OpenWhistle-1.0-Classification-Finetuning
收藏Hugging Face2026-04-23 更新2026-04-24 收录
下载链接:
https://huggingface.co/datasets/dolphinteam/OpenWhistle-1.0-Classification-Finetuning
下载链接
链接失效反馈官方服务:
资源简介:
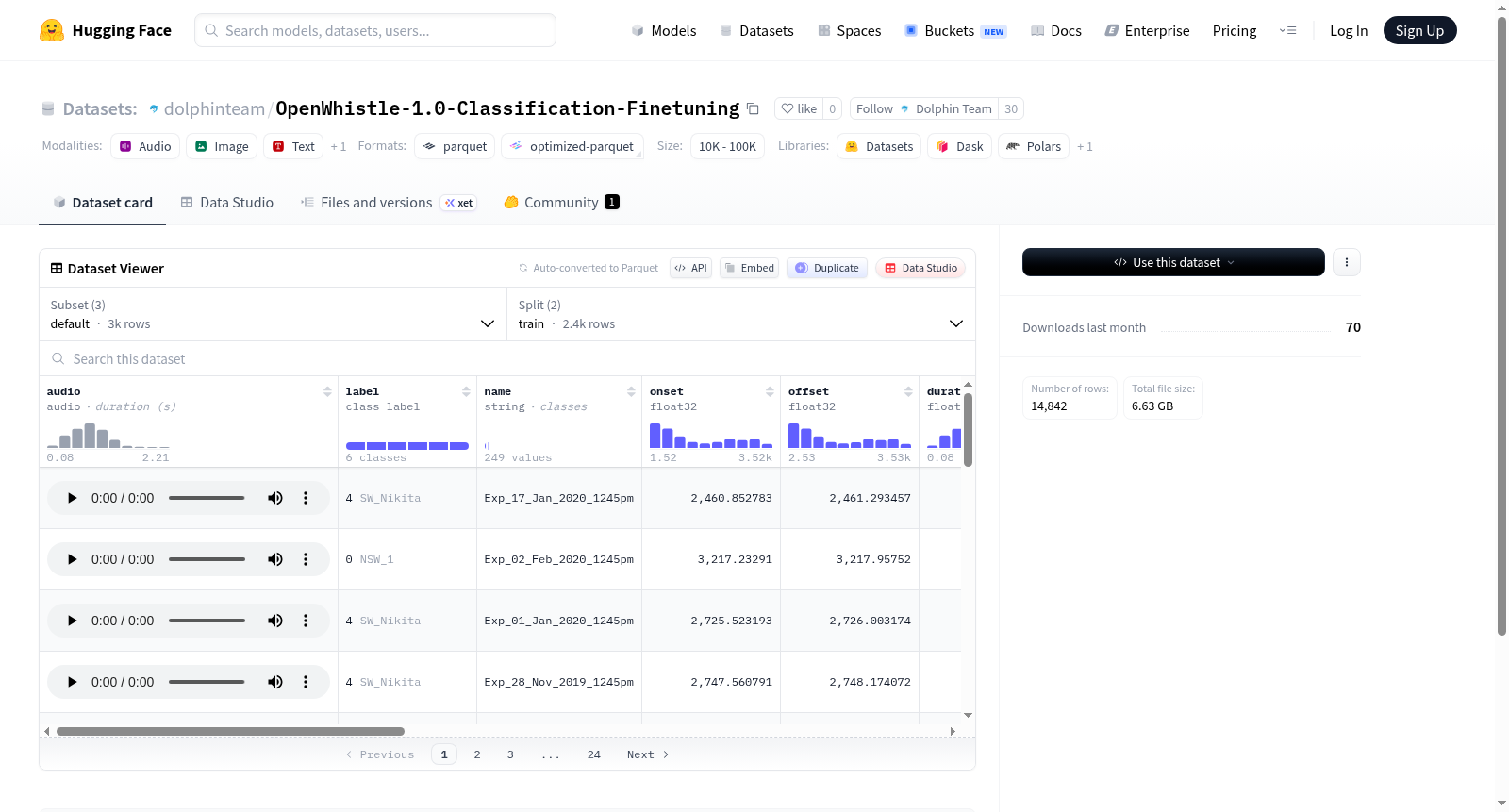
该数据集包含三种配置:all、default和unbalanced,每种配置具有不同的特征和分割。数据集主要由音频文件组成,并附带有丰富的元数据,包括标签、起始时间、结束时间、持续时间以及多种与频率相关的特征。数据集被划分为训练集和测试集,每种分割的具体字节大小和样本数量均有详细说明。适用于音频分类、声音识别等任务。
创建时间:
2026-04-20
原始信息汇总
数据集概述:OpenWhistle-1.0-Classification-Finetuning
基本信息
- 数据集名称:OpenWhistle-1.0-Classification-Finetuning
- 数据集地址:https://huggingface.co/datasets/dolphinteam/OpenWhistle-1.0-Classification-Finetuning
- 提供者:dolphinteam
数据集配置
该数据集包含三个配置(config):
1. all 配置
- 标签类别:共10个类别,包括:
- 非哨声类别:NSW_3、NSW_2、NSW_1
- 哨声类别:SW_Dana、SW_Luna、SW_Nana、SW_Neo、SW_Nikita、SW_Shy、SW_Yosefa
- 数据划分:
- 训练集:6,683 个样本,大小约 2.99 GB
- 测试集:1,671 个样本,大小约 751 MB
- 总大小:约 3.75 GB
2. default 配置
- 标签类别:共6个类别,包括:
- 非哨声类别:NSW_1
- 哨声类别:SW_Luna、SW_Nana、SW_Neo、SW_Nikita、SW_Yosefa
- 数据划分:
- 训练集:2,400 个样本,大小约 1.06 GB
- 测试集:600 个样本,大小约 266 MB
- 总大小:约 1.33 GB
3. unbalanced 配置
- 标签类别:共10个类别,与 all 配置相同(NSW_3、NSW_2、NSW_1、SW_Dana、SW_Luna、SW_Nana、SW_Neo、SW_Nikita、SW_Shy、SW_Yosefa)
- 数据划分:
- 训练集:2,790 个样本,大小约 1.24 GB
- 测试集:698 个样本,大小约 308 MB
- 总大小:约 1.55 GB
数据特征
每个样本包含以下字段:
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| audio | Audio | 音频数据(未解码) |
| label | ClassLabel | 类别标签(不同配置下类别数量不同) |
| name | string | 样本名称 |
