statcodesearch
收藏Hugging Face2024-11-28 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/drndr/statcodesearch
下载链接
链接失效反馈官方服务:
资源简介:
StatCodeSearch数据集是一个基准测试集,包含从R编程语言脚本中提取的代码注释对,这些脚本主要由研究人员编写。数据集来源于开放科学框架(OSF),包含与社会科学和心理学领域相关的R项目中的文本和代码样本,重点关注研究数据的统计分析。该数据集可用于测试低资源编程语言的编程语言理解能力,适用于语义代码搜索和代码分类任务。
创建时间:
2024-11-27
原始信息汇总
StatCodeSearch 数据集概述
基本信息
- 许可证: CC BY 4.0
- 任务类别:
- 文本检索
- 文本分类
- 语言: 代码
- 数据规模: 1K<n<10K
- 数据集名称: statcodesearch
数据集描述
StatCodeSearch 数据集是一个基准测试集,包含从 R 编程语言脚本中提取的代码注释对,主要由研究人员编写。数据集来源于 Open Science Framework (OSF),包含与社会科学和心理学领域相关的 R 项目中的文本和代码样本,重点关注研究数据的统计分析。该数据集作为 GenCodeSearchNet 测试套件的一部分,可用于测试低资源编程语言的编程语言理解能力。
数据集来源
- 仓库: https://github.com/drndr/gencodesearchnet
- 论文: https://arxiv.org/abs/2311.09707
数据集用途
- 语义代码搜索: 使用注释作为查询,返回数据集中匹配的代码片段。
- 代码分类: 使用标签将代码片段分类为四个类别:数据变量、可视化、统计建模、统计测试。
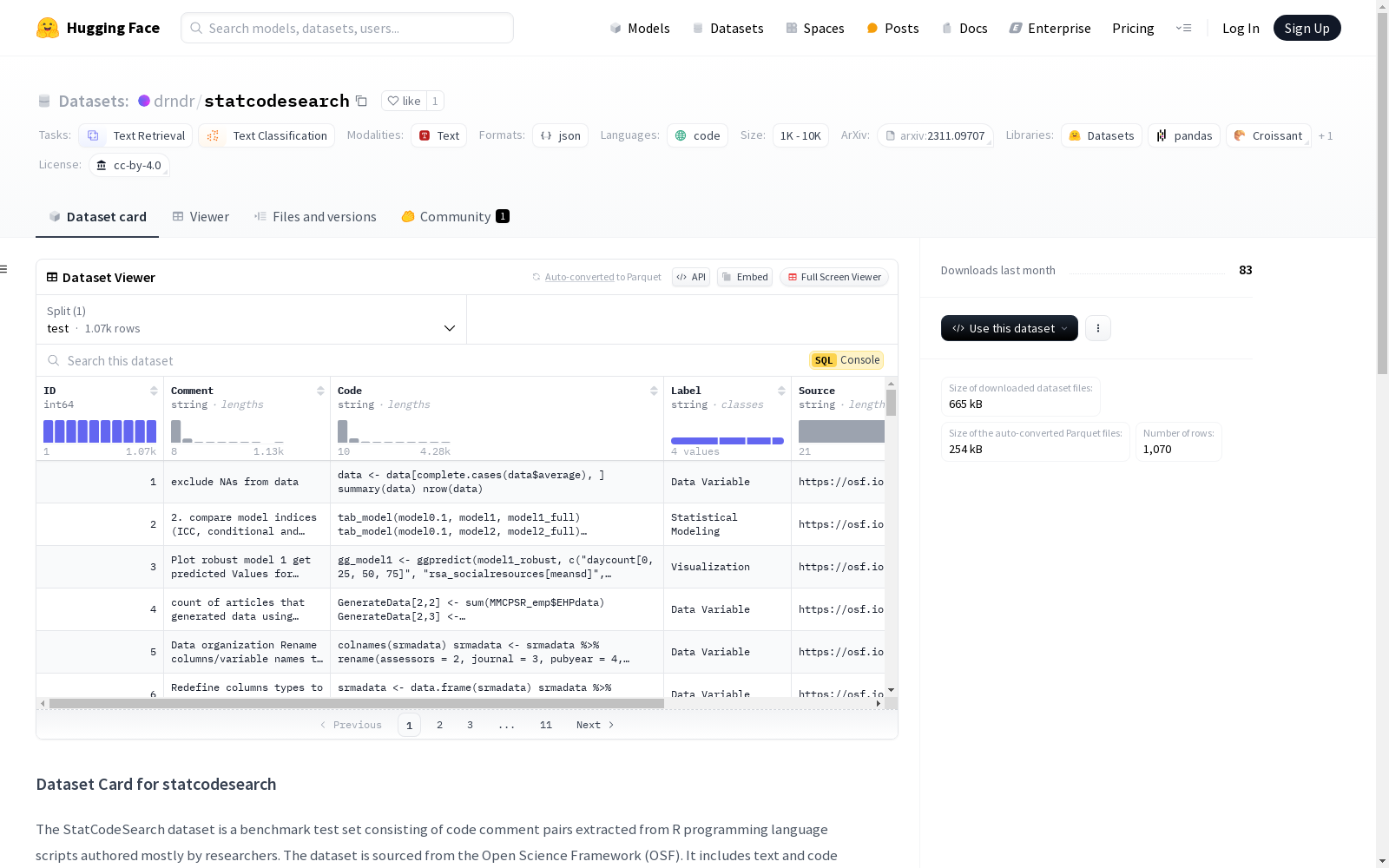
数据集结构
- Id: 每个项目的唯一标识符
- Comment: 描述代码片段的完整注释字符串
- Code: 完整代码片段字符串
- Label: 代码片段的类别
- Source: 提取代码注释对的 OSF 仓库
- File: 从 OSF 仓库提取的代码注释对的 R 文件名称
引用
BibTeX:
@inproceedings{diera2023gencodesearchnet, title={GenCodeSearchNet: A Benchmark Test Suite for Evaluating Generalization in Programming Language Understanding}, author={Diera, Andor and Dahou, Abdelhalim and Galke, Lukas and Karl, Fabian and Sihler, Florian and Scherp, Ansgar}, booktitle={Proceedings of the 1st GenBench Workshop on (Benchmarking) Generalisation in NLP}, pages={12--24}, year={2023} }
搜集汇总
数据集介绍
构建方式
