WideIRSTD Dataset
收藏github2024-08-14 更新2024-08-16 收录
下载链接:
https://github.com/XinyiYing/LimitIRSTD-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
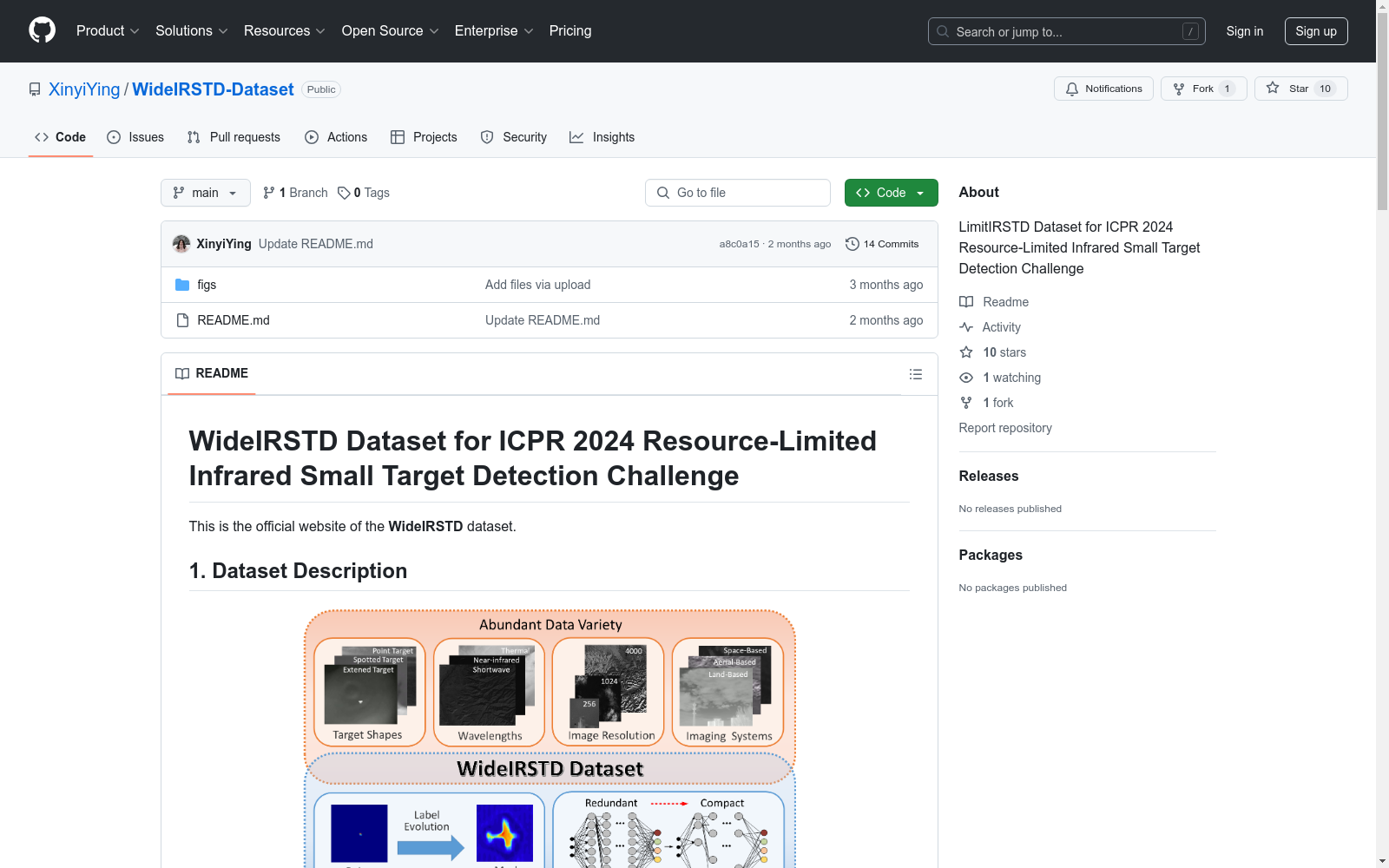
WideIRSTD数据集包含七个公开数据集:SIRST-V2、IRSTD-1K、IRDST、NUDT-SIRST、NUDT-SIRST-Sea、NUDT-MIRSDT、Anti-UAV,以及由国防科技大学团队开发的数据集,包括模拟陆基和太空基数据,以及真实手动标注的太空基数据。数据集包含具有各种目标形状(如点目标、斑点目标、扩展目标)、波长(如近红外、短波红外和热红外)、图像分辨率(如256、512、1024、3200等)的图像,以及不同的成像系统(如陆基、空基和太空基成像系统)。
WideIRSTD dataset comprises seven public datasets: SIRST-V2, IRSTD-1K, IRDST, NUDT-SIRST, NUDT-SIRST-Sea, NUDT-MIRSDT, and Anti-UAV, as well as datasets developed by the National University of Defense Technology (NUDT) team, including simulated land-based and space-based data and real manually annotated space-based data. The dataset includes images with various target shapes (e.g., point targets, speckle targets, extended targets), operating wavelengths (e.g., near-infrared, short-wave infrared, thermal infrared), image resolutions (e.g., 256, 512, 1024, 3200, etc.), and data acquired via different imaging systems including land-based, air-based, and space-based ones.