| onset | float32 | 起始时间 |
| offset | float32 | 结束时间 |
| duration | float32 | 持续时间 |
| recording_duration | float32 | 录音时长 |
| whistle_type | int64 | 哨声类型 |
| whistle_name | string | 哨声名称 |
| f0_time | list of float32 | 基频时间序列 |
| f0_hz | list of float32 | 基频频率(Hz) |
| f0_conf | list of float32 | 基频置信度 |
| f0_ok | bool | 基频是否有效 |
| f0_bad_reason | string | 基频无效原因 |
| f0_spectrogram | image | 基频频谱图 |
数据用途
该数据集适用于哨声分类微调任务,主要针对鲸类的哨声(Whistle)进行分类,包含非哨声类别(NSW系列)和不同个体哨声类别(SW系列)。
搜集汇总
数据集介绍
构建方式
OpenWhistle-1.0-Classification-Finetuning数据集专为海豚哨声分类任务构建,其构建过程凝聚了海洋声学与生物行为学的交叉智慧。数据源自野外录制的海豚发声片段,经由专家标注获取每个哨声的起始时间(onset)、结束时间(offset)及持续时间(duration),并依据个体及哨声类型(whistle_type)赋予标签。数据集针对每段音频提取了基频轨迹(f0_time与f0_hz)、基频置信度(f0_conf)及基频频谱图(f0_spectrogram)等精细声学特征,同时标记了基频异常原因(f0_bad_reason),从而建立起一个结构完整、维度丰富的分类资源。
特点
该数据集在配置上展现了高度的灵活性与适应性。它提供了三种子配置——'all'(全量类别,含10个标签)、'default'(简化类别,含6个标签)和'unbalanced'(非均衡分布,亦含10个标签),分别对应不同的研究场景与模型需求。每条样本不仅包含解码前的原始音频,还囊括了记录时长(recording_duration)与基频可靠性标志(f0_ok)等元信息,便于进行质量过滤与声学分析。训练与测试集按约4:1的比例划分,其中'all'配置包含6683条训练样本和1671条测试样本,覆盖九种非社交哨声(NSW)及多种社交哨声(SW)类别,为小样本学习与类别不平衡探究提供了理想的数据基础。
使用方法
使用该数据集进行模型微调时,研究人员可通过HuggingFace的datasets库按配置名称(如'all'或'default')直接加载。音频字段以非解码形式存储,推荐在训练流水线中利用transformers库的音频特征提取器进行实时解码与重采样。标签字段预先定义了类别名称,可直接映射至分类头输出。附带的时间戳与基频信息可作为辅助特征输入多模态网络,或将f0_spectrogram图像与音频特征融合以提升辨识精度。此外,f0_ok标志可用于剔除基频不可靠的样本,确保模型训练的纯净度与鲁棒性。
背景与挑战
背景概述
