CloudPerfTrace
收藏Hugging Face2025-08-26 更新2025-08-28 收录
下载链接:
https://huggingface.co/datasets/AmirShahbaz/CloudPerfTrace
下载链接
链接失效反馈官方服务:
资源简介:
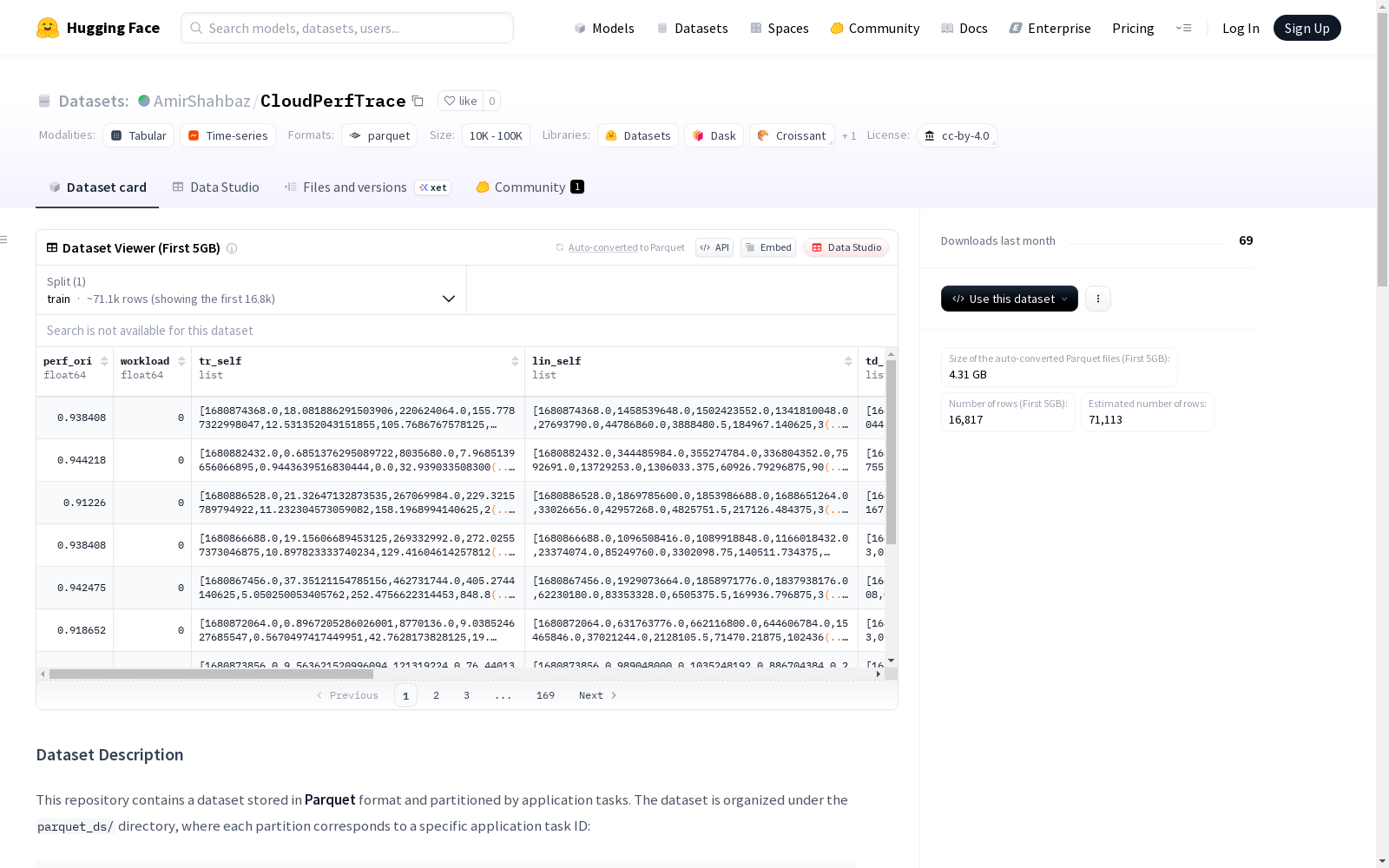
该数据集以Parquet格式存储,并根据不同的应用任务进行了分区。数据集包含了317天的追踪数据,每个分区对应一个特定的应用任务ID,如数据服务、Redis、网页搜索等。数据集的架构中包括性能水平、工作负载标识符、虚拟机指标、Linux性能指标以及针对目标应用和相邻虚拟机的自顶向下分析。数据集可以通过PyArrow库轻松加载。
创建时间:
2025-08-25
原始信息汇总
CloudPerfTrace 数据集概述
数据集基本信息
- 许可证: CC BY 4.0
- 格式: Parquet
- 存储结构: 按应用任务分区存储
- 数据覆盖范围: 317天追踪记录
任务ID与应用类型对应关系
| 任务ID | 应用类型 |
|---|---|
| 4 | Data Serving |
| 5 | Redis |
| 6 | Web Search |
| 7 | Graph Analytics |
| 9 | Data Analytics |
| 10 | MLPerf |
| 11 | HBase |
| 13 | Alluxio |
| 14 | Minio |
| 15 | TPC-C |
| 16 | Flink |
数据模式
性能指标
- perf_ori (double): 标准化性能水平(0-1范围)
- workload (double): 工作负载水平数值标识符
目标应用监控指标
- tr_self: 目标应用的虚拟机指标
- lin_self: 目标应用的Linux Perf指标
- td_self: 目标应用的Top-Down分析指标
邻居虚拟机监控指标
- tr_oth: 共置邻居虚拟机的虚拟机指标
- lin_oth: 邻居虚拟机的Linux Perf指标
- td_oth: 邻居虚拟机的Top-Down分析指标
分区标识
- tasks (int32): 应用任务ID(分区键)
数据加载方式
使用PyArrow加载数据集: python import pyarrow.dataset as ds dataset = ds.dataset("parquet_ds", format="parquet", partitioning="hive")
搜集汇总
数据集介绍
构建方式
