CULTURALVQA
收藏arXiv2024-07-19 更新2024-07-17 收录
下载链接:
https://culturalvqa.org/
下载链接
链接失效反馈官方服务:
资源简介:
CULTURALVQA数据集由Mila – 魁北克人工智能研究所等机构创建,是一个专注于评估视觉语言模型文化理解能力的视觉问答基准。该数据集包含2,378个问题,基于2,328个独特的图像,涵盖了来自11个国家的文化,涉及服饰、食物、饮料、仪式和传统等多个文化层面。数据集的创建过程中,通过自动收集图像和雇佣来自不同文化的标注者来收集问题和答案,旨在全面评估模型对多元文化的理解能力,并识别模型在文化理解方面的不足。
The CULTURALVQA dataset, created by institutions including Mila – Quebec Artificial Intelligence Institute, is a visual question answering benchmark focused on evaluating the cultural comprehension capabilities of vision-language models. It contains 2,378 questions based on 2,328 unique images, covering cultures from 11 countries and involving multiple cultural dimensions such as clothing, food, beverages, rituals and traditions. During the dataset construction process, images were automatically collected and annotators from diverse cultural backgrounds were hired to collect questions and answers, aiming to comprehensively evaluate models' understanding of multiculturalism and identify the shortcomings of models in cultural comprehension.
提供机构:
Mila – 魁北克人工智能研究所, Université de Montréal, McGill University, Google DeepMind
创建时间:
2024-07-16
原始信息汇总
数据集概述
标题
Benchmarking Vision Language Models for Cultural Understanding
作者
- Shravan Nayak<sup>1,2</sup>
- Kanishk Jain<sup>1,2</sup>
- Rabiul Awal<sup>1</sup>
- Siva Reddy<sup>1,3</sup>
- Sjoerd van Steenkiste<sup>4</sup>
- Lisa Anne Hendricks<sup>4</sup>
- Karolina Stanczak<sup>1,3</sup>
- Aishwarya Agrawal<sup>1,2</sup>
机构
- Mila - Quebec AI Institute<sup>1</sup>
- Université de Montréal<sup>2</sup>
- McGill University<sup>3</sup>
- Google DeepMind<sup>4</sup>
摘要
Foundation models and vision-language pre-training have notably advanced Vision Language Models (VLMs), enabling multimodal processing of visual and linguistic data. However, their performance has been typically assessed on general scene understanding - recognizing objects, attributes, and actions - rather than cultural understanding. This dataset aims to benchmark VLMs specifically for cultural understanding.
