | 30,808 | 28.79% |
| T-reactant | 6,433 | 6.02% |
| T-product | 3,804 | 2.42% |
| P-reaction condition | 6,230 | 3.96% |
### Test Set
| Attribute Type | Annotation Count | Percentage |
|---------------|------------------|------------|
| T-reaction condition | 3,011 | 36.92% |
| P-reactant | 1,521 | 18.65% |
| P-product | 2,348 | 28.79% |
| T-reactant | 491 | 6.02% |
| T-product | 388 | 4.76% |
| P-reaction condition | 397 | 4.87% |
## Data Format
### Image File Naming
Image filenames are hashed (SHA-256, first 8 hex chars).
Example: `a1b2c3d4.png`.
### Annotation File Format (ground_truth.json)
The annotation file follows COCO format and contains the following main fields:
```json
{
"licenses": [...],
"info": {
"description": "A dataset for chemical visual diagram analysis",
"version": "v1",
"year": "2025"
},
"categories": [
{"id": 1, "name": "structure"},
{"id": 2, "name": "text"},
{"id": 3, "name": "identifier"},
{"id": 4, "name": "supplement"}
],
"images": [
{
"id": 2,
"class": "figure",
"confidence": 0.9148465991020203,
"bbox": [x1, y1, x2, y2],
"original_id": 0,
"width": 1008.7104797363281,
"height": 471.88232421875,
"file_name": "ays765k9.png",
"bboxes": [
{
"id": 0,
"bbox": [x, y, width, height],
"category_id": 1,
"category": "P",
"attribute": "P-reactants",
"region_id": ["akzkPsql"]
}
]
}
]
}
```
### Annotation Field Descriptions
- **id**: Unique annotation identifier
- **bbox**: Bounding box coordinates [x1, y1, x2, y2] for image-level bbox, [x, y, width, height] for bboxes list
- **category_id**: Category ID (1-4)
- **category**: Category abbreviation (P=Structure, T=Text)
- **attribute**: Specific attribute name
- **region_id**: List of region identifiers
## Use Cases
This dataset is suitable for the following research tasks:
1. **Chemical Structure Recognition**: Identify and locate molecular structures in chemical reactions
2. **Text Information Extraction**: Extract text information from chemical diagrams
3. **Reaction Condition Analysis**: Identify and analyze reaction conditions
4. **Document Understanding**: Understand chemical information in scientific literature
5. **Multimodal Learning**: Combine visual and text information for chemical analysis
## Data Quality
- All images are sourced from high-quality scientific literature
- Annotations are professionally verified for accuracy
- Contains samples of various chemical reaction types and complexities
- Supports fine-grained chemical information analysis
<!-- ## Citation
If you use this dataset in your research, please cite the relevant paper:
```bibtex
@dataset{rxncaption15k_2025,
title={U-RxnDiagram-15k: A Dataset for Chemical Reaction Diagram Parsing},
author={[Authors]},
year={2025},
version={v1},
description={A large-scale dataset for chemical reaction visual analysis extracted from scientific literature PDFs}
}
``` -->
## License
This dataset is licensed under the [Creative Commons Attribution-NonCommercial 4.0 International License (CC BY-NC 4.0)](https://creativecommons.org/licenses/by-nc/4.0/).
### Terms of Use
You are free to:
- **Share** — copy and redistribute the material in any medium or format
- **Adapt** — remix, transform, and build upon the material
Under the following terms:
- **Attribution** — You must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use.
- **NonCommercial** — You may not use the material for commercial purposes. Commercial use is prohibited without explicit permission from the licensor.
