paligemma-valorant-object-detection-transformed
收藏Hugging Face2025-08-29 更新2025-08-30 收录
下载链接:
https://huggingface.co/datasets/umairhassan02/paligemma-valorant-object-detection-transformed
下载链接
链接失效反馈官方服务:
资源简介:
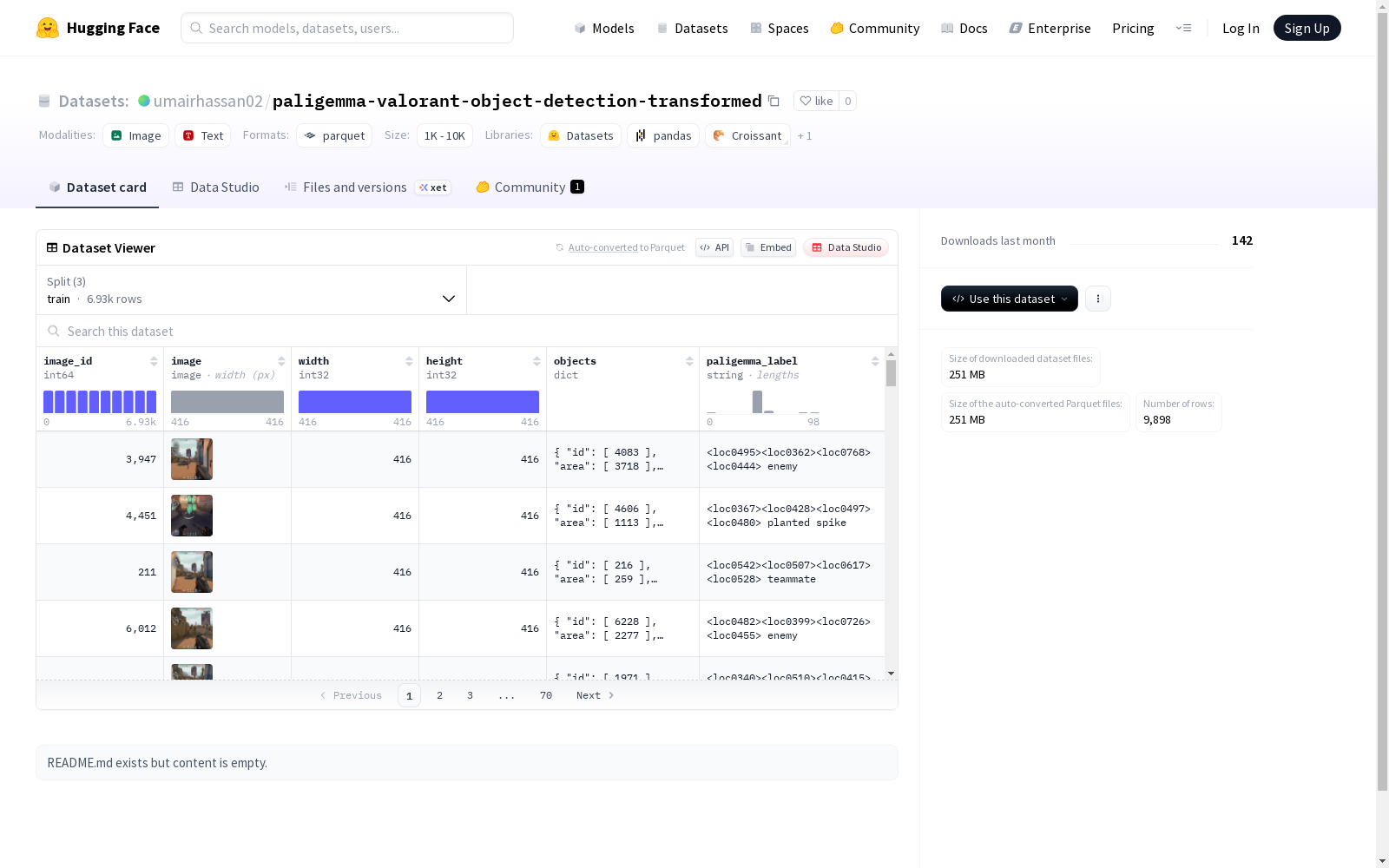
这是一个包含图片和其相关信息的图像数据集,其中包括图片ID、图片内容、图片宽高、物体信息(物体ID、面积、边界框坐标和类别)以及一个标签。数据集分为训练集、验证集和测试集,适用于图像识别和分类任务。物体类别包括:掉落的刺、敌人、种植的刺和队友。
创建时间:
2025-08-19
原始信息汇总
数据集概述
基本信息
- 数据集名称:umairhassan02/paligemma-valorant-object-detection-transformed
- 下载大小:250,795,597 字节
- 数据集大小:251,214,724.008 字节
数据特征
- 图像标识符:image_id(int64)
- 图像数据:image(image)
- 图像宽度:width(int32)
- 图像高度:height(int32)
- 目标对象:objects(序列)
- 对象标识符:id(int64)
- 区域面积:area(int64)
- 边界框:bbox(float32序列,长度4)
- 类别:category(类别标签)
- 0: dropped spike
- 1: enemy
- 2: planted spike
- 3: teammate
- PaliGemma标签:paligemma_label(string)
数据划分
- 训练集:6,927 个样本(175,936,828.359 字节)
- 验证集:1,983 个样本(50,292,947.649 字节)
- 测试集:988 个样本(24,984,948.0 字节)
配置信息
- 默认配置:default
- 数据文件路径:
- 训练集:data/train-*
- 验证集:data/validation-*
- 测试集:data/test-*
搜集汇总
数据集介绍
构建方式
在电子竞技视觉分析领域,该数据集基于热门游戏《Valorant》的实时画面构建,通过专业标注工具对游戏场景中的关键对象进行精细化标注。构建过程涵盖6927张训练图像、1983张验证图像及988张测试图像,每张图像均包含四类目标对象的边界框坐标与类别标签,并特别集成了PaliGemma多模态模型所需的文本化标注格式。
使用方法