数据集内容
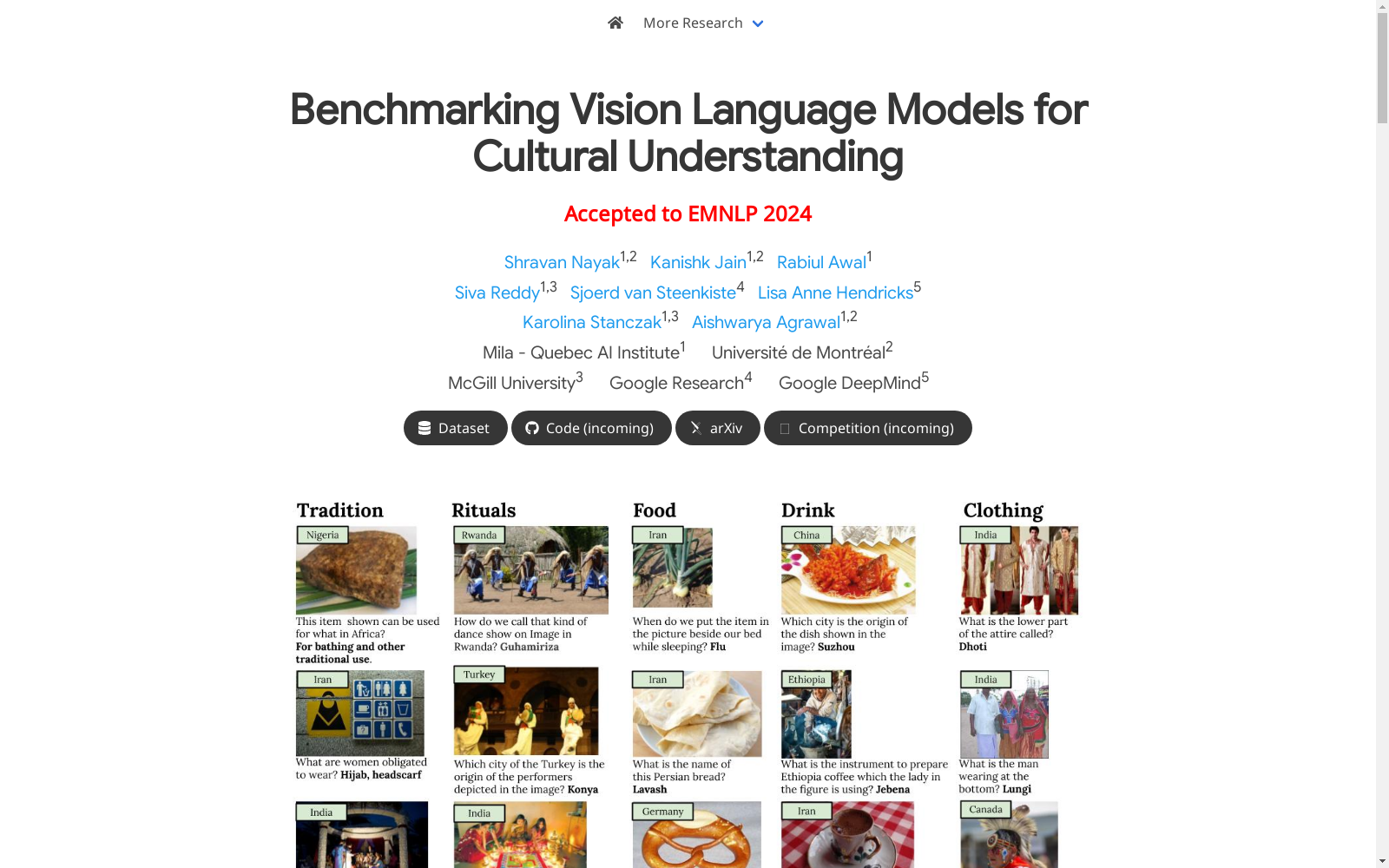
- 图像内容: 包含来自11个国家的文化概念,涵盖传统、仪式、食物、饮料和服装五个方面。
- 问题与答案: 包含针对图像中文化概念理解的问题及其答案。
数据集链接
- Dataset: Dataset (incoming)
- Code: Code (incoming)
- arXiv: arXiv
搜集汇总
数据集介绍
构建方式
CULTURALVQA数据集的构建基于视觉问答(VQA)任务,旨在评估视觉语言模型(VLM)对不同文化的理解能力。数据集包含来自11个国家、5个大陆的2378个图像-问题对,每个问题有1-5个答案。图像和问题均由了解相关文化概念的标注者收集和编写。数据集涵盖了文化各个方面的理解,如服装、食物、饮料、仪式和传统等。
特点
CULTURALVQA数据集的特点在于其地理和文化多样性。它涵盖了11个国家,代表世界各地的文化,并涉及文化概念的各个方面。数据集的问题设计旨在挑战模型的文化理解,而非简单的物体识别或属性描述。此外,数据集还通过人工标注和多种文化视角的输入,确保了答案的多样性和准确性。
使用方法
使用CULTURALVQA数据集的方法包括对视觉语言模型进行基准测试,以评估其文化理解能力。研究人员可以通过让模型回答数据集中的问题,并使用LAVE评估指标来衡量模型的性能。此外,数据集还可以用于开发新的文化理解模型,或者作为现有模型的文化知识库进行训练。
背景与挑战
背景概述
CULTURALVQA数据集是一项旨在评估视觉语言模型(VLMs)对文化理解能力的视觉问答基准。该数据集由Mila – Quebec AI Institute, Université de Montréal, McGill University, Google DeepMind等机构的研究人员创建,并在2024年发布。CULTURALVQA包含来自11个国家的2378个图像-问题对,每个问题有1-5个答案,这些国家跨越了5个大洲。这些问题探讨了文化的各个方面,如服装、食物、饮料、仪式和传统。通过对CULTURALVQA上VLMs的性能进行基准测试,包括GPT-4V和Gemini,发现它们在不同地区的文化理解能力存在差异,对北美洲的文化理解能力较强,而对非洲的绩效则显著较低。CULTURALVQA的提出为评估VLMs在理解多元文化方面的进展提供了一个全面的评估集。
当前挑战
CULTURALVQA数据集面临的主要挑战包括:1) 领域问题挑战:评估VLMs对文化的理解,这是一个复杂的任务,因为文化是一个多方面的概念,包括有形的(如服装和食物)和无形的元素(如仪式实践)。2) 构建挑战:收集具有文化信息的数据对于构建CULTURALVQA数据集是一项挑战,特别是在获取来自不同文化和地区的图像和概念时。此外,确保数据集的多样性和代表性也是一个挑战。
常用场景
经典使用场景
CULTURALVQA数据集是专为评估视觉语言模型(VLM)的文化理解能力而设计的视觉问答基准。它包含来自11个国家、5个大陆的2378个图像-问题对,每个问题有1-5个答案,涵盖了文化各个方面的理解,如服装、食物、饮料、仪式和传统。该数据集的经典使用场景是作为VLM模型的评估工具,以衡量它们对不同文化的理解程度,并揭示模型在文化理解方面的优势和不足。
实际应用
CULTURALVQA数据集的实际应用场景包括但不限于以下方面:1)文化教育:CULTURALVQA可用于开发文化教育应用程序,帮助学生和学者更好地理解和欣赏不同文化。2)跨文化沟通:该数据集可以用于训练VLM模型,以增强跨文化沟通和交流能力。3)文化产品推荐:基于CULTURALVQA,可以开发文化相关的产品推荐系统,为用户提供更精准的文化产品和服务。4)文化内容创作:CULTURALVQA可以用于创作更丰富的文化内容,如文化相关的图像、视频和文本等。
衍生相关工作
CULTURALVQA数据集的提出推动了视觉语言模型在文化理解方面的发展,并衍生出一系列相关研究。例如,一些研究使用CULTURALVQA数据集来评估不同VLM模型在文化理解方面的表现,并分析它们的优势和不足。此外,一些研究还基于CULTURALVQA数据集开发了新的文化理解评估指标和方法,以更全面地衡量VLM的文化理解能力。这些研究成果为视觉语言模型在文化理解方面的进一步发展提供了重要参考和启示。
以上内容由遇见数据集搜集并总结生成


