NuScenes-MQA
收藏arXiv2023-12-11 更新2024-06-21 收录
下载链接:
https://github.com/turingmotors/NuScenes-MQA
下载链接
链接失效反馈官方服务:
资源简介:
NuScenes-MQA是由图灵汽车公司创建的一个专注于自动驾驶领域的数据集,包含1,459,933条标注数据,涵盖物体存在、数量、接近度和相对位置等多个方面。该数据集采用Markup-QA技术进行标注,支持同时评估模型的文本生成和视觉问答能力。NuScenes-MQA数据集旨在通过精确的问答和描述能力,推动视觉语言模型在自动驾驶任务中的发展,解决自动驾驶中的复杂场景理解和语言生成问题。
NuScenes-MQA is a dataset focused on the autonomous driving domain, created by Turing Automotive Company. It comprises 1,459,933 annotated data instances, covering multiple aspects including object existence, quantity, proximity, and relative spatial positions. Annotated using the Markup-QA technique, this dataset supports the simultaneous evaluation of both text generation and visual question answering (VQA) capabilities of models. The NuScenes-MQA dataset aims to advance the development of vision-language models for autonomous driving tasks via precise question answering and description capabilities, and to resolve the challenges of complex scene understanding and language generation in autonomous driving scenarios.
提供机构:
图灵汽车公司
创建时间:
2023-12-11
搜集汇总
数据集介绍
构建方式
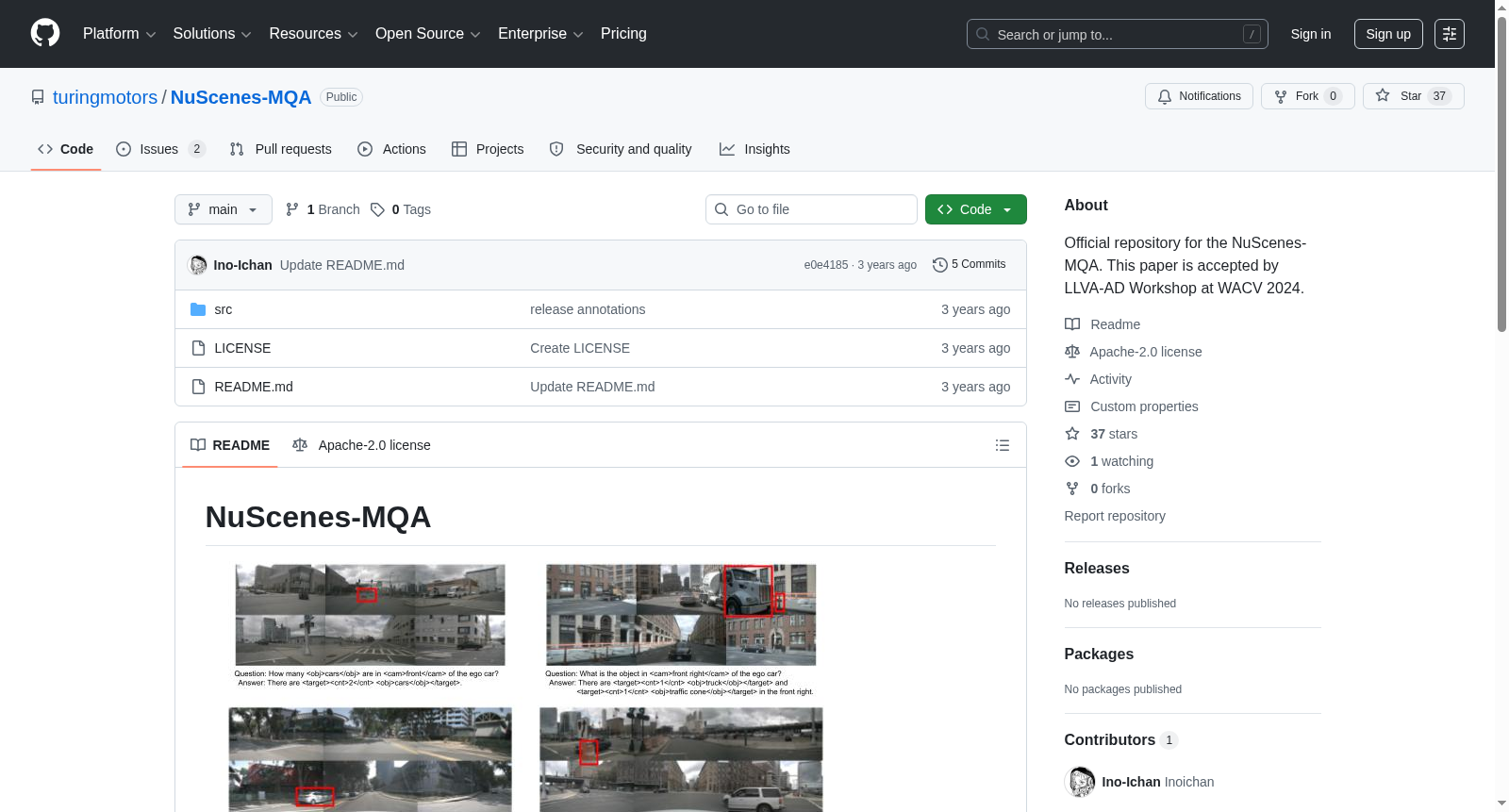
