Co-VisiON
收藏arXiv2025-06-20 更新2025-06-24 收录
下载链接:
https://ai4ce.github.io/CoVISION
下载链接
链接失效反馈官方服务:
资源简介:
Co-VisiON数据集是一个室内场景的稀疏图像集合,用于评估模型在稀疏条件下进行共同可见性推理的能力。数据集包含超过1000个室内场景,每个场景包含多个稀疏分布的图像。这些图像通过共同可见的表面区域相互连接,形成一个二进制的共同可见性图。数据集由纽约大学的研究团队创建,旨在推动视觉模型在稀疏环境中的高阶推理能力的发展。
The Co-VisiON dataset is a collection of sparse images from indoor scenes, developed to evaluate models' ability to perform joint visibility reasoning under sparse conditions. It comprises over 1000 indoor scenes, each containing multiple sparsely distributed images. These images are interconnected via mutually visible surface regions, forming a binary joint visibility graph. Created by a research team at New York University, this dataset aims to advance the high-order reasoning capabilities of visual models in sparse environments.
提供机构:
纽约大学,布鲁克林,纽约州,11201,美国
创建时间:
2025-06-20
原始信息汇总
Co-VisiON 数据集概述
数据集基本信息
- 名称: Co-VisiON (Co-Visibility ReasONing on Sparse Image Sets of Indoor Scenes)
- 研究团队: 纽约大学团队(Chao Chen, Nobel Dang, Juexiao Zhang等)
- 发布平台: arXiv
- 相关资源: 包含代码和数据
核心目标
- 提出共视性推理任务,评估智能代理在稀疏观测条件下的空间推理能力。
- 生成带有密集共视性标注的稀疏室内图像数据集(基于光真实感室内仿真环境)。
关键贡献
- 基准构建: 覆盖1000+室内场景的稀疏图像集共视性推理评估。
- 发现:
- 现有视觉模型在稀疏条件下的共视性分析显著落后于人类水平。
- 专有视觉语言模型(VLM)表现优于纯视觉模型。
- 新方法: 提出多视图基线模型Covis(基于MV-DUSt3R架构),缩小与VLM的差距。
数据集特性
- 标注类型: 密集共视性标注(像素级可见区域识别)
- 场景复杂度: 高复杂度室内环境
- 数据分布: 稀疏图像集(非连续密集采样)
技术方法
- Covis架构:
- 多视图编码器-解码器结构
- 跨视图注意力机制(蓝/绿/橙色分别表示参考/正/负视图)
- 联合优化拓扑预测(Co-VisiON)和掩模预测(BCE损失函数)
- 创新点: 通过可学习掩模M聚焦共视区域,结合全局与局部共视信号。
应用价值
- 推动视觉模型在稀疏环境下的高层推理能力发展
- 为3D视觉与机器人感知提供新评估基准
支持信息
- 资助: 美国国家科学基金会(NSF 2238968, 2322242等)