创建时间:
2024-08-14
原始信息汇总
WideIRSTD 数据集概述
1. 数据集描述
WideIRSTD 数据集包含七个公开数据集:SIRST-V2, IRSTD-1K, IRDST, NUDT-SIRST, NUDT-SIRST-Sea, NUDT-MIRSDT, Anti-UAV,以及由国防科技大学团队开发的数据集,包括模拟的陆基和太空基数据,以及真实的手动标注太空基数据。该数据集包含多种目标形状(如点目标、斑点目标、扩展目标)、波长(如近红外、短波红外和热红外)、图像分辨率(如256、512、1024、3200等),以及不同的成像系统(如陆基、空基和太空基成像系统)。
2. 数据集用途
在 LimitIRSTD 挑战中,该数据集用于评估在资源有限条件下的红外小目标检测(IRSTD)性能。
-
Track 1: 弱监督 IRSTD 在单点监督下
- 训练集:6000 张图像,带有粗略点标注
- 测试集:500 张图像
-
Track 2: 轻量级 IRSTD 像素级监督
- 训练集:9000 张图像,带有地面真实(GT)掩码标注
- 测试集:2000 张图像
3. 数据集下载
4. 挑战结果
Track 1 结果
| 排名 | 团队名称 | 得分 | IoU (1e-2) | Pd (1e-2) | Fa (1e-6) |
|---|---|---|---|---|---|
| 1 | Chainey | 60.7869 | 45.3729 | 76.2010 | 24.8629 |
| 2 | XJTU-IR | 60.3803 | 42.564 | 78.1966 | 26.5012 |
| 3 | MCV-TEAM | 60.0276 | 38.9762 | 81.0790 | 24.6809 |
| ... | ... | ... | ... | ... | ... |
Track 2 结果
| 排名 | 团队名称 | 得分 | mIoU (1e-2) | Pd (1e-2) | Fa (1e-6) | 参数(M) | GFLOPs |
|---|---|---|---|---|---|---|---|
| 1 | Chainey | 77.6729 | 33.8738 | 78.4534 | 60.9312 | 0.0288 | 0.0426 |
| 2 | Stars Twinkle and Shine | 77.0699 | 38.2523 | 75.3753 | 32.755 | 0.0469 | 0.4065 |
| 3 | MCV-TEAM | 76.2318 | 30.5698 | 77.2710 | 46.4470 | 0.0199 | 0.2530 |
| ... | ... | ... | ... | ... | ... | ... | ... |
5. 基准方法
Track 1
- 方法: Mapping Degeneration Meets Label Evolution: Learning Infrared Small Target Detection with Single Point Supervision
- 代码: Github
- 检查点: BaiduYun Onedrive
- 结果:
| 方法 | 得分 | IoU (1e-2) | Pd (1e-2) | Fa (1e-6) |
|---|---|---|---|---|
| DNANet_full (full supervision) | 54.681 | 40.773 | 68.588 | 4.915e-6 |
| DNANet_LESPS_coarse (weak supervision) | 46.451 | 29.266 | 63.636 | 2.294e-5 |
Track 2
- 方法: Weighted Res-UNet for High-Quality Retina Vessel Segmentation
- 代码: Github
