CCLV/CausalBench
收藏Hugging Face2024-06-13 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/CCLV/CausalBench
下载链接
链接失效反馈官方服务:
资源简介:
CausalBench是一个综合性基准数据集,旨在评估大型语言模型(LLMs)的因果推理能力。它涵盖了代码、数学和文本三个领域的多样化任务,确保对因果推理能力进行全面评估。每个因果场景都通过四种不同的问题视角呈现:因果、果因、带干预的因果和带干预的果因,并提供了相应的正确答案。数据集包含60,000个样本,分别分布在文本、代码和数学领域。数据集的构建过程包括手动分析和生成、利用GPT-4 Turbo扩展数据集以及通过因果推理引擎和人工专家审查进行质量控制。
CausalBench是一个综合性基准数据集,旨在评估大型语言模型(LLMs)的因果推理能力。它涵盖了代码、数学和文本三个领域的多样化任务,确保对因果推理能力进行全面评估。每个因果场景都通过四种不同的问题视角呈现:因果、果因、带干预的因果和带干预的果因,并提供了相应的正确答案。数据集包含60,000个样本,分别分布在文本、代码和数学领域。数据集的构建过程包括手动分析和生成、利用GPT-4 Turbo扩展数据集以及通过因果推理引擎和人工专家审查进行质量控制。
提供机构:
CCLV
原始信息汇总
CausalBench Dataset Summary
Dataset Overview
- Name: CausalBench
- Collaborators: UCLA, JHU
- Domains: Code, Math, Text
- Total Samples: 60,000 problems (40,000 in text domain, 10,000 in code domain, 10,000 in math domain)
- Language: English
Dataset Structure
-
CausalBench_Code_Part.csv:
- Columns: Scenario, Type, Question, Answer, Explanation
- Question Types: Cause-to-Effect, Effect-to-Cause, Cause-to-Effect with Intervention, Effect-to-Cause with Intervention
-
CausalBench_Math_Part.csv:
- Columns: Scenario, Type, Question, Answer, Explanation
- Question Types: Cause-to-Effect, Effect-to-Cause, Cause-to-Effect with Intervention, Effect-to-Cause with Intervention
-
CausalBench_Text_Part.csv:
- Columns: Scenario, Type, Question, Answer, Explanation
- Question Types: Cause-to-Effect, Effect-to-Cause, Cause-to-Effect with Intervention, Effect-to-Cause with Intervention
Usage
- Purpose: Evaluating causal reasoning capabilities of large language models, conducting research on causal inference in AI, developing and benchmarking new models for causal reasoning.
