Error-Data
收藏Hugging Face2024-12-09 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/stanley-Lee/Error-Data
下载链接
链接失效反馈官方服务:
资源简介:
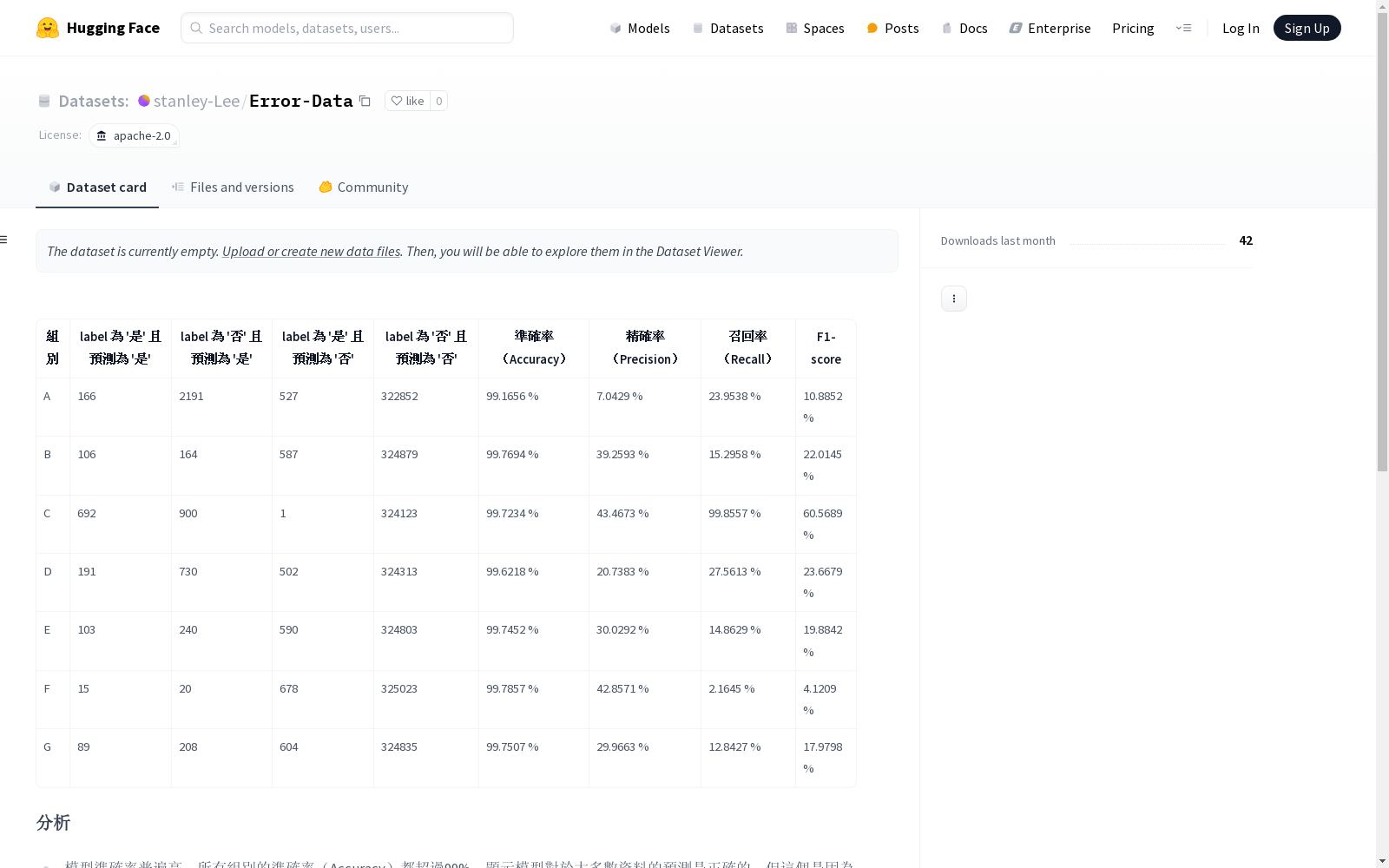
数据集包含多个组别的分类模型性能评估结果,涵盖准确率、精确率、召回率和F1-score。所有组别的准确率均超过99%,但由于实际不相同的商品数量占大多数,高准确率并不代表模型表现良好。精确率和召回率在各组别间差异较大,特别是组别F的召回率极低,表明模型漏掉了许多'是'的样本。建议通过特征工程和模型优化来改进低表现组别的性能,特别是针对召回率较低的组别。
创建时间:
2024-12-07
原始信息汇总
Error-Data 数据集概述
数据集描述
该数据集包含多个组别的分类结果,每个组别提供了以下指标:
- 准确率(Accuracy)
- 精确率(Precision)
- 召回率(Recall)
- F1-score
数据集指标
| 组别 | label 为 是 且预测为 是 | label 为 否 且预测为 是 | label 为 是 且预测为 否 | label 为 否 且预测为 否 | 准确率(Accuracy) | 精确率(Precision) | 召回率(Recall) | F1-score |
|---|---|---|---|---|---|---|---|---|
| A | 166 | 2191 | 527 | 322852 | 99.1656 % | 7.0429 % | 23.9538 % | 10.8852 % |
| B | 106 | 164 | 587 | 324879 | 99.7694 % | 39.2593 % | 15.2958 % | 22.0145 % |
| C | 692 | 900 | 1 | 324123 | 99.7234 % | 43.4673 % | 99.8557 % | 60.5689 % |
| D | 191 | 730 | 502 | 324313 | 99.6218 % | 20.7383 % | 27.5613 % | 23.6679 % |
| E | 103 | 240 | 590 | 324803 | 99.7452 % | 30.0292 % | 14.8629 % | 19.8842 % |
| F | 15 | 20 | 678 | 325023 | 99.7857 % | 42.8571 % | 2.1645 % | 4.1209 % |
| G | 89 | 208 | 604 | 324835 | 99.7507 % | 29.9663 % | 12.8427 % | 17.9798 % |
数据集分析
- 模型准确率普遍高:所有组别的准确率(Accuracy)都超过99%,但这是由于实际不相同的商品数量占大多数。
- 实际相同与不相同的占比:
- 实际相同共有 693 笔,占比为 0.21%。
- 实际不相同共有 325,043 笔,占比为 99.79%。
- 精确率和召回率差异较大:
- 精确率(Precision):除去组别 C 之外,D 组有最高的精确率(23.6679%)。
- 组别 F 的召回率非常低(2.1645%),表示漏掉了许多"是"的样本。
注意事项
- 组别间表现差异:组别 F 的表现需要重点关注,尤其是召回率极低,可能表示该组数据的特征与模型匹配性很差。
- 平衡精确率与召回率:高准确率不一定代表模型表现良好,需根据任务需求调整精确率与召回率的平衡。
