IconQA
收藏arXiv2022-07-25 更新2024-06-21 收录
下载链接:
https://iconqa.github.io
下载链接
链接失效反馈官方服务:
资源简介:
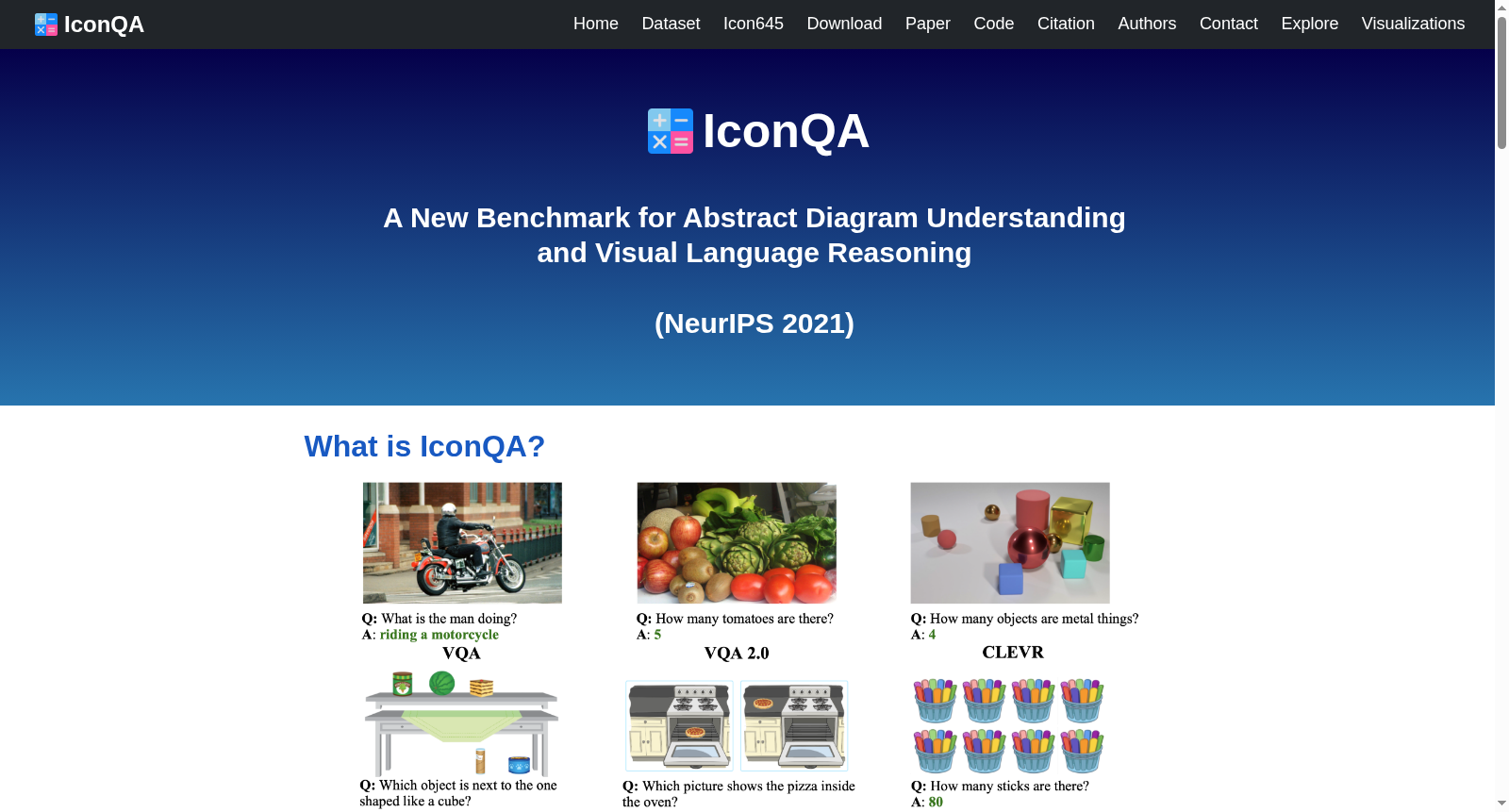
IconQA是一个大规模的数据集,包含107,439个问题,旨在评估抽象图标图像理解和视觉语言推理能力。该数据集由加州大学洛杉矶分校视觉、认知、学习和自主中心创建,包含三个子任务:多图像选择、多文本选择和填空。IconQA数据集灵感来源于现实世界的图表问题,强调了抽象图标理解的重要性,并要求模型不仅具备对象识别和文本理解等感知技能,还需要几何推理、常识推理和算术推理等多样化的认知推理技能。此外,为了帮助潜在的IconQA模型学习图标图像的语义表示,还发布了一个包含645,687个彩色图标的Icon645数据集,涵盖377个类别。
IconQA is a large-scale dataset consisting of 107,439 questions, designed to evaluate abstract icon image understanding and vision-language reasoning capabilities. This dataset was created by the Center for Vision, Cognition, Learning, and Autonomy at the University of California, Los Angeles (UCLA), and includes three subtasks: multiple-image selection, multiple-text selection, and fill-in-the-blank. Inspired by real-world chart-based questions, the IconQA dataset emphasizes the importance of abstract icon understanding, and requires models to possess not only perceptual skills such as object recognition and text understanding, but also diverse cognitive reasoning skills including geometric reasoning, commonsense reasoning, and arithmetic reasoning. Furthermore, to assist potential IconQA models in learning semantic representations of icon images, an additional dataset named Icon645 has been released, which contains 645,687 colored icons spanning 377 categories.