Data Collection and Construction
- Process: Manual analysis and generation, scaling up with LLMs, quality control through causal inference engine and human expert review.
Dataset Access
- Files:
- CausalBench_Code_Part.csv
- CausalBench_Math_Part.csv
- CausalBench_Text_Part.csv
搜集汇总
数据集介绍
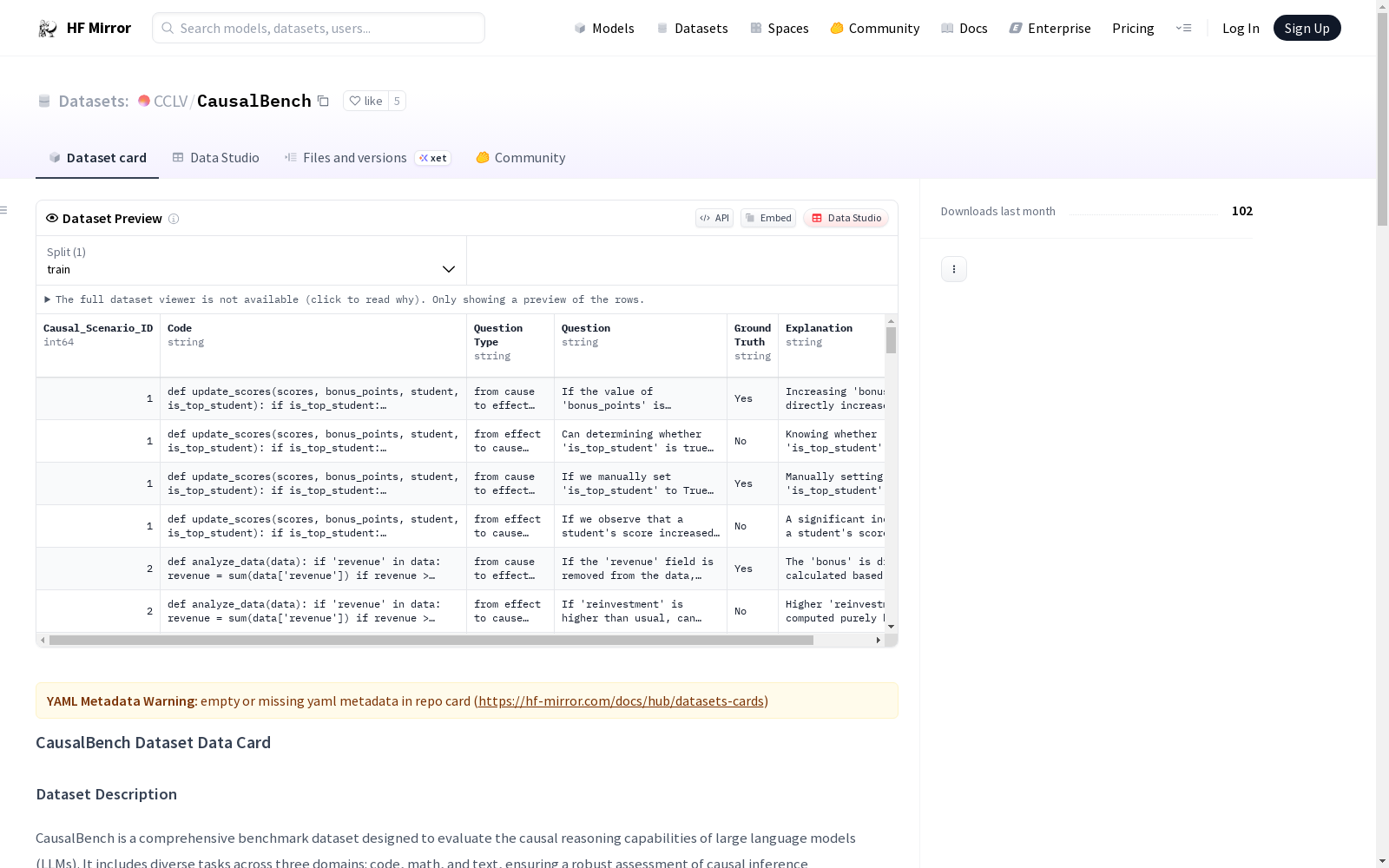
构建方式
CausalBench数据集的构建,始于一一对应的因果图与条件概率分析,进而手动生成初始案例及答案。随后,借助GPT-4 Turbo的生成能力,通过少量样本提示,实现了数据集在代码、数学、文本三大领域的规模扩展。每一步构建均经过因果推理引擎的校验,并辅以人类专家的细致审查,确保了问题与答案的准确性与可靠性。
特点
CausalBench数据集特色在于其全面覆盖因果推理任务的多维度与复杂性,包含60,000个问题,跨越代码、数学、文本三个领域。每个因果情景均从四个不同的视角提出问题,包括原因到结果、结果到原因以及干预条件下的两种情形,为评估大型语言模型的因果推理能力提供了全面且多元的基准。
使用方法
使用CausalBench数据集,研究者可以评估大型语言模型的因果推理能力,进行人工智能领域的因果推断研究,以及开发与基准化新的因果推理模型。数据集通过HuggingFace平台提供访问,用户可以直接下载CSV文件进行相关研究与应用。
背景与挑战
背景概述
CausalBench数据集,由UCLA与JHU合作研发,旨在评估大型语言模型在因果推理方面的能力。该数据集涵盖代码、数学和文本三个领域,包含60,000个问题,其中40,000个属于文本领域,10,000个属于代码领域,另外10,000个属于数学领域。数据集采用英语编写,为研究者在人工智能领域的因果推断研究提供了丰富的资源和基准测试平台。
当前挑战
CausalBench数据集面临的挑战主要涉及两个方面:一是如何在多样化的因果推理任务中保持数据的质量和准确性;二是如何在代码、数学和文本三个领域构建平衡且具有挑战性的问题,以全面评估模型的因果推理能力。在构建过程中,研究者通过手动分析和生成初始案例,利用大型语言模型扩展数据集,并通过因果推理引擎及人类专家进行质量控制,确保了数据集的可靠性和准确性。
常用场景
经典使用场景
在人工智能领域,CausalBench数据集作为评估大规模语言模型因果推理能力的基准,其经典使用场景在于对代码、数学和文本三大领域的因果情景进行深入分析。该数据集通过提供四种问题视角,即原因到结果、结果到原因、带有干预的原因到结果以及带有干预的结果到原因,为研究者提供了一个全面评估模型因果推理能力的平台。
实际应用
在现实应用中,CausalBench数据集的应用范围广泛,它不仅可以用于评估和改进AI模型的因果推理能力,还可以为开发新的机器学习模型提供标准化的测试平台,进而在自然语言处理、自动化编程和数学问题解决等领域发挥重要作用。
衍生相关工作
基于CausalBench数据集,学术界已经衍生出一系列相关研究工作,包括对现有模型的改进、新型因果推理模型的开发以及在不同领域的应用研究。这些工作进一步扩展了我们对因果推理在AI中的应用和理解,为人工智能领域的发展贡献了重要成果。
以上内容由遇见数据集搜集并总结生成


