artem9k/ai-text-detection-pile
收藏Hugging Face2023-02-27 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/artem9k/ai-text-detection-pile
下载链接
链接失效反馈官方服务:
资源简介:
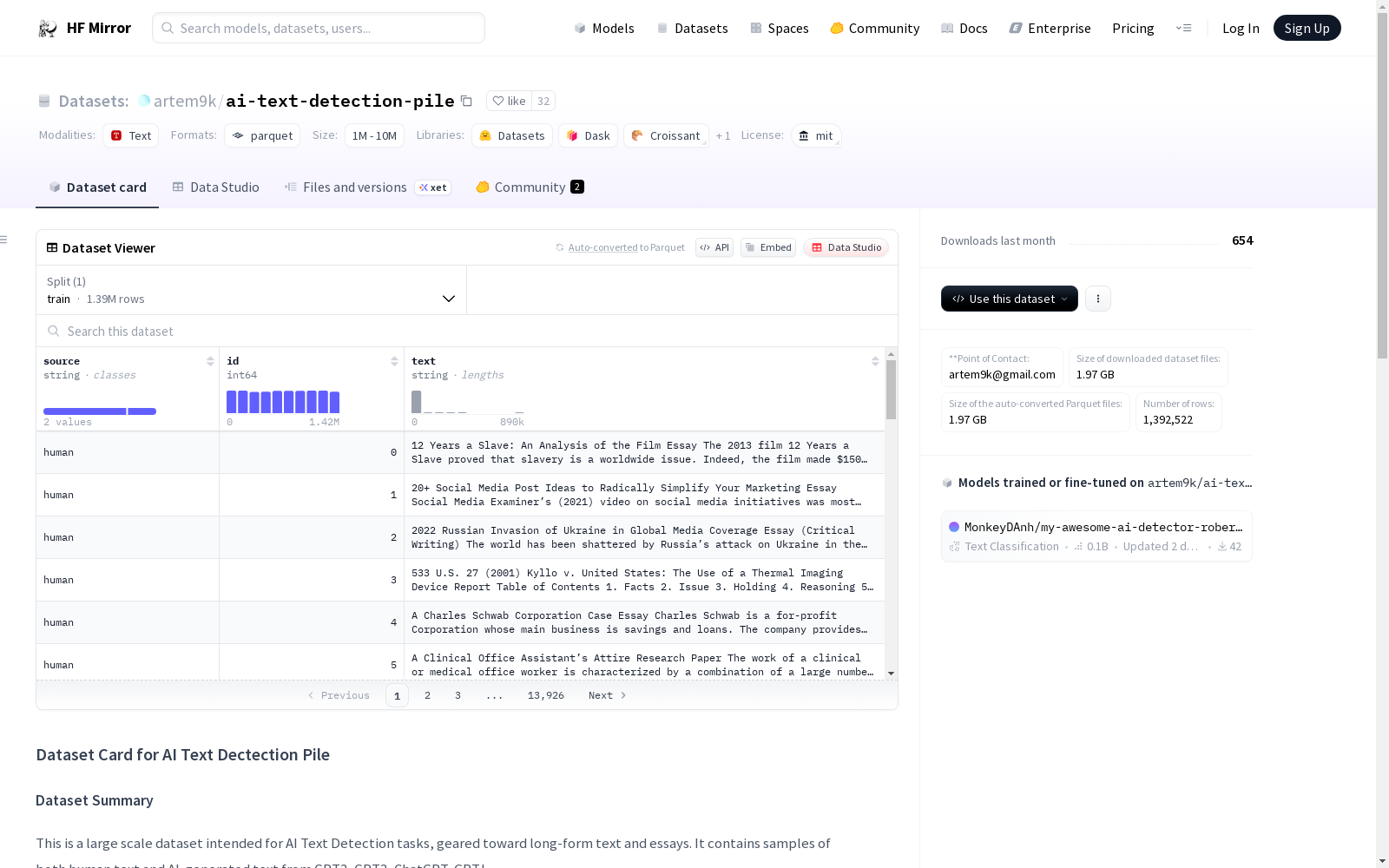
这是一个大规模的数据集,旨在用于AI文本检测任务,特别是针对长文本和文章。它包含了人类文本和AI生成文本的样本,AI生成文本来自GPT2、GPT3、ChatGPT、GPTJ等模型。数据集的样本数量在README中进行了详细分类,包括人类文本和AI生成文本的来源、样本数量以及相关链接。数据集支持的任务包括文本分类和AI文本检测,语言为英语,数据字段包括TEXT(样本的文本)和SOURCE(来源,分为“human”或“ai”)。
这是一个大规模的数据集,旨在用于AI文本检测任务,特别是针对长文本和文章。它包含了人类文本和AI生成文本的样本,AI生成文本来自GPT2、GPT3、ChatGPT、GPTJ等模型。数据集的样本数量在README中进行了详细分类,包括人类文本和AI生成文本的来源、样本数量以及相关链接。数据集支持的任务包括文本分类和AI文本检测,语言为英语,数据字段包括TEXT(样本的文本)和SOURCE(来源,分为“human”或“ai”)。
提供机构:
artem9k
原始信息汇总
数据集概述
数据集名称
AI Text Detection Pile
数据集描述
这是一个大规模数据集,专为AI文本检测任务设计,主要针对长篇文本和论文。数据集包含人类文本和来自GPT2、GPT3、ChatGPT、GPTJ的AI生成文本样本。
数据集组成
人类文本
| 数据集名称 | 样本数量 | 链接 |
|---|---|---|
| Reddit WritingPromps | 570k | Link |
| OpenAI Webtext | 260k | Link |
| HC3 (Human Responses) | 58k | Link |
| ivypanda-essays | TODO | TODO |
| 总计 | 990k | - |
AI生成文本
| 模型 | 数据集名称 | 样本数量 | 链接 |
|---|---|---|---|
| GPT2 | OpenAI gpt2-output-dataset | 260k | Link |
| GPT3 | pairwise-davinci | 44k | TODO |
| GPT3 | synthetic-instruct-davinci-pairwise | 30k | Link |
| GPTJ | synthetic-instruct-gptj-pairwise | 44k | Link |
| ChatGPT | Scraped from twitter | 5k | - |
| ChatGPT | HC3 (ChatGPT Responses) | 27k | Link |
| ChatGPT | ChatGPT Prompts/emergentmind | 500 | Link |
| 总计 | 340k | - | - |
支持的任务
- 文本分类
- AI文本检测
语言
英语
数据字段
- TEXT: 样本的文本内容