- 模型改进建议:
- 特征工程:加强低表现组别的数据特征提取,增加有助于分类的特征。
- 调参与模型优化:尝试不同模型或超参数调整,特别针对组别 F 和其他低召回率组。
- F1-score 的重要性:F1-score 是评估模型综合表现的重要指标,比单独看准确率更能反映分类问题的实际效果。
搜集汇总
数据集介绍
构建方式
Error-Data数据集的构建基于对不同组别在分类任务中的表现进行详细分析。数据集通过模拟不同组别在二分类任务中的预测结果,生成了包含真实标签与预测标签的对比数据。具体而言,数据集记录了各组别在不同分类情况下的样本数量,包括‘是’且预测为‘是’、‘否’且预测为‘是’、‘是’且预测为‘否’以及‘否’且预测为‘否’的样本数。此外,数据集还计算了各组别的准确率、精确率、召回率和F1-score,以全面评估模型的分类性能。
特点
Error-Data数据集的主要特点在于其高准确率与显著的精确率和召回率差异。尽管所有组别的准确率均超过99%,但精确率和召回率在不同组别间表现出显著差异,尤其是组别C在召回率上表现突出,而组别F的召回率则极低。此外,数据集揭示了在分类任务中,高准确率并不一定意味着模型表现良好,精确率与召回率的平衡对模型性能至关重要。
使用方法
Error-Data数据集适用于评估和优化分类模型的性能。研究者可以通过分析各组别的精确率、召回率和F1-score,识别模型在不同数据集上的表现差异,并据此进行模型改进。具体使用时,可以针对低召回率的组别进行特征工程,增强数据特征提取,或通过调整模型参数和尝试不同模型来优化分类效果。此外,数据集还可用于教学和研究,帮助理解分类任务中精确率与召回率的权衡。
背景与挑战
背景概述
Error-Data数据集由一组研究人员或机构创建,旨在解决分类问题中的错误预测分析。该数据集的核心研究问题是如何在高准确率的情况下,平衡精确率与召回率,特别是在数据类别极度不平衡的场景中。通过分析不同组别的模型表现,研究人员希望揭示模型在处理少数类样本时的性能瓶颈,并为改进模型提供指导。该数据集的创建时间未明确提及,但其对分类模型评估和优化的贡献在相关领域具有重要影响力。
当前挑战
Error-Data数据集面临的挑战主要集中在两个方面。首先,尽管模型在大多数情况下表现出极高的准确率,但由于数据类别的不平衡(99.79%的样本为‘否’),精确率和召回率之间的差异显著,尤其是在少数类样本的预测上。其次,构建过程中遇到的挑战包括如何有效提取和增强低表现组别的数据特征,以及如何通过模型优化和超参数调整来提升召回率,特别是在组别F等召回率极低的场景中。这些挑战要求研究人员在模型改进时进行精确率与召回率的权衡,并寻找更有效的特征工程和模型优化策略。
常用场景
经典使用场景
Error-Data数据集在分类任务中展现了其独特的应用价值,尤其是在处理商品是否相同的高准确率预测场景中。通过分析不同组别的精确率、召回率和F1-score,研究者可以深入理解模型在不同数据特征下的表现,从而优化分类模型的性能。
解决学术问题
Error-Data数据集有效解决了分类模型在处理不平衡数据时的常见问题,特别是在高准确率掩盖下精确率和召回率的失衡现象。通过该数据集,研究者能够更全面地评估模型在实际应用中的表现,推动了分类模型在复杂数据环境下的优化研究。
衍生相关工作
基于Error-Data数据集,研究者们开发了多种改进分类模型的方法,包括特征工程的优化、模型参数的精细调整以及新型算法的引入。这些工作不仅提升了分类模型的性能,还为处理类似不平衡数据集提供了新的思路和方法。
以上内容由遇见数据集搜集并总结生成