在云计算性能分析领域,CloudPerfTrace数据集通过精心设计的实验框架构建而成。研究团队采用分布式追踪技术,持续收集了317天的全栈性能数据,涵盖从虚拟机指标到Linux性能事件的多层次度量。数据以Parquet格式存储,并按照11类典型应用任务进行分区,每个分区对应特定的应用类型标识符,如数据服务、图分析及机器学习负载等,确保了数据组织的系统性与可扩展性。
特点
该数据集的核心特点在于其多维度的性能表征能力,不仅包含目标应用的归一化性能指标和负载标识,还聚合了自身及邻接虚拟机的资源使用指标、Perf事件和Top-Down分析数据。这种设计使得研究者能够深入探究协同部署环境中的性能干扰模式,尤其适用于云计算场景下的资源竞争与隔离机制研究,为性能建模提供了丰富的特征空间。
使用方法
研究者可通过PyArrow库直接加载该分区数据集,利用Hive分区机制高效查询特定应用类别的性能轨迹。典型应用包括构建性能预测模型、分析跨虚拟机干扰效应,或验证资源调度策略。数据集的模式明确定义了性能指标、负载类型及邻居节点指标字段,支持联合查询与对比分析,为云计算性能优化研究提供标准化数据基础。
背景与挑战
背景概述
云计算性能监测领域在近年来受到广泛关注,CloudPerfTrace数据集由研究团队于现代云计算基础设施发展高峰期构建,旨在解决多租户环境下虚拟机性能干扰的量化分析问题。该数据集通过系统化采集不同应用任务在协同部署时的性能指标,为资源调度优化和性能隔离机制研究提供了重要数据支撑,对云计算资源管理领域的算法验证与模型优化产生了显著影响。
当前挑战
该数据集核心挑战在于解决多虚拟机协同部署时复杂性能干扰的模式识别问题,需从高维指标中提取有效特征以建立精确预测模型。构建过程中面临多源异构数据同步采集的技术难题,包括跨虚拟机监控指标的时间对齐、不同应用负载模式的标准化表征,以及长期追踪过程中数据一致性与完整性的保障。
常用场景
经典使用场景
在云计算性能优化研究中,CloudPerfTrace数据集为多租户环境下应用性能隔离分析提供了关键支撑。研究者通过其细粒度的性能指标(如perf_ori标准化性能值、Top-Down分析数据),能够系统评估数据服务、图计算、机器学习等11类应用在资源共享时的相互干扰模式,为构建性能预测模型奠定数据基础。
实际应用
云服务提供商可利用该数据集优化资源分配策略,提升数据中心能效。例如通过分析MLPerf(任务10)与Web Search(任务6)的共置干扰模式,设计智能调度器以避免性能争用;企业亦可基于TPC-C(任务15)的性能轨迹预测数据库工作负载峰值,实现弹性扩缩容。
衍生相关工作
基于CloudPerfTrace衍生了多项经典研究,包括基于拓扑分析(td_self/td_oth)的干扰感知调度框架、结合tr_oth邻域指标的性能预测神经网络模型。这些工作显著推进了云资源管理的智能化水平,并为异构工作负载协同调度理论提供了实证基础。
以上内容由遇见数据集搜集并总结生成