- SOURCE: 标识文本来源,可能是"human"或"ai"
搜集汇总
数据集介绍
构建方式
该数据集旨在服务于人工智能文本检测任务,特别是针对长篇文本和论文。它由人类文本和多种AI生成的文本构成,包括GPT2、GPT3、ChatGPT和GPTJ模型生成的文本。数据集的构建汇集了来自Reddit写作提示、OpenAI网络文本、HC3(人类回应)等多个来源的人类文本样本,以及通过不同AI模型生成的文本样本,总计约1330k个样本。
使用方法
使用该数据集时,研究者可以依据TEXT字段中的样本文本和SOURCE字段中的样本来源(人类或AI)进行文本分类或AI文本检测等任务。数据集的开放性和多样性使其成为训练和评估相关AI模型的宝贵资源。用户可以直接从指定的链接获取数据集样本,并在MIT许可证的允许范围内进行研究和开发。
背景与挑战
背景概述
AI Text Detection Pile数据集,由artem9k负责维护,旨在为AI文本检测任务提供大规模的数据支持,特别是针对长篇文本和论文。该数据集汇集了人类创作文本与AI生成文本,其中人类文本样本源自Reddit写作提示、OpenAI网络文本、HC3人类响应等,总计约990k样本;AI生成文本则来自GPT2、GPT3、GPTJ和ChatGPT等模型,总计约340k样本。该数据集的创建,不仅丰富了文本检测领域的研究材料,也为评估和提升AI文本生成模型的准确性提供了重要资源,对自然语言处理领域产生了显著影响。
当前挑战
该数据集在构建过程中所面临的挑战包括:1) 确保人类文本与AI生成文本的质量与准确性,以利于后续的文本检测任务;2) 处理不同来源和不同模型生成的文本之间的异质性,保证数据集的一致性和可用性。在研究领域问题方面,AI Text Detection Pile数据集的挑战在于如何精确地区分人类创作与AI生成的文本,这对于防止滥用AI生成内容、确保信息真实性等方面具有重要意义。
常用场景
经典使用场景
在人工智能研究领域,尤其是自然语言处理(NLP)领域,artem9k/ai-text-detection-pile数据集的重要性不容小觑。该数据集被广泛应用于AI文本检测任务中,尤其是针对长篇文本和论文。其经典使用场景在于训练和评估AI模型对人类文本与AI生成文本的区分能力,以提升文本分类和AI文本检测的准确性。
解决学术问题
该数据集解决了学术研究中关于AI生成文本与人类文本鉴别的问题,为研究者提供了一个丰富的样本集,使得能够更有效地训练模型以区分文本的来源。其意义和影响在于,有助于提高文本分类系统的可靠性,对于打击虚假信息和维护网络信息安全具有重要作用。
实际应用
在实际应用中,artem9k/ai-text-detection-pile数据集被用于开发能够检测和过滤AI生成内容的工具,这在内容审核、学术诚信检查以及网络安全等多个领域都有显著的应用价值。
数据集最近研究
最新研究方向
在人工智能文本检测领域,artem9k/ai-text-detection-pile数据集的构建与使用,正推动着学术研究的深入。该数据集汇集了大规模的人类文本与AI生成文本,旨在提升AI文本检测的准确度与效率。目前,研究者们正利用此数据集探索深度学习模型在文本分类与AI文本检测任务中的性能极限,以期在模型泛化能力、检测精确度上取得突破。此数据集的出现,对于识别并区分人类创作与机器生成内容具有重大意义,尤其在版权保护、学术诚信等领域,其应用前景广阔,备受关注。
以上内容由遇见数据集搜集并总结生成