- 计算资源: 纽约大学高性能计算中心
搜集汇总
数据集介绍
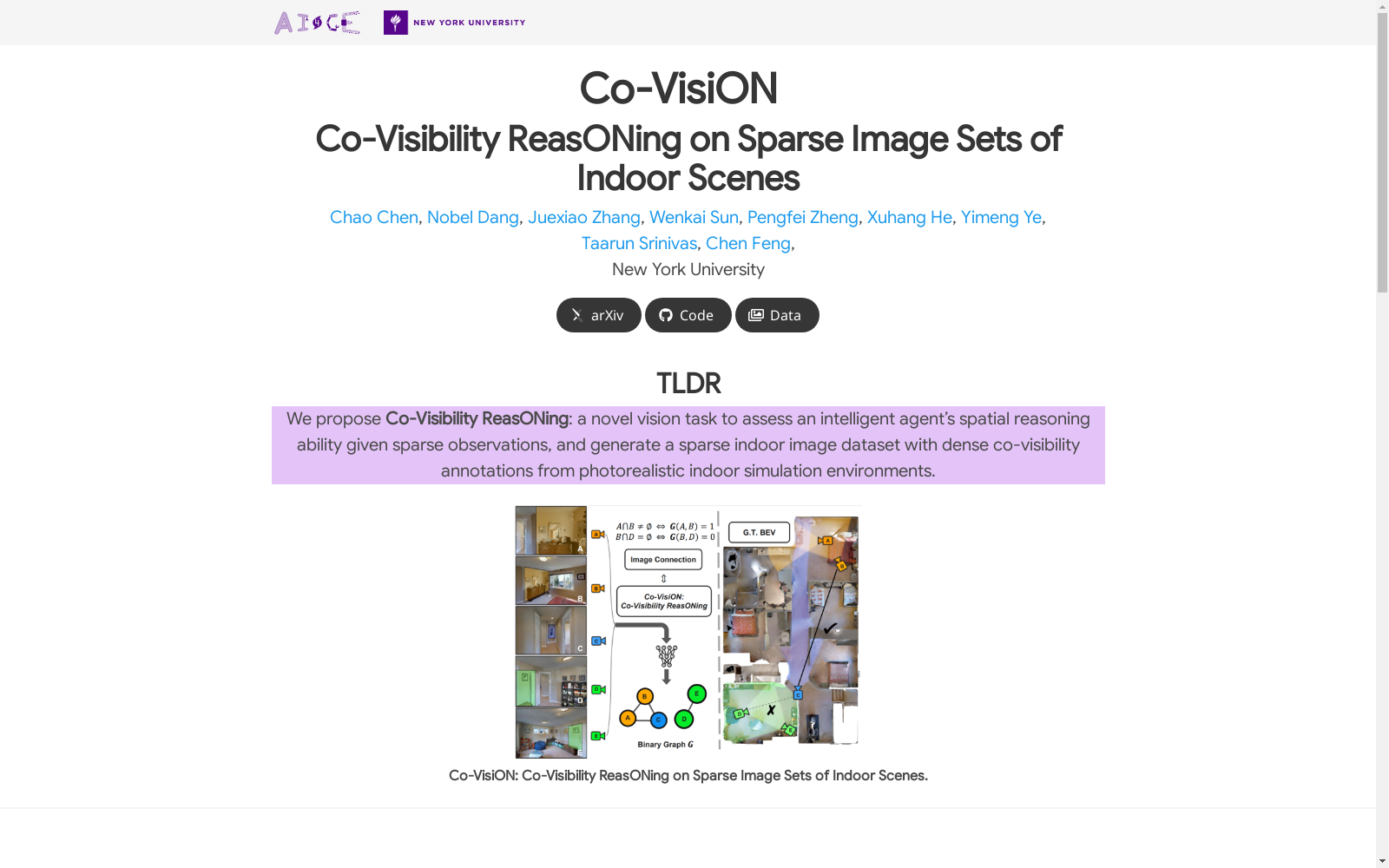
构建方式
Co-VisiON数据集的构建采用了渐进式候选选择策略,通过Habitat-sim从Gibson和HM3D等室内仿真环境中收集稀疏但具有代表性的数据。具体而言,每个图像的选择基于与已选图像的最高交并比(IoU),确保IoU既不过高(≥30%)也不过低(≤5%),从而生成稀疏分布的图像集及其共视性图。此外,数据集还包含人类标注的共视性图,用于验证自动标注的质量并提供人类推理基准。
特点
Co-VisiON数据集包含来自1000多个室内场景的稀疏图像集,每个场景具有密集的共视性标注。其特点在于通过虚拟3D场景生成高质量的共视性真实标注,避免了真实数据集中常见的噪声和粗糙标注问题。数据集还提供了共视性图和共视区域信息,支持多视角空间推理任务。此外,数据集涵盖了不同楼层结构的复杂场景,并通过场景级分割防止数据泄露。
使用方法
Co-VisiON数据集可用于评估模型在稀疏图像条件下的共视性推理能力。使用方法包括通过预测共视性图的邻接矩阵来量化模型性能,主要评估指标为图交并比(Graph IoU)和曲线下面积(AUC)。该数据集还支持3D重建、视觉定位和机器人感知等应用,例如通过共视性图优化结构运动(SfM)和同步定位与建图(SLAM)算法。此外,数据集的多视角特性使其成为训练和测试多视角学习模型的理想选择。
背景与挑战
背景概述
Co-VisiON数据集由纽约大学的研究团队于2025年提出,旨在评估视觉模型在稀疏图像集上的共视性推理能力。该数据集包含超过1000个室内场景的稀疏图像集,重点关注人类在有限视觉信息下构建空间认知拓扑图的能力。作为3D计算机视觉和机器人感知的基础能力,共视性推理在图像匹配、场景重建和视觉定位等任务中具有重要作用。该数据集通过精确的共视区域标注和多样化的场景覆盖,为视觉模型的时空推理能力评估提供了标准化基准。
当前挑战
Co-VisiON数据集面临的核心挑战体现在两个方面:在领域问题层面,现有视觉模型难以处理稀疏视角下的共视性推理,特别是当图像间重叠区域有限或视角差异显著时,传统基于特征匹配的方法性能显著下降;在构建过程层面,数据集需要精确标注稀疏图像间的共视关系,这要求开发创新的相机位姿选择策略和自动化标注流程,同时确保场景覆盖的完整性与标注质量之间的平衡。此外,跨楼层场景的垂直结构建模和真实感渲染也构成了重要的技术挑战。
常用场景
经典使用场景
在计算机视觉领域,Co-VisiON数据集被广泛应用于评估模型在稀疏图像集上的共视性推理能力。该数据集通过模拟真实室内场景的稀疏图像分布,为研究者提供了一个标准化的测试平台,用于验证模型在复杂场景下的空间理解能力。特别是在3D视觉和机器人感知任务中,Co-VisiON数据集成为衡量模型性能的重要基准。
实际应用
在实际应用中,Co-VisiON数据集为室内场景的3D重建、视觉定位和机器人导航等任务提供了重要支持。例如,在房地产和酒店预订领域,该数据集能够帮助系统从少量稀疏图像中推断出场景的空间布局,从而提升用户体验。此外,其在SLAM和SfM系统中的优化应用,显著提高了稀疏观测条件下的算法效率。
衍生相关工作
Co-VisiON数据集催生了一系列相关研究,特别是在多视图学习和共视性推理领域。基于该数据集提出的Covis模型,通过引入多视图掩码预测机制,显著提升了纯视觉模型的性能。此外,该数据集还激发了视觉-语言模型在共视性推理中的应用探索,如GPT-4o等大型模型在该任务上的表现验证了其潜力。
以上内容由遇见数据集搜集并总结生成