- 检查点: BaiduYun Onedrive
- 结果:
| 方法 | 得分 | mIoU (1e-2) | Pd (1e-2) | Fa (1e-6) | 参数(M) | GFLOPs |
|---|---|---|---|---|---|---|
| UNet | 51.954 | 34.573 | 55.556 | 18.838e-6 | 5.179 | 0.914 |
搜集汇总
数据集介绍
构建方式
WideIRSTD数据集的构建基于七个公开数据集和一个由国防科技大学团队开发的数据集,涵盖了模拟陆基和空间基数据以及真实手动标注的空间基数据。这些数据集包含了多种目标形状、波长、图像分辨率和成像系统,确保了数据的多样性和广泛性。具体而言,WideIRSTD-Weak数据集包含6000张图像,采用粗略点标注,而WideIRSTD-Full数据集则包含9000张图像,采用精细的地面真值掩码标注。
特点
WideIRSTD数据集的显著特点在于其广泛的数据多样性和高度的挑战性。数据集不仅涵盖了从近红外到热波段的多种波长,还包含了从256到3200像素不等的多种分辨率。此外,数据集中的目标形状多样,包括点目标、斑点目标和扩展目标,适用于不同成像系统的评估。这些特性使得WideIRSTD成为评估资源受限条件下红外小目标检测性能的理想选择。
使用方法
WideIRSTD数据集主要用于评估在资源受限条件下的红外小目标检测性能。用户可以通过下载WideIRSTD-Weak和WideIRSTD-Full数据集进行训练和测试。对于Track 1,用户可以使用WideIRSTD-Weak数据集进行弱监督训练,而Track 2则使用WideIRSTD-Full数据集进行像素级监督训练。数据集的下载链接和相关代码、模型检查点均在GitHub页面提供,方便用户进行实验和验证。
背景与挑战
背景概述
WideIRSTD数据集是为2024年国际模式识别会议(ICPR)资源受限红外小目标检测挑战而创建的。该数据集由国防科技大学(NUDT)团队主导开发,整合了七个公开数据集及NUDT自主研发的数据集,涵盖了多种目标形状、波长、图像分辨率和成像系统。WideIRSTD数据集的核心研究问题在于评估在资源受限条件下红外小目标检测(IRSTD)的性能,这对于军事监控、遥感成像等领域具有重要意义。
当前挑战
WideIRSTD数据集面临的挑战主要集中在两个方面:一是如何在资源受限条件下实现高效的红外小目标检测,这包括在弱监督和轻量级监督下的检测性能优化;二是数据集构建过程中遇到的多样化数据整合与标注难题,如不同波长和分辨率图像的统一处理,以及真实与模拟数据的融合。此外,数据集的评估标准和方法也需要不断优化,以确保检测算法的公平性和有效性。
常用场景
经典使用场景
WideIRSTD数据集在红外小目标检测领域中具有经典应用,主要用于评估在资源受限条件下的红外小目标检测性能。该数据集包含多种目标形状、波长和图像分辨率的图像,适用于不同成像系统的红外小目标检测任务。例如,在Track 1中,数据集用于弱监督条件下的红外小目标检测,而在Track 2中,则用于轻量级像素级监督的红外小目标检测。
解决学术问题
WideIRSTD数据集解决了红外小目标检测中的多个学术研究问题,特别是在资源受限条件下的检测性能评估。通过提供多样化的数据集,该数据集有助于研究人员开发和验证新的检测算法,特别是在弱监督和轻量级监督条件下。这不仅推动了红外小目标检测技术的发展,还为实际应用中的资源优化提供了理论支持。
衍生相关工作
WideIRSTD数据集的发布和应用催生了多项相关研究工作。例如,基于该数据集,研究人员开发了多种红外小目标检测算法,如DNANet_LESPS_coarse和Weighted Res-UNet。这些算法不仅在学术界引起了广泛关注,还在实际应用中展示了良好的性能。此外,该数据集还促进了红外成像技术在不同领域的应用研究,推动了红外小目标检测技术的进一步发展。
以上内容由遇见数据集搜集并总结生成


