classla/COPA-SR
收藏COPA-SR 数据集概述
数据集描述
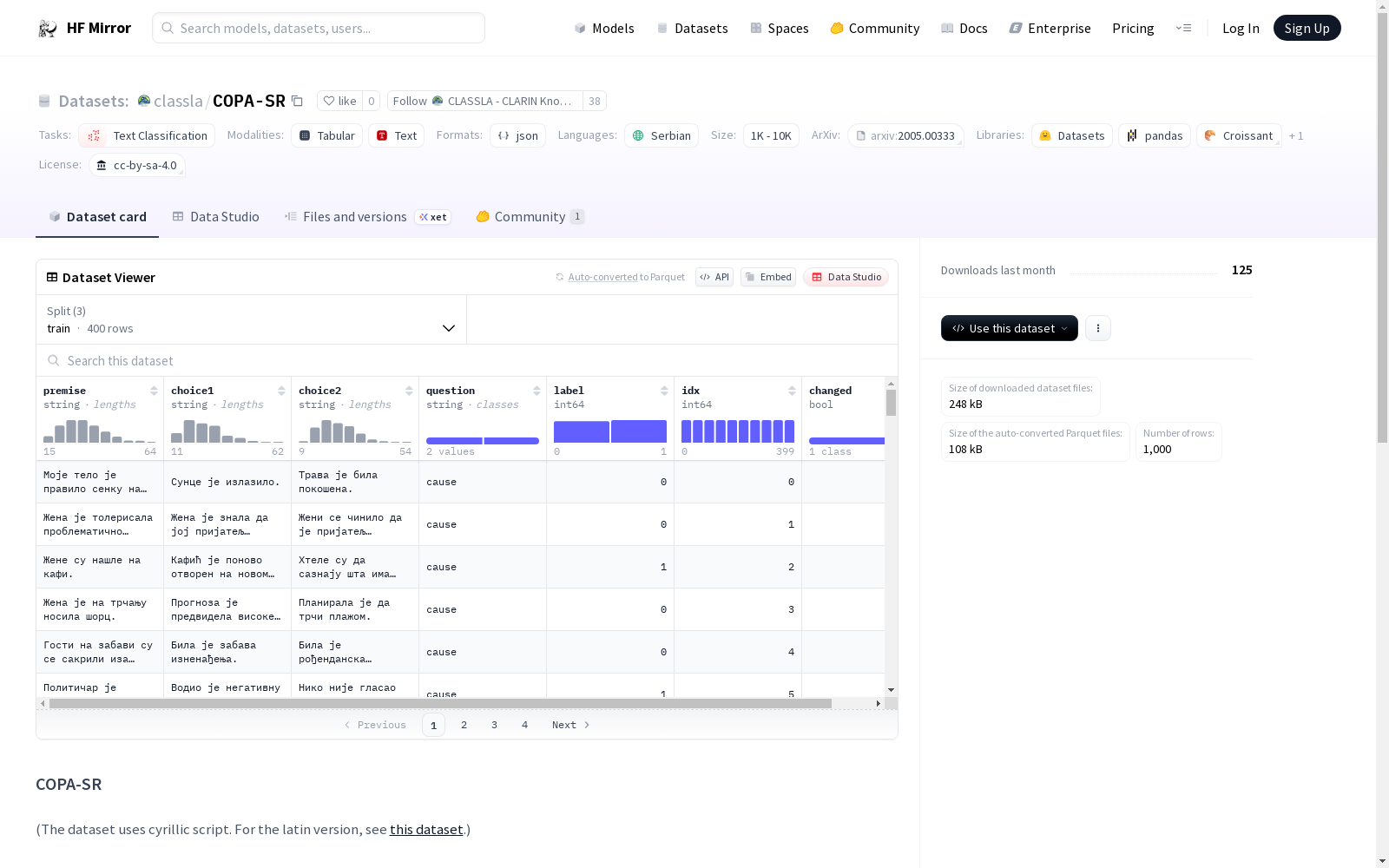
COPA-SR 数据集是一个塞尔维亚语版本的 Choice of Plausible Alternatives (COPA) 数据集,由 ReLDI Centre Belgrade 翻译自英语 COPA 数据集,遵循 XCOPA 数据集翻译方法论。
数据集内容
- 语言:塞尔维亚语
- 任务类别:文本分类
- 数据规模:小于1000条数据
- 数据格式:JSONL 文件
- 数据划分:
- 训练集:400 条数据
- 验证集:100 条数据
- 测试集:500 条数据
数据集结构
数据集包含 1,000 个前提(例如:“My body cast a shadow over the grass”),每个前提对应一个问题(“What is the cause?” 或 “What happened as a result?”),以及两个选项(例如:“The sun was rising” 和 “The grass was cut”),并有一个标签指示哪个选项更合理。
数据文件
- 训练集:
train.jsonl - 验证集:
val.jsonl - 测试集:
test.jsonl
作者信息
- Ljubešić, Nikola
- Starović, Mirjana
- Kuzman, Taja
- Samardžić, Tanja
引用信息
@misc{11356/1708, title = {Choice of plausible alternatives dataset in Serbian {COPA}-{SR}}, author = {Ljube{v s}i{c}, Nikola and Starovi{c}, Mirjana and Kuzman, Taja and Samard{v z}i{c}, Tanja}, url = {http://hdl.handle.net/11356/1708}, note = {Slovenian language resource repository {CLARIN}.{SI}}, copyright = {Creative Commons - Attribution-{ShareAlike} 4.0 International ({CC} {BY}-{SA} 4.0)}, issn = {2820-4042}, year = {2022} }