ViRL39K
收藏Hugging Face2025-04-21 更新2025-04-22 收录
下载链接:
https://huggingface.co/datasets/TIGER-Lab/ViRL39K
下载链接
链接失效反馈官方服务:
资源简介:
ViRL39K(读作“viral”)是一个经过精心策划的、包含38,870个可验证问答对的数据集,用于视觉语言强化学习训练。它基于新收集的问题和现有数据集构建,并经过了清洗、重构、改写和验证。ViRL39K为最先进的视觉语言推理模型VL-Rethinker提供了基础,具有高质量、可验证性、覆盖全面的话题和类别,并提供了详细的模型能力注释,指导在不同规模模型训练时选择适当的查询。
ViRL39K (pronounced "viral") is a meticulously curated dataset containing 38,870 verifiable question-answer pairs for visual-language reinforcement learning training. It is built upon newly collected questions and existing datasets, and has undergone cleaning, restructuring, rewriting, and validation. ViRL39K serves as the foundational resource for the state-of-the-art visual-language reasoning model VL-Rethinker, featuring high quality, verifiability, comprehensive coverage of topics and categories, as well as detailed model capability annotations that guide the selection of appropriate queries during model training across different scales.
提供机构:
TIGER-Lab
创建时间:
2025-04-21
原始信息汇总
ViRL39K 数据集概述
1. 数据集简介
- 名称: ViRL39K (发音为"viral")
- 数据量: 38,870个可验证的问答对
- 用途: 视觉-语言强化学习训练
- 基础数据源: 新建问题及多个现有数据集(Llava-OneVision、R1-OneVision、MM-Eureka、MM-Math、M3CoT、DeepScaleR)
- 处理过程: 经过清洗、重新格式化、重新表述和验证
- 关联模型: 为SoTA视觉语言推理模型VL-Rethinker奠定基础
2. 数据集特点
- 高质量可验证: 经过严格筛选和质量控制,移除有问题或无法通过规则验证的查询
- 主题全面: 涵盖从小学问题到STEM和社会主题的广泛领域
- 多样化推理: 包含图表、图解、表格、文档、空间关系等推理
- 能力标注: 提供细粒度的模型能力注释,指导不同规模模型的训练查询选择
3. 数据集统计
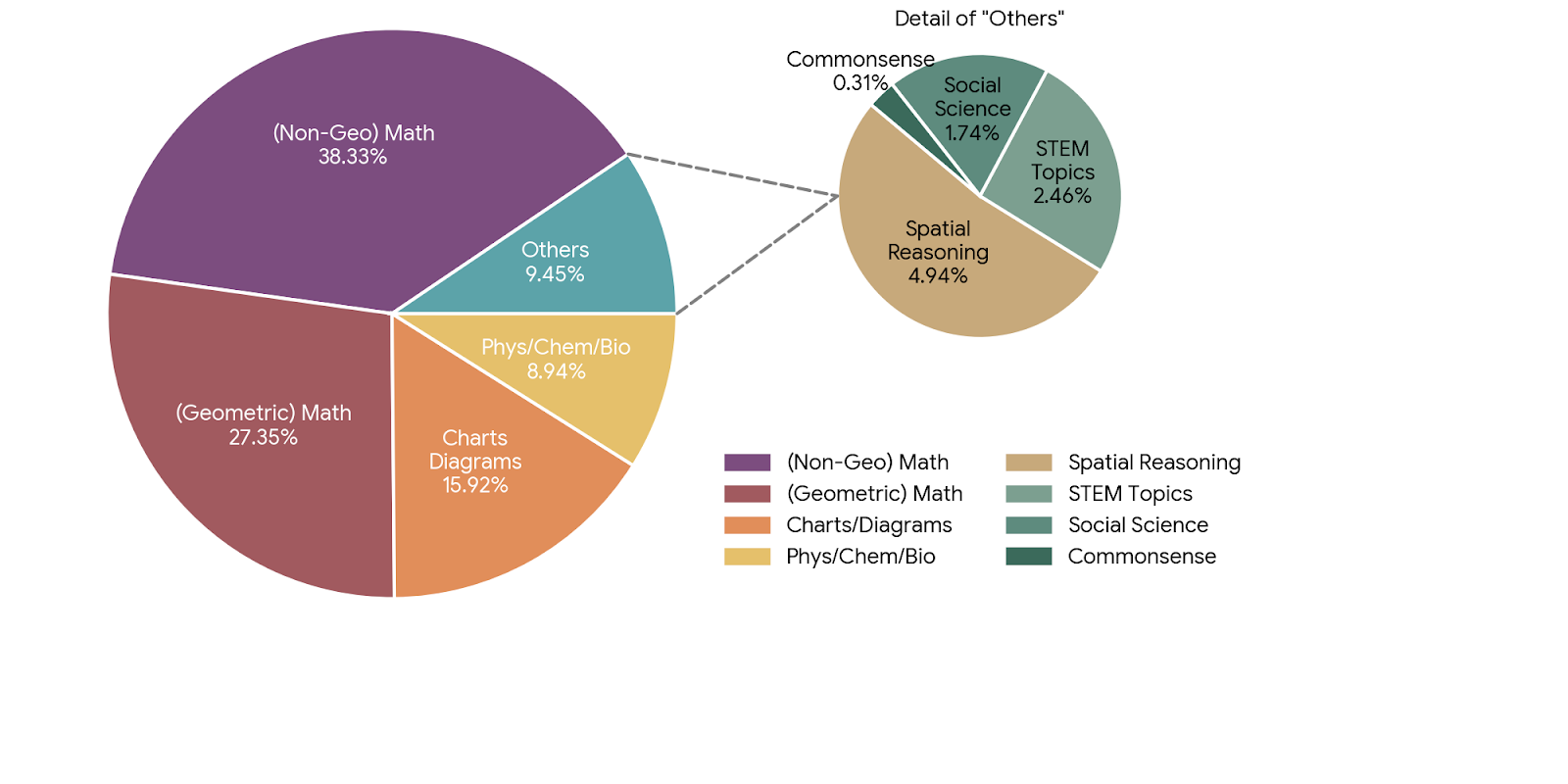
3.1 主要类别
- 覆盖8个主要类别
3.2 难度级别
- 针对不同规模模型提供不同难度级别

- 每个查询带有反映模型能力亲和力的PassRate标注
4. 相关资源
5. 引用信息
bibtex @article{vl-rethinker, title={VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning}, author = {Wang, Haozhe and Qu, Chao and Huang, Zuming and Chu, Wei and Lin,Fangzhen and Chen, Wenhu}, journal={arXiv preprint arXiv:2504.08837}, year={2025} }
