MoGaze
收藏arXiv2020-11-24 更新2024-06-21 收录
下载链接:
https://humans-to-robots-motion.github.io/mogaze/
下载链接
链接失效反馈官方服务:
资源简介:
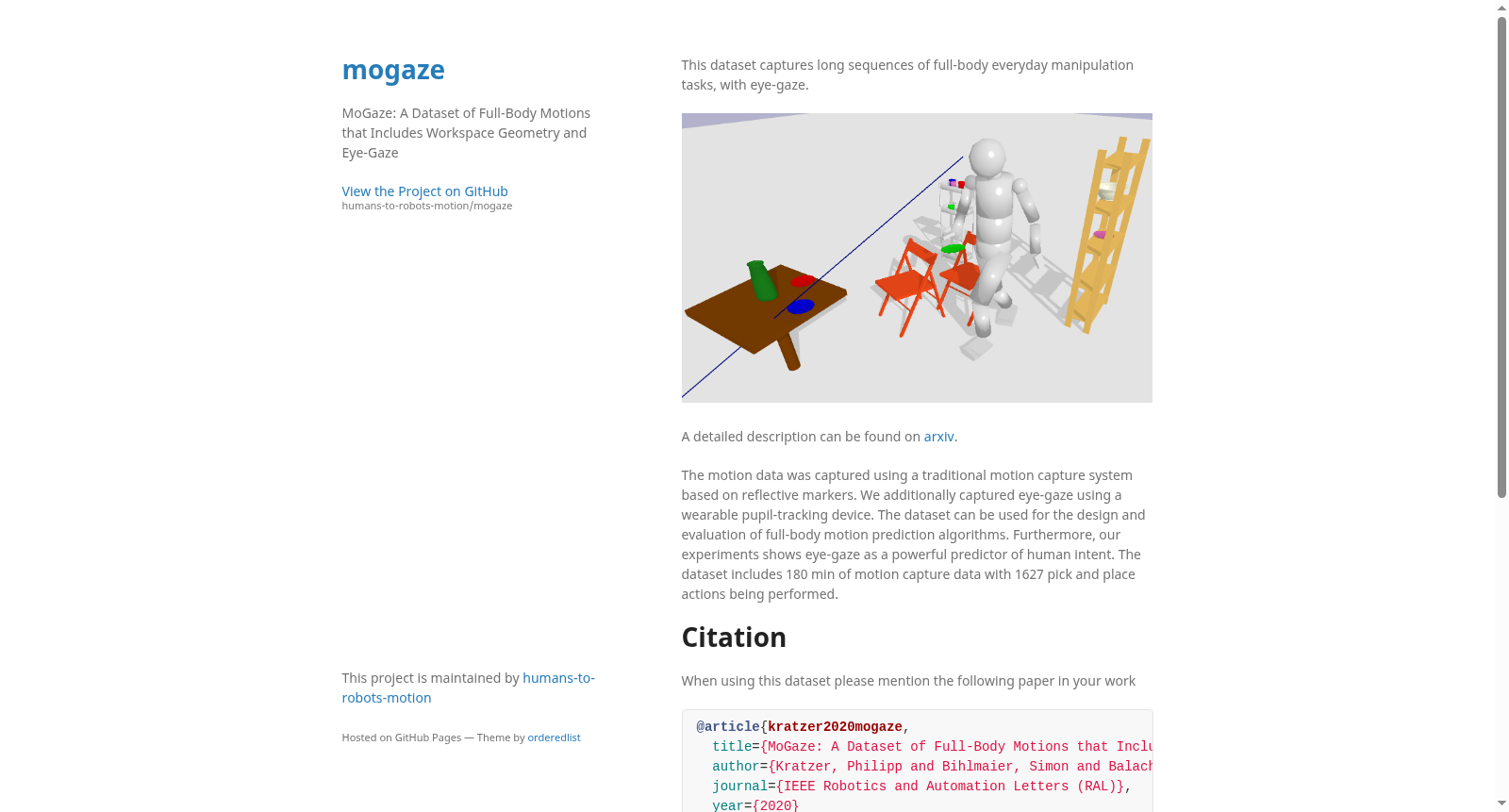
MoGaze数据集由斯图加特大学创建,专注于日常操作任务中的全身运动数据,包括工作空间几何和眼动追踪。该数据集包含180分钟的运动捕捉数据,记录了1627次拾取和放置动作,使用反射标记和可穿戴瞳孔追踪设备进行数据采集。数据集旨在为设计评估全身运动预测算法提供支持,并展示眼动作为预测人类意图的强大指标。未来计划扩展到包含两人协作任务的数据集。
The MoGaze dataset, created by the University of Stuttgart, focuses on full-body motion data during daily manipulation tasks, including workspace geometry and eye-tracking. It contains 180 minutes of motion capture data, recording 1627 pick-and-place actions collected via reflective markers and wearable pupil-tracking devices. This dataset is intended to support the design and evaluation of full-body motion prediction algorithms, and demonstrates that eye movement serves as a robust indicator for predicting human intent. Future plans include expanding the dataset to cover two-person collaborative tasks.
