【我遇到的问题】 • 现象:该数据集的下载链接已失效 【相关信息】 • 可考虑访问这个链接获取类似文件~https://www.selectdataset.com/dataset/3688356173feccbcf1f1e490ddc6bc72
World Justice Project Rule of Law Index
收藏worldjusticeproject.org2024-10-24 收录
下载链接:
https://worldjusticeproject.org/rule-of-law-index
下载链接
链接失效反馈官方服务:
资源简介:
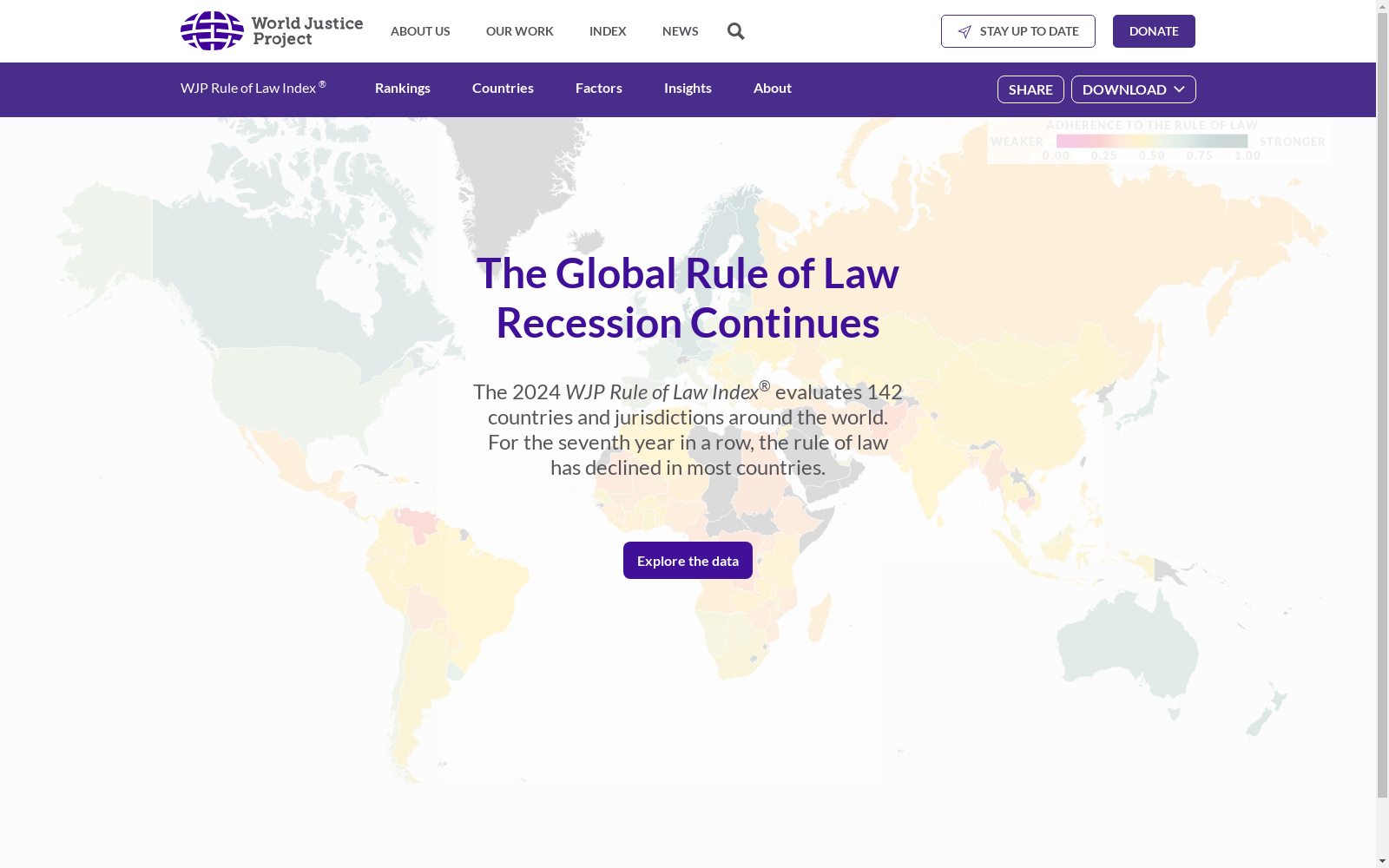
该数据集包含全球各国法治指数的详细信息,涵盖了八个法治维度:政府权力限制、腐败控制、开放政府、基本权利、秩序与安全、监管执行、民事司法和刑事司法。每个维度进一步细分为多个指标,提供了对各国法治状况的全面评估。
This dataset contains detailed information on the Rule of Law Index for countries worldwide. It covers eight dimensions of the rule of law: restrictions on government power, corruption control, open government, fundamental rights, order and security, regulatory enforcement, civil justice, and criminal justice. Each dimension is further subdivided into multiple indicators, providing a comprehensive assessment of the rule of law status of each country.