StatCodeSearch数据集的构建基于R编程语言脚本中的代码与注释对,主要来源于开放科学框架(OSF)。该数据集从R项目中提取了与社会科学和心理学领域相关的文本和代码样本,特别关注研究数据的统计分析。通过从OSF仓库中提取代码-注释对,数据集为低资源编程语言的理解提供了基准测试集。
特点
StatCodeSearch数据集的特点在于其专注于R编程语言,尤其是社会科学和心理学领域的统计分析代码。数据集包含唯一的标识符、完整的注释描述、代码片段、代码类别标签、来源仓库信息以及提取自OSF仓库的R文件名。这些特征使得该数据集能够支持语义代码搜索和代码分类任务,特别是针对数据变量、可视化、统计建模和统计测试等类别的分类。
使用方法
StatCodeSearch数据集的使用方法主要包括语义代码搜索和代码分类。在语义代码搜索中,用户可以通过注释作为查询,从数据集中检索匹配的代码片段。在代码分类任务中,数据集提供了四个类别标签,用户可以根据这些标签将代码片段分类为数据变量、可视化、统计建模或统计测试。该数据集适用于测试低资源编程语言的理解能力,并为相关研究提供了丰富的实验数据。
背景与挑战
背景概述
StatCodeSearch数据集作为GenCodeSearchNet测试套件的一部分,专注于R编程语言的代码注释对,旨在评估编程语言理解能力。该数据集由研究人员从开放科学框架(OSF)中提取,主要来源于社会科学和心理学领域的R项目,重点关注研究数据的统计分析。其核心研究问题在于通过语义代码搜索和代码分类任务,提升对低资源编程语言的理解能力。该数据集的创建时间为2023年,主要研究人员包括Andor Diera等,其研究成果已在相关领域的学术会议中发表,对编程语言理解领域的研究具有重要推动作用。
当前挑战
StatCodeSearch数据集在解决语义代码搜索和代码分类任务时面临多重挑战。首先,R语言作为一种低资源编程语言,其代码注释对的可用性和质量有限,导致数据集的构建过程复杂且耗时。其次,代码注释对的语义关联性需要精确标注,这对数据标注的准确性和一致性提出了较高要求。此外,数据集的多样性和代表性也面临挑战,因其主要来源于特定领域的研究项目,可能无法全面覆盖R语言的其他应用场景。这些挑战不仅影响了数据集的构建质量,也对后续模型的泛化能力提出了更高要求。
常用场景
经典使用场景
StatCodeSearch数据集在编程语言理解领域具有重要应用,特别是在R语言的代码注释对检索和分类任务中。研究者通过该数据集,能够有效地测试和评估模型在低资源编程语言环境下的性能。该数据集的使用场景主要集中在语义代码搜索和代码分类两个方面,通过注释作为查询,返回匹配的代码片段,或根据标签将代码片段分类为数据变量、可视化、统计建模和统计测试等类别。
实际应用
在实际应用中,StatCodeSearch数据集被广泛用于开发智能代码搜索工具和代码分类系统。这些工具能够帮助研究人员和开发者快速定位和理解代码片段,特别是在处理复杂的统计分析和数据可视化任务时。通过该数据集,开发者能够构建更加智能和高效的代码辅助工具,提升编程效率和代码质量。
衍生相关工作
StatCodeSearch数据集作为GenCodeSearchNet测试套件的一部分,已经衍生出多项经典研究工作。例如,基于该数据集的模型评估和优化方法,推动了编程语言理解领域的技术进步。此外,该数据集还为跨语言代码理解和生成研究提供了宝贵的数据资源,促进了相关领域的研究和发展。
以上内容由遇见数据集搜集并总结生成


