real-colon-SfM
收藏Hugging Face2026-05-18 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/SmartWhatt/real-colon-SfM
下载链接
链接失效反馈官方服务:
资源简介:
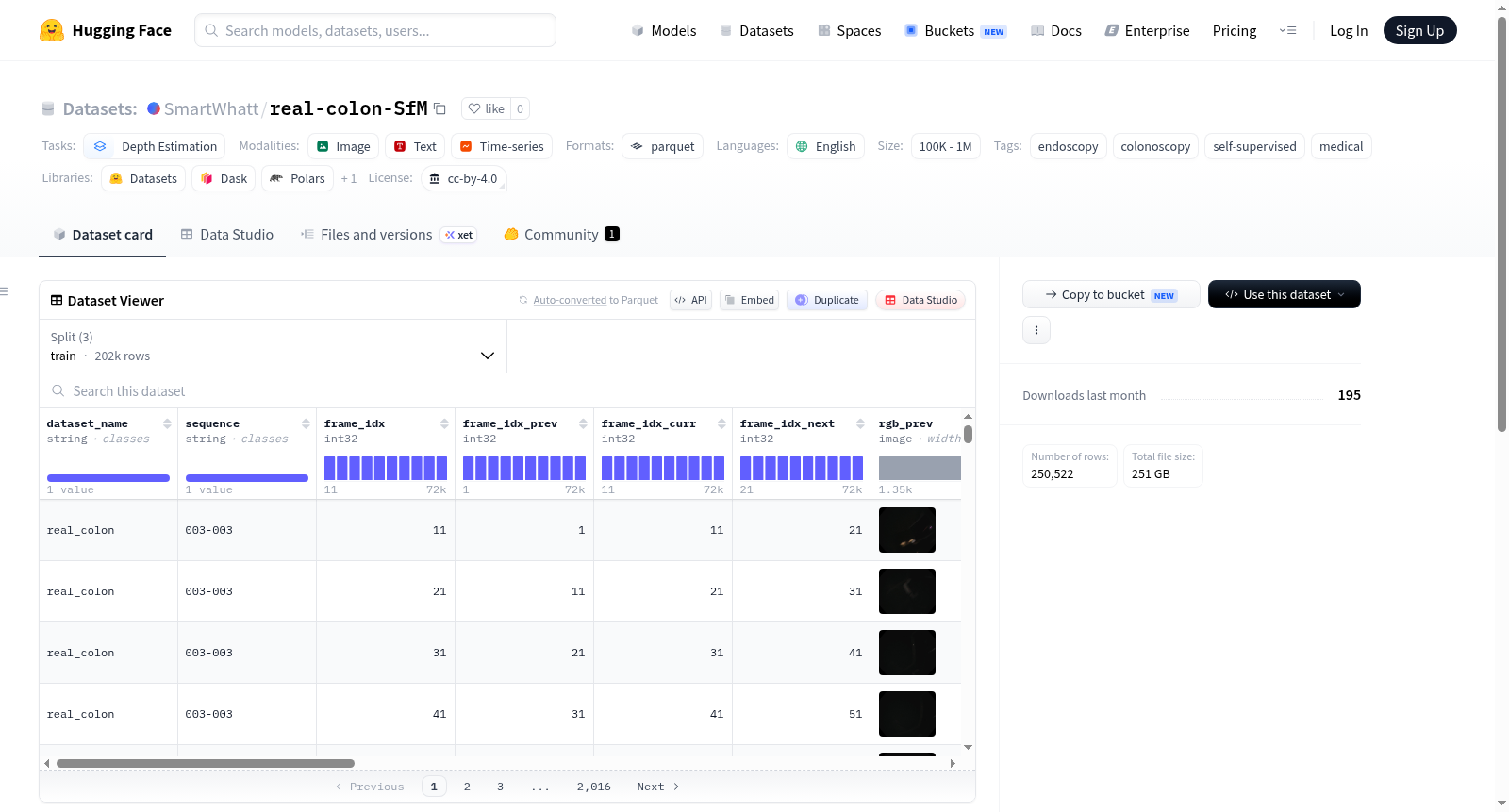
REAL-Colon HF Triplets数据集是REAL-Colon数据集的一个重新打包版本,专为流式自监督AF-SfMLearner训练而设计。该数据集采用CC BY 4.0许可,面向深度估计任务,内容来源于结肠镜内窥镜视频,具有医学应用背景。数据以时间三元组的形式组织,每个数据行包含从原始视频帧中采样得到的前一帧(prev)、当前帧(curr)和下一帧(next)的RGB图像。此外,数据集还包括帧索引、序列标识、相机内参矩阵(K)、帧间实际步长(frame_stride)、源帧率(source_fps)和目标帧率(target_fps)等信息。由于原始REAL-Colon数据集不提供深度、遮挡或姿态的真值,因此深度图(depth)、遮挡图(occlusion)以及从前一帧/下一帧到当前帧的姿态变换矩阵(pose_curr2prev, pose_curr2next)字段均为空值,对应的布尔标志(has_depth, has_occlusion, has_pose)设置为false。数据集包含训练集(201,543个样本)、验证集(30,525个样本)和测试集(18,454个样本)三个标准分割,总数据量超过250GB。该数据集适用于自监督深度估计、光流、视觉里程计等计算机视觉任务在医学内窥镜场景下的研究与开发。
The REAL-Colon HF Triplets dataset is a repackaged version of the REAL-Colon dataset, specifically designed for streaming self-supervised AF-SfMLearner training. The original dataset is licensed under CC BY 4.0. It is oriented towards depth estimation tasks, with content derived from colonoscopy endoscopic videos, providing a medical application context. The data is organized in temporal triplets, where each row includes RGB images of the previous frame (prev), current frame (curr), and next frame (next) sampled from original video frames. Additionally, the dataset contains information such as frame indices, sequence identifiers, camera intrinsic matrix (K), inter-frame stride (frame_stride), source frame rate (source_fps), and target frame rate (target_fps). Notably, since the original REAL-Colon dataset does not provide ground truth for depth, occlusion, or pose, the fields for depth maps (depth), occlusion maps (occlusion), and pose transformation matrices from previous/next frames to the current frame (pose_curr2prev, pose_curr2next) are empty, with corresponding boolean flags (has_depth, has_occlusion, has_pose) set to false. The dataset includes three standard splits: training set (201,543 samples), validation set (30,525 samples), and test set (18,454 samples), with a total data volume exceeding 250GB. This dataset is suitable for research and development in self-supervised depth estimation, optical flow, visual odometry, and other computer vision tasks within the medical endoscopy scenario.
创建时间:
2026-05-16
搜集汇总
数据集介绍
构建方式
在医学影像分析领域,特别是针对肠道内窥镜检查的深度估计任务,数据集的构建往往面临标注成本高昂的挑战。real-colon-SfM数据集基于原始REAL-Colon数据进行了精心重打包,专为自监督AF-SfMLearner训练设计。其构建方式采用低帧率时间三元组采样策略,从已提取的结肠镜视频帧文件中提取连续的图像序列,并通过帧步长参数记录原始帧之间的实际距离。对于已经过官方子采样的数据,数据集会以最接近的整数步长近似目标帧率。值得注意的是,该数据集并未提供深度或姿态的真实标注,因此对应的深度图、遮挡图及相对姿态均为空值,标志位亦被设为false。
特点
real-colon-SfM数据集显著的特点在于其专为自监督学习范式量身定制,完全规避了对人工标注的依赖。数据集中每一条样本均由前、当前、后三帧RGB图像构成三元组结构,并附带时间戳、序列标识及帧索引等元信息,便于模型学习时空一致性。此外,数据集虽然包含了深度图、遮挡图和相机内参等字段,但仅在实际可用的条件下才填充有效数据,这赋予了数据使用的灵活性。其训练集包含超过20万条样本,验证集与测试集各具3万与1.8万余条,规模可观,足以支撑复杂深度估计网络的训练与评估。
使用方法