提供机构:
worldjusticeproject.org
搜集汇总
数据集介绍
构建方式
World Justice Project Rule of Law Index数据集的构建基于全球范围内的广泛调查和专家评估。该数据集通过收集来自不同国家和地区的法律专家、学者、公民和企业的反馈,系统地评估了法治在各国的实施情况。具体而言,数据集涵盖了八个核心法治维度,包括政府权力的限制、腐败的减少、基本权利的保障等。通过多层次的数据收集和分析,确保了数据集的全面性和可靠性。
特点
World Justice Project Rule of Law Index数据集以其全球覆盖和多维度评估为显著特点。该数据集不仅提供了各国法治状况的量化指标,还通过详细的子指标和案例分析,揭示了法治在不同社会经济背景下的具体表现。此外,数据集的更新频率较高,每年发布一次,确保了数据的时效性和参考价值。
使用方法
World Justice Project Rule of Law Index数据集适用于多种研究领域,包括法律、政治学、社会学和国际关系等。研究者可以通过该数据集分析不同国家和地区的法治发展趋势,评估政策效果,或进行跨国比较研究。此外,政策制定者和非政府组织也可以利用该数据集识别法治薄弱环节,制定针对性的改进措施。数据集的详细分类和子指标为深入分析提供了丰富的数据支持。
背景与挑战
背景概述
世界正义项目法治指数(World Justice Project Rule of Law Index)是由世界正义项目(World Justice Project, WJP)于2011年创建的一个综合性数据集,旨在全球范围内评估和监测法治状况。该数据集由WJP及其合作伙伴共同开发,涵盖了120多个国家和地区的法治指标,包括政府权力的限制、腐败控制、开放政府、基本权利、秩序与安全、监管执行以及民事司法等方面。通过这些指标,WJP致力于提供一个客观、全面的法治评估框架,以促进全球法治的透明度和问责制。
当前挑战
世界正义项目法治指数在构建过程中面临多项挑战。首先,法治概念的复杂性和多维度性使得指标的选择和权重分配成为一个难题。其次,数据的收集和验证需要跨越不同文化和法律体系,这增加了数据质量和一致性的挑战。此外,由于法治指数涉及敏感的政治和社会问题,数据的可获得性和透明度也受到限制。最后,如何确保指数的持续更新和改进,以反映全球法治的动态变化,也是一个重要的挑战。
发展历史
创建时间与更新
World Justice Project Rule of Law Index数据集由World Justice Project于2013年首次发布,此后每年更新一次,以反映全球法治状况的最新变化。
重要里程碑
该数据集的重要里程碑包括2013年的首次发布,标志着全球法治评估的系统化开始。2016年,数据集引入了更详细的子指标,增强了其分析深度。2019年,数据集扩展到覆盖126个国家和地区,显著提升了其全球代表性。2021年,数据集进一步优化了数据收集方法,提高了数据的准确性和可靠性。
当前发展情况
当前,World Justice Project Rule of Law Index已成为全球法治研究的重要参考,广泛应用于学术研究、政策制定和国际比较分析。其持续的年度更新确保了数据的时效性,为全球法治的动态监测提供了有力支持。此外,数据集的开放获取政策促进了全球范围内的知识共享,推动了法治理念的普及和实践。
发展历程
- World Justice Project Rule of Law Index首次发布,标志着全球法治指数的诞生。
- 指数首次应用于全球范围内的国家法治状况评估,涵盖了66个国家。
- 指数覆盖范围扩大至102个国家,进一步提升了其全球影响力。
- 指数首次引入新的评估维度,包括政府透明度和反腐败措施,增强了评估的全面性。
- 指数覆盖国家数量达到113个,成为全球范围内最全面的法治评估工具之一。
- 指数在评估方法上进行了重大改进,引入了更多的定量和定性数据,提高了评估的准确性和可靠性。
常用场景
经典使用场景
在法律与社会科学领域,World Justice Project Rule of Law Index 数据集被广泛用于评估和比较全球各国法治状况。该数据集通过收集和分析来自多个国家和地区的法律实施、政府透明度、司法独立性等方面的数据,为学者和政策制定者提供了一个全面的法治评估框架。其经典使用场景包括跨国法治比较研究、政策效果评估以及国际援助项目的法治指标设定。
衍生相关工作
基于 World Justice Project Rule of Law Index 数据集,许多学者和研究机构开展了进一步的深入研究。例如,有研究通过该数据集分析了法治与经济增长之间的长期关系,提出了新的理论模型。此外,还有研究利用该数据集探讨了法治在应对全球公共卫生危机中的作用,为国际社会提供了宝贵的政策建议。这些衍生工作不仅丰富了法治研究的理论体系,也增强了该数据集的实际应用价值。
数据集最近研究
最新研究方向
在法治领域,World Justice Project Rule of Law Index数据集的最新研究方向聚焦于全球化背景下法治指数的动态变化及其对国际关系的影响。研究者们通过分析该数据集,探讨不同国家和地区法治水平的差异及其成因,进而评估这些差异对全球经济、政治和社会稳定的影响。此外,该数据集还被用于研究法治与经济发展、社会公平以及环境保护之间的复杂关系,为政策制定者提供科学依据,以促进全球法治的均衡发展。
相关研究论文
- 1The World Justice Project Rule of Law Index: Measuring the Rule of LawWorld Justice Project · 2011年
- 2The Rule of Law and Economic Growth: Time Series EvidenceUniversity of California, Berkeley · 2015年
- 3The Rule of Law and Public Health: A Cross-National StudyHarvard University · 2018年
- 4The Impact of Rule of Law on Foreign Direct InvestmentUniversity of Oxford · 2017年
- 5The Rule of Law and Human Development: A Global PerspectiveUniversity of Cambridge · 2020年
以上内容由遇见数据集搜集并总结生成