搜集汇总
数据集介绍
构建方式
在视觉语言强化学习领域,ViRL39K数据集的构建体现了严谨的跨数据集整合策略。该数据集以六个权威视觉问答数据集为基础素材,通过多阶段标准化处理流程:原始问题经过清洗去除噪声数据,重新格式化确保结构统一,语义重述增强表达多样性,并采用规则引擎进行可验证性筛选。特别值得注意的是,构建过程引入了模型能力适配标注机制,为不同规模模型的训练需求提供了科学的数据划分依据。
特点
作为视觉语言推理研究的基准数据集,ViRL39K展现出三大核心特征:其问题解答对均通过可验证性验证,确保每个样本具备客观真值;内容覆盖呈现多维度扩展性,从基础教育题目到STEM跨学科主题,囊括图表解析、空间关系推理等复杂认知任务;独创的模型能力标注体系将问题难度与模型规模动态关联,为渐进式训练提供量化指导。数据分布的统计可视化清晰展现了八个主要知识领域的覆盖广度与难度层级。
使用方法
该数据集的应用需结合其特有的能力标注体系进行策略性使用。研究者可根据目标模型的参数量级,选择对应PassRate区间的训练样本实现能力匹配。对于基础模型训练,建议优先采用低难度标注样本构建核心认知能力;当进行模型微调时,可阶梯式提升样本难度以增强复杂推理性能。数据集配套的类别标签系统支持特定领域能力的针对性增强,如专门筛选图表类问题提升视觉信息提取能力。与VL-Rethinker框架配合使用时,能有效驱动视觉语言模型的自我反思机制优化。
背景与挑战
背景概述
ViRL39K数据集由TIGER-AI-Lab团队于2025年构建,旨在为视觉-语言强化学习训练提供高质量的问答对集合。该数据集整合了Llava-OneVision、R1-OneVision等多个现有数据集,并经过严格的清洗、重构和验证流程,最终形成包含38,870个可验证问答对的精选资源。作为支撑前沿视觉语言推理模型VL-Rethinker的基础数据集,其覆盖从基础教育到STEM领域的广泛主题,特别擅长处理图表、空间关系等复杂模态的推理任务。该数据集的创新性在于引入了细粒度的模型能力标注系统,为不同规模模型的训练提供了精准的能力适配指导。
当前挑战
构建ViRL39K面临的核心挑战在于多模态数据的质量把控与能力适配。在领域问题层面,视觉语言模型需要同时处理图像理解、文本推理及跨模态对齐的复合挑战,这对问答对的语义完整性和逻辑严谨性提出极高要求。数据集构建过程中,研究团队需攻克三大技术难点:原始数据的噪声过滤与标准化重构需设计自动化验证规则;跨数据集的知识融合需保持语义一致性;模型能力标注系统需建立科学的难度量化标准。这些挑战的解决直接影响了最终数据集支撑模型训练的效能。
常用场景
经典使用场景
在视觉语言强化学习领域,ViRL39K数据集作为高质量问答对的集合,为训练和评估视觉语言模型提供了标准化基准。其涵盖从基础STEM问题到复杂空间关系推理的广泛主题,特别适用于多模态模型的微调和能力验证。研究人员可依据其细粒度的模型能力标注,针对不同规模模型选择适配的训练样本,显著提升模型在跨模态理解任务中的表现。
实际应用
在教育科技领域,ViRL39K支撑了智能辅导系统的开发,能够解析包含图表、公式的复杂题目并生成分步解答。工业场景中,其多模态推理能力被应用于自动化报告生成系统,可将技术图纸转换为结构化描述。医疗领域则利用其文档理解特性,开发出能够交叉分析医学影像与诊断记录的辅助诊断工具。
衍生相关工作
基于ViRL39K诞生的VL-Rethinker框架开创了视觉语言模型的自我反思训练范式,相关论文被ICLR等顶会收录。其衍生研究包括多模态思维链推理技术MMCoT、文档视觉问答系统DocVQA-RL等,这些工作均在模型可解释性与推理能力方面取得突破,形成视觉语言强化学习的完整方法论体系。
以上内容由遇见数据集搜集并总结生成