使用该数据集进行模型开发十分便捷,得益于HuggingFace Datasets库的支持。用户可通过load_dataset函数直接加载指定数据子集,并可启用流式模式以高效处理大规模数据。加载后的数据行中包含丰富的字段,包括RGB图像三元组、相机内参矩阵、帧步长信息等,研究人员可依据任务需求提取相应的输入与监督信号。建议在训练自监督深度估计模型时,利用前后帧之间的相对姿态作为几何约束,结合光流或遮挡信息辅助模型学习。整个加载与迭代过程与标准HuggingFace数据集接口完全一致,降低了使用门槛。
背景与挑战
背景概述
在医学影像分析领域,内窥镜下的三维重建与深度估计对计算机辅助诊断和手术导航具有重要意义。REAL-Colon数据集由相关研究机构于近年创建,专注于结肠镜检查场景下的自监督深度估计与视觉里程计任务。该数据集以CC BY 4.0协议发布,其核心研究问题在于为结肠镜视频提供大规模、多样化的时序帧数据,以支持自监督学习方法的训练与评估。通过从临床采集的结肠镜视频中提取并组织成三元组帧结构,该数据集为研究者提供了模拟真实内窥镜运动与光照变化的资源,推动了自监督框架在医学内窥镜深度估计领域的发展,并为后续实时导航与病变定位任务奠定了数据基础。
当前挑战
该数据集面临的挑战可归纳为以下方面。其一,领域任务层面,结肠镜图像具有纹理重复、光照不均、组织形变剧烈及缺乏可靠深度真值等特点,使得传统的监督学习方法难以直接应用,自监督范式需依赖帧间几何一致性来约束深度与姿态估计。其二,数据集构建过程中,原始视频采集受限于临床条件,存在帧率不均、运动模糊及视角遮挡等问题;此外,由于缺乏真实深度与姿态标注,构建过程需借助结构从运动方法估算伪真值,但伪真值的精度和一致性受视频质量与场景复杂度制约,从而影响自监督训练的收敛效果与泛化能力。
常用场景
经典使用场景
在医学影像分析领域,深度估计是提升内窥镜手术导航与三维重建能力的关键技术。REAL-Colon SfM数据集专为自监督深度与相机运动估计任务而设计,其核心使用场景是训练和评估基于自监督结构光运动(SfM)框架的模型。通过提供从真实结肠镜视频中提取的连续三帧图像序列(前后帧与当前帧),该数据集使得研究者无需依赖昂贵的深度真值标注,即可利用时序一致性约束学习单目深度与相对位姿。这一经典场景广泛应用于推进医学内窥镜场景中的无监督视觉测距与密集深度预测研究。
解决学术问题
在学术研究中,医学内窥镜图像因缺乏大规模、高质量的深度与位姿标注而长期受限。REAL-Colon SfM数据集解决了自监督学习方法在真实结肠镜数据上训练数据匮乏的问题,为探究无监督视觉里程计与单帧深度估计的联合学习提供了标准化的评测基准。它有效降低了传统监督学习对人工标注的依赖,使得模型能够在真实结肠扫描流中学习时空几何一致性。该数据集推动了深度学习在手术导航、病灶三维定位等方向的发展,具有显著的方法学创新意义与临床转化潜力。
衍生相关工作
REAL-Colon SfM数据集作为REAL-Colon的再封装版本,衍生了多项经典研究工作,尤其集中于自监督深度估计领域的模型改进。例如,AF-SfMLearner系列方法利用该数据集训练其自适应框架,通过多帧时序一致性学习深度与相机运动,实现了在无标注内窥镜数据上的高效推理。此外,相关工作还包括基于该数据集的无监督域适应方法,以及融合光流与遮挡感知的深度估计网络。这些工作共同推动了医学影像中自监督几何学习方法的成熟,并为后续面向临床的内窥镜三维重建研究奠定了数据与方法基础。
以上内容由遇见数据集搜集并总结生成