### Citation
If you use this dataset in your research, please cite it as follows:
```bibtex
@article{song2025rxncaption,
title={RxnCaption: Reformulating Reaction Diagram Parsing as Visual Prompt Guided Captioning},
author={Song, Jiahe and Wang, Chuang and Jiang, Bowen and Wang, Yinfan and Zheng, Hao and Wei, Xingjian and Liu, Chengjin and Nie, Rui and Gao, Junyuan and Sun, Jiaxing and others},
journal={arXiv preprint arXiv:2511.02384},
year={2025}
}
```
## Contact
For questions or suggestions, please contact songjiahe@pjlab.org.cn
---
提供机构:
opendatalab
搜集汇总
数据集介绍
构建方式
在化学信息学与计算机视觉的交叉领域,SA-RxnDiagram-15k数据集为反应图解分析提供了结构化基准。其构建过程始于从科学文献PDF中系统性地提取化学反应图像,确保了数据源的专业性与多样性。随后,通过精细的标注流程,为每幅图像中的反应物、产物、条件等关键元素添加了边界框与类别标签,最终形成包含15,400张图像与逾16.5万标注实例的大规模对齐数据集。
特点
该数据集的核心特征在于其多层次、细粒度的标注体系。它不仅区分了结构、文本、标识符与补充信息四大类别,更在结构类别下进一步细分为反应物、产物与条件分子结构等属性。这种设计使得数据集能够精准刻画化学反应图解中的视觉与语义信息,为模型理解复杂的科学图示提供了丰富的监督信号。数据集中反应条件文本标注占比最高,凸显了对反应环境这一关键化学要素的重视。
使用方法
研究人员可通过加载标准COCO格式的标注文件,便捷地访问数据集的图像与对应标注。该数据集适用于化学结构识别、文本信息抽取及多模态学习等多种任务。在具体应用中,用户可依据标注中的类别与属性信息,训练或评估模型在反应图解解析上的性能,例如定位分子结构或理解反应条件文本,从而推动化学文献自动分析与智能理解技术的发展。
背景与挑战
背景概述
在化学信息学与科学文献数字化分析领域,高效解析化学反应图示是连接视觉信息与结构化知识的关键环节。SA-RxnDiagram-15k数据集由Sciverse科学数据基金会于2025年构建,作为其Sci-Align对齐数据层的重要组成部分,旨在应对从科学文献PDF中自动提取化学反应图示的复杂任务。该数据集包含15,400张图像及超过16万条精细标注,覆盖反应物、产物、条件等实体及其文本描述,为化学反应图示解析提供了大规模、高质量的基准资源,显著推动了化学视觉理解与多模态科学文档分析的研究进展。
当前挑战
该数据集致力于解决化学反应图示自动解析这一核心领域问题,其挑战在于图示中化学结构的多样性与文本信息的密集交织,要求模型具备精确的视觉实体识别与跨模态对齐能力。在构建过程中,研究人员面临从海量科学文献中提取高质量反应图示的困难,包括图像质量不一、标注需要高度专业化学知识以确保准确性,以及如何设计统一标注体系以涵盖结构、文本、标识符等多类别信息,这些挑战共同塑造了数据集的复杂性与应用价值。
常用场景
经典使用场景
在化学信息学与计算机视觉交叉领域,SA-RxnDiagram-15k数据集为化学反应图解析提供了关键资源。其经典应用场景在于训练和评估模型从科学文献的图表中自动识别与解析化学反应元素,包括反应物、产物及反应条件等视觉与文本信息。这一过程不仅涉及目标检测,还要求模型理解化学结构的空间布局与语义关联,从而实现对复杂反应图的高精度解析,为自动化化学知识提取奠定基础。
实际应用
在实际应用中,SA-RxnDiagram-15k数据集可赋能化学研究自动化流程。例如,在药物发现领域,它能辅助快速从海量文献中提取反应路径,优化合成路线设计;在化学教育中,可支持智能工具自动生成反应解释,提升学习效率;此外,在专利分析与企业研发中,该技术能高效挖掘竞争情报,识别潜在创新点,显著提升科研与工业生产的智能化水平。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作。例如,基于其多模态特性,研究者提出了视觉提示引导的化学反应描述生成模型,将图解析任务重构为描述生成问题;同时,在目标检测框架中,针对化学结构的细粒度识别进行了优化。这些工作不仅提升了反应图解析的准确率,还推动了化学人工智能模型向更通用、更可解释的方向演进,为后续大规模科学知识库的构建提供了技术支撑。
以上内容由遇见数据集搜集并总结生成


