erhwenkuo/squad-cmrc2018-zhtw
收藏数据集概述
数据集摘要
CMRC 2018 是第二届「讯飞杯」中文机器阅读理解颁奖研讨会(CMRC 2018)中相关竞赛所使用的数据集。
它主要用于中文机器阅读理解的跨度提取数据集,以增加该领域的语言多样性。该数据集由人类专家在维基百科段落上注释的近 20,000 个真实问题组成。
同时它也注释了一个挑战集,其中包含需要在整個上下文中进行全面理解和多句推理的问题。
数据集结构
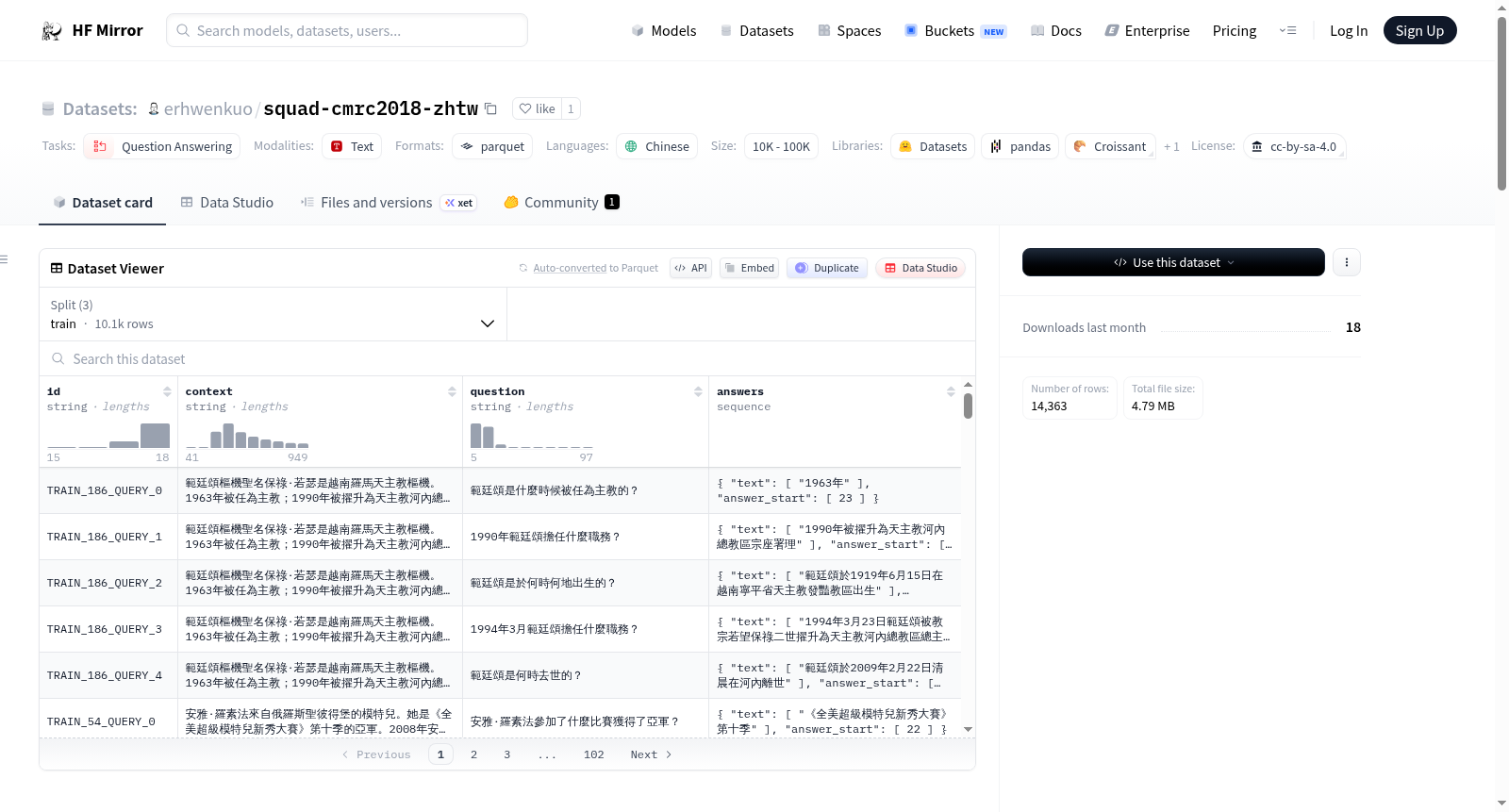
数据文件配置
train:data/train-*validation:data/validation-*test:data/test-*
数据特征
id: 字符串类型,编号context: 字符串类型,问题内容的上下文question: 字符串类型,问题answers: 问题回答(基于内容的上下文来提取)text: 字符串列表,问题的答案answer_start: 整数列表,问题的答案位于context上下文中的位置
数据分割
train: 10,142 条数据validation: 3,219 条数据test: 1,002 条数据
数据集大小
- 下载大小: 4781898 字节
- 数据集大小: 21350661 字节
许可信息
CC BY-SA 4.0
论文引用
@inproceedings{cui-emnlp2019-cmrc2018, title = "A Span-Extraction Dataset for {C}hinese Machine Reading Comprehension", author = "Cui, Yiming and Liu, Ting and Che, Wanxiang and Xiao, Li and Chen, Zhipeng and Ma, Wentao and Wang, Shijin and Hu, Guoping", booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP)", month = nov, year = "2019", address = "Hong Kong, China", publisher = "Association for Computational Linguistics", url = "https://www.aclweb.org/anthology/D19-1600", doi = "10.18653/v1/D19-1600", pages = "5886--5891", }