提供机构:
加州大学洛杉矶分校视觉、认知、学习和自主中心
创建时间:
2021-10-26
搜集汇总
数据集介绍
构建方式
在视觉问答领域,自然图像已得到广泛研究,而抽象图表的语义丰富性仍待深入探索。IconQA数据集的构建源于现实世界数学应用题,旨在评估抽象图表理解与视觉语言推理能力。该数据集从开源数学教材中筛选出包含丰富图标图像的问题,涵盖从学前至三年级的教学内容,确保问题涉及多样化的视觉推理技能。通过专业众包工作者收集并过滤无效或重复数据,最终形成包含107,439个问答对的大规模数据集,并按6:2:2的比例划分为训练集、验证集和测试集。
使用方法
IconQA数据集适用于训练和评估视觉问答模型在抽象图表领域的性能。研究者可利用其三个子任务进行多模态学习,结合图标图像与自然语言问题,开发具备视觉识别与认知推理能力的系统。使用前需下载数据集并按既定划分进行实验,可参考提供的基线模型Patch-TRM,该模型采用金字塔结构的跨模态Transformer,并利用Icon645图标数据集预训练图表嵌入模块。通过基准测试,包括注意力机制和Transformer方法,可全面评估模型在图标理解与推理任务上的表现。
背景与挑战
背景概述
在视觉问答(VQA)研究领域,自然图像的理解与推理已取得显著进展,然而抽象图表的语义丰富性及其在视觉理解中的潜力尚未得到充分探索。为此,由加州大学洛杉矶分校、中山大学、华东师范大学及哥伦比亚大学的研究团队于2021年联合推出了IconQA数据集。该数据集聚焦于图标图像的抽象图表理解与视觉语言推理,核心研究问题在于如何通过图标图像上下文回答自然语言问题,以模拟现实世界中的图表应用题场景。IconQA包含107,439个问题,涵盖多图像选择、多文本选择及填空题三种子任务,强调对几何推理、常识推理及算术推理等多维认知技能的融合需求。该数据集的发布不仅填补了抽象图表VQA研究的空白,还为智能教育辅助系统等领域提供了重要的基准资源。
当前挑战
IconQA数据集旨在解决抽象图表理解与视觉语言推理的领域问题,其核心挑战在于模型需同时具备对象识别、文本理解等感知能力,以及空间推理、常识推理等十三类认知技能。这些技能的交织使得单一模态或浅层模型难以实现准确的问题解答。在构建过程中,研究团队面临数据收集与处理的复杂性:需从真实数学教材中筛选包含彩色图标且问题多样化的实例,同时避免冗余数据;图标图像的抽象性与风格多样性导致传统基于自然图像预训练的视觉编码器难以提取有效表征,为此团队额外构建了Icon645图标数据集以支持模型预训练,但该数据的长尾分布进一步加剧了类别不平衡的挑战。
常用场景
经典使用场景
在视觉问答领域,IconQA数据集以其对抽象图标的深入理解需求而著称,为研究者提供了一个评估模型在非自然图像场景下视觉推理能力的平台。该数据集通过包含多图像选择、多文本选择及填空题三种子任务,模拟了真实世界中的数学应用题场景,要求模型不仅识别图标对象,还需进行几何推理、常识推理及算术运算等多样化认知技能的综合运用。
解决学术问题
IconQA数据集有效弥补了现有视觉问答研究中对抽象图表理解的不足,解决了传统VQA数据集过度依赖自然图像而忽略符号化视觉语义的局限性。它推动了模型在图标识别、空间关系解析及多模态推理等方面的研究进展,为开发具备高阶认知能力的AI系统提供了关键基准,促进了视觉与语言融合领域的理论深化与方法创新。
实际应用
该数据集在教育科技领域展现出显著应用价值,尤其适用于开发智能辅导系统,能够辅助学龄前至小学低年级学生通过图标化问题提升数学与逻辑思维能力。其基于真实教材的题目设计确保了教育场景的适用性,同时图标数据的抽象特性避免了隐私泄露风险,使得其在教育软件、自适应学习平台等实际应用中具备高度可行性与安全性。
数据集最近研究
最新研究方向
在视觉问答领域,IconQA数据集的推出标志着抽象图表理解与视觉语言推理研究迈入新阶段。该数据集聚焦于图标图像的多模态推理,其前沿探索主要围绕跨模态Transformer架构的优化与预训练策略展开。研究热点包括设计金字塔式补丁分割机制以增强空间层次感知,并利用大规模图标数据集Icon645进行领域自适应预训练,以提升模型对抽象符号的语义表征能力。这些进展不仅推动了视觉推理模型在几何、常识及算术等多维认知技能上的突破,也为智能教育辅助系统等现实应用奠定了技术基石,具有深远的学术价值与实践意义。
相关研究论文
- 1IconQA: A New Benchmark for Abstract Diagram Understanding and Visual Language Reasoning加州大学洛杉矶分校视觉、认知、学习和自主中心 · 2022年
以上内容由遇见数据集搜集并总结生成