研究者可借助该数据集开展多模态目标检测模型的训练与验证,尤其适用于视觉-语言联合建模任务。数据集已预划分为标准训练集、验证集和测试集,支持端到端模型训练流程。用户可通过加载图像数据与对应的PaliGemma文本标签,实现目标检测任务与视觉问答任务的协同训练,或直接用于评估模型在游戏场景下的泛化性能。
背景与挑战
背景概述
在电子竞技与计算机视觉交叉研究领域,Valorant作为多人在线战术射击游戏,其动态环境中的实时目标检测对游戏AI开发具有重要意义。该数据集由专业研究团队于2024年构建,专注于解决游戏内关键实体(如掉落/安放炸弹、敌友单位)的精准识别问题,通过标注6927组训练样本与1983组验证样本,为强化学习与战术决策模型提供高质量基准数据,推动了游戏人工智能在复杂交互场景中的研究进展。
当前挑战
数据集核心挑战在于解决游戏画面中多尺度目标的实时检测难题,特别是小尺寸武器与角色在动态光影环境下的区分;构建过程中需克服游戏画面渲染差异导致的标注一致性問題,同时需设计专用标注规范以区分高度相似的实体类别(如掉落与安放状态的炸弹),并确保边界框标注在快速移动场景中的时空一致性。
常用场景
经典使用场景
在电子竞技视觉分析领域,该数据集为《Valorant》游戏场景中的目标检测任务提供了专门标注的视觉数据。其经典使用场景集中于训练深度学习模型识别游戏画面中的关键元素,包括敌方玩家、队友以及游戏道具尖刺的两种状态(掉落或已安装)。通过提供精确的边界框标注和类别信息,研究者能够构建高效的实时目标检测系统,用于分析游戏画面并提取战术信息。
解决学术问题
该数据集有效解决了游戏人工智能研究中视觉感知模块的标注数据稀缺问题。通过提供大规模高质量的游戏场景标注数据,它支持学术界研究复杂动态环境下的目标检测算法鲁棒性。特别地,该数据集使得研究者能够探索多类别目标在非控制环境下的检测挑战,包括遮挡处理、尺度变化和实时性能优化等关键学术问题,推动了游戏AI视觉理解技术的发展。
实际应用
在实际应用层面,该数据集支撑的游戏目标检测技术可直接应用于电竞训练分析和实时战术辅助系统。职业战队可利用基于该数据训练的模型进行比赛录像分析,自动识别球员位置和道具状态,生成战术统计报告。直播平台可集成该技术提供实时比赛解说增强功能,自动高亮显示关键游戏事件,提升观众观赛体验。
数据集最近研究
最新研究方向
在电子竞技视觉分析领域,基于《Valorant》游戏场景的目标检测数据集正推动多模态学习与实时决策系统的深度融合。研究者聚焦于利用PaliGemma等视觉-语言模型提升对游戏内关键对象(如掉落/安放炸弹、敌友识别)的检测精度与上下文理解能力。当前热点集中于通过时空上下文建模增强动态场景下的目标追踪鲁棒性,同时探索轻量化部署以适应实时战术分析需求。此类研究不仅助力游戏AI的战术推理自动化,也为军事模拟、机器人环境感知等跨领域应用提供泛化性验证基础。
以上内容由遇见数据集搜集并总结生成