OpenWhistle-1.0-Classification-Finetuning数据集于近年来由海洋生物声学领域的研究团队构建,旨在解决鲸豚类动物哨声信号的个体识别难题。该数据集聚焦于宽吻海豚的签名哨声(SW)与非签名哨声(NSW)的分类任务,涵盖10个哨声类别(包括SW_Dana、SW_Luna等具体个体),并提供了音频、基频轨迹、语谱图等多模态特征。通过精心标注的6683个训练样本和1671个测试样本,该数据集为基于深度学习的海洋哺乳动物声学监测提供了标准化基准,推动了生态学研究中非侵入式个体追踪技术的发展,尤其在濒危物种保护与海洋环境评估领域具有重要影响。
当前挑战
数据集面临的核心挑战在于:1)哨声类别间的高度相似性与个体差异性,使得传统声学特征难以有效区分SW与NSW,需依赖深度网络学习细微的频谱-时序模式;2)野外录音中环境噪声(如船舶引擎、水流声)与低信噪比问题严重干扰模型泛化能力,要求构建鲁棒的特征提取策略;3)数据构建过程中,从长达数十小时的实地录音中精准检测并标注哨声片段需耗费大量人力,且专家对模糊边界的分类存在主观不一致性,导致标注质量潜在妥协。此外,不平衡的类别分布(如NSW_3样本稀少)进一步加剧了模型过拟合风险。
常用场景
经典使用场景
在海洋哺乳动物声学研究的广袤领域中,OpenWhistle-1.0-Classification-Finetuning 数据集犹如一座精心雕琢的灯塔,照亮了鲸豚类口哨声分类与微调的前沿探索。该数据集汇聚了来自不同个体的鲸豚口哨声学样本,涵盖非社会性口哨(NSW)与社会性口哨(SW)两大类别,并细分为十种个体标签。其经典应用在于构建高精度分类模型,通过监督学习框架对鲸豚个体进行身份识别,为学者提供了标准化基准,以评估和优化声学分类算法的性能。数据集还特别设计了三种配置,包括平衡与不平衡版本,使得研究者能够深入探讨类别不平衡对模型鲁棒性的影响,从而推动细粒度声学分类技术的不断精进。
解决学术问题
长久以来,鲸豚个体识别依赖视觉标记或基因采样,面临高成本、侵入性强且难以规模化等困境。OpenWhistle-1.0 数据集的问世,为解决这些学术瓶颈开辟了新路径。它通过提供带有精确标注的声学事件(如起点、终点、基频轨迹等),使得研究者能够运用深度学习方法,从口哨声信号中自动抽取判别性特征,实现非侵入式个体识别。该数据集促使学术界能够系统性地探究不同社会环境(如孤独与社交状态)对发声模式的影响,并量化口哨声的声学变异,从而解答鲸豚通讯系统中个体独特性与社群交互的深层规律。其意义在于为动物声学、行为生态学与计算生物学的交叉融合提供了可复现的实验基石。
衍生相关工作
围绕 OpenWhistle-1.0 数据集,学术界已萌发出一系列具有启示性的衍生工作。其中,声学特征提取与表示学习成为热点,研究者利用基频轮廓(f0_time, f0_hz)与频谱图等多模态信息,探索自监督预训练模型在鲸豚声学上的迁移能力。此外,数据集中的时间边界(onset, offset)与口哨类型标签,激发了关于序列建模与事件检测的算法革新,例如利用时序卷积网络(TCN)或 Transformer 架构,对连续声学流中的个体发声进行分割与分类。更进一步,该数据集还催生了跨物种声学对比的研究,借鉴人类语音识别中的说话人验证技术,发展针对鲸豚个体的“声纹”识别系统,推动动物声学信息安全与生物识别技术的交叉创新。
以上内容由遇见数据集搜集并总结生成