提供机构:
斯图加特大学
创建时间:
2020-11-24
搜集汇总
数据集介绍
构建方式
MoGaze数据集通过一套完整的多模态采集框架构建而成,旨在捕捉日常操作任务中的人体全身运动、工作空间几何结构以及眼动信息。数据采集采用基于反射标记的传统光学运动捕捉系统(OptiTrack,12台摄像机,覆盖约3×4米区域),以120Hz频率记录人体全身运动与场景中物体的六自由度位姿。同时,受试者佩戴PupilLabs眼动追踪头戴设备,通过USB-C连接至Android智能手机,经由Wi-Fi将眼动视频传输至Linux工作站,实现200Hz的眼动数据采集。眼动数据与运动数据通过时间戳同步,并在后处理阶段根据置信度进行帧匹配。为获得全局坐标系下的注视方向,研究者在头戴设备上附加了3D打印的可拆卸标记,并通过让受试者从不同角度注视特定标记进行最小二乘拟合校准。场景中的物体(如桌子、架子、盘子、杯子等)均贴有4至6个标记以估计其刚体位姿,其几何模型通过CAD软件构建为三角网格。
特点
该数据集的核心特点在于首次将全身运动捕捉与眼动追踪数据融合于同一操作任务场景中,填补了现有数据集在操作任务、工作空间几何结构和眼动信息三方面的空白。数据集包含180分钟的运动捕捉记录,涵盖7名受试者(6名男性,1名女性)执行1627次抓取与放置动作,涉及多种日常操作任务(如摆桌、清理、收纳等)。为增加运动多样性,场景中椅子的位置在记录过程中变更了三次,形成三种不同空间配置,迫使受试者采取不同路径。此外,数据集提供了丰富的标注信息,包括自动标注并由人工验证的抓取/放置动作分割、任务指令及其时间戳、物体与人体骨架的完整位姿序列、原始标记数据,以及场景中所有物体的网格文件。眼动数据则包含二维注视点、三维注视点、双眼中心坐标、注视法向量及置信度值,为意图预测研究提供了关键支撑。
使用方法
数据集以HDF5格式存储人体运动、物体位姿及眼动数据,指令以CSV文件存储,场景描述以XML格式提供,并附带人类骨架的URDF模型。用户可通过提供的基于PyBullet的可视化与回放库加载数据,进行交互式分析与算法开发。数据可广泛应用于全身运动预测、基于功能可供性的运动规划、层次化运动预测以及基于注视的意图预测等研究。例如,可利用循环神经网络(RNN)结合注视距离与人体骨架位置进行短期运动预测;或通过最大熵逆强化学习学习子任务的局部奖励,实现层次化行为建模;亦可通过计算物体到注视射线的距离,构建简单的注视基线模型,在抓取意图预测中取得优于复杂模型的表现。数据集的开放访问地址为https://humans-to-robots-motion.github.io/mogaze/。
背景与挑战
背景概述
随着机器人逐渐融入开放的人类环境,理解并预测人类运动成为人机协作领域的关键课题。然而,现有全身运动数据集普遍存在三大短板:缺乏长序列操作任务、缺失工作空间三维几何信息、以及未能集成眼动数据,这些要素对于机器人在近距离场景下准确预测人类意图至关重要。为此,由斯图加特大学等机构的研究团队于2020年发布的MoGaze数据集应运而生。该数据集包含180分钟、1627次抓取与放置动作的全身运动捕捉数据,同步采集了7名参与者的眼动信息,并提供了场景中物体的三维几何模型。MoGaze首次将全身运动与眼动数据相结合,为服务机器人领域的人体运动预测、意图推断及人机协同研究提供了前所未有的数据支撑。
当前挑战
该数据集所应对的核心挑战在于,现有数据集无法支撑机器人对操作任务中人类全身运动的精准预测。具体而言,一是在领域问题上,缺乏同时包含操作任务、场景几何与眼动信息的综合数据集,导致机器人难以理解人类在非结构化环境中的运动规划与意图;二是在构建过程中,需解决多模态数据的高精度同步问题,包括120Hz运动捕捉与200Hz眼动数据的帧级对齐,以及通过3D打印附件与全局标定法消除眼动仪与运动捕捉系统之间的位姿误差。此外,场景中物体与椅子的动态配置增加了数据多样性,但光学遮挡导致的微小跳变、眼动仪对变距离注视的校准折衷等技术难题,仍是数据质量保障中的关键挑战。
常用场景
经典使用场景
MoGaze数据集在服务机器人领域扮演着举足轻重的角色,尤其适用于研究人机共融环境中的全身运动预测。该数据集囊括了长时间序列的日常操作任务、精确的三维工作空间几何模型以及珍贵的眼动注视数据,为设计能够理解并预判人类行为的算法提供了坚实基础。研究者可借助该数据集训练基于循环神经网络的短期运动预测模型,通过结合环境约束与运动优化,实现对人类全身轨迹的高保真预测。
解决学术问题
MoGaze数据集系统性地解决了现有全身运动数据集在操作任务、工作空间几何与眼动数据方面的三重缺失。它首次将眼动注视与全身运动捕捉同步整合,为验证注视作为人类意图预测的关键线索提供了实证依据。通过该数据集,学术研究得以量化评估眼动特征在物体抓取意图早期识别中的显著优势,并探索层次化运动预测框架,将高层任务目标与低层运动控制相衔接,推动了人机协作中意图理解与运动预测的理论发展。
衍生相关工作
MoGaze数据集催生了一系列卓有影响力的衍生研究。其中,基于该数据的上下文感知全身运动预测框架,将变分循环编码器-解码器与轨迹优化相结合,实现了环境约束下的高精度运动预判。另一项经典工作利用该数据集学习物体操作可供性,将可供性热力图与运动预测深度融合,使机器人能够理解环境中的行为可能性。此外,基于最大熵逆强化学习的层次化运动预测模型,成功从人类演示中编码高层任务目标,为复杂操作场景下的机器人自主决策开辟了新路径。
以上内容由遇见数据集搜集并总结生成