在自动驾驶视觉语言模型快速发展的背景下,NuScenes-MQA数据集采用了一种创新的Markup-QA标注技术进行构建。该数据集以著名的nuScenes自动驾驶数据集为基础,充分利用其丰富的三维物体空间信息标注。构建过程采用规则驱动的方法,通过GPT-4生成多样化的问答模板,并由人工审核筛选,最终形成了涵盖物体存在性、数量统计、相对距离与位置四大核心概念的标注体系。整个数据集包含来自34,149个驾驶场景的1,459,933条标注,每条标注均将结构化问答信息嵌入完整的自然语言句子中,并通过特定标记符号进行封装。
特点
该数据集最显著的特征在于其独特的Markup-QA标注范式,它允许在单一自然语言句子中嵌入多个结构化问答任务。通过使用<target>、<obj>、<cnt>等专用标记,模型既能评估完整的句子生成质量,又能精确提取并验证封装在标记内的特定信息。这种设计突破了传统视觉问答数据集仅关注单词语义匹配的局限,实现了对模型描述能力与精确推理能力的联合评估。数据集内容覆盖自动驾驶场景中关键的感知任务,包括物体检测、方向判断、距离估计和坐标定位,且问答复杂度随句子内嵌入问题数量的增加而梯度上升。
使用方法
使用NuScenes-MQA数据集时,研究者可将其用于训练和评估多模态视觉语言模型。典型流程包括:利用视觉编码器提取多摄像头图像特征,通过适配器模块将视觉特征与语言模型嵌入空间对齐,然后以端到端方式训练模型生成带有Markup-QA结构的自然语言描述。评估阶段需同时采用两类指标:一方面使用BLEU、METEOR等标准文本生成指标评估整体句子流畅度;另一方面通过解析标记内的内容,计算物体类别、数量、距离等具体问答任务的准确率。这种双轨评估机制能够全面衡量模型在自动驾驶场景下的综合语言理解与场景推理能力。
背景与挑战
背景概述
在自动驾驶技术迅猛发展的背景下,视觉语言模型(VLMs)与大型语言模型(LLMs)的融合成为提升系统智能感知与决策能力的关键路径。Turing Inc.的研究团队于近年提出了NuScenes-MQA数据集,其核心研究问题在于解决自动驾驶场景中视觉问答(VQA)任务与自然语言生成能力的协同评估难题。该数据集基于广泛使用的nuScenes多模态驾驶数据集,通过创新的Markup-QA标注技术,将问答对嵌入到完整的自然语言描述中,从而支持模型在对象识别、空间关系理解等方面的综合性能评测。NuScenes-MQA的推出,为自动驾驶领域视觉语言模型的训练与评估提供了重要基准,推动了场景理解与语言生成一体化研究的发展。
当前挑战
NuScenes-MQA数据集旨在应对自动驾驶中视觉问答任务的复杂挑战,其核心问题在于实现模型对驾驶场景的精准识别与自然语言描述的生成。具体挑战包括:在领域问题层面,模型需同时处理对象存在性、数量统计、相对距离与位置等多重查询,并确保答案在语法与语义上的完整性;而多问答嵌套于单一句子的设计,进一步增加了语义解析与信息提取的难度。在构建过程中,数据集面临标注一致性与多样性的平衡问题,规则化方法虽能保证标注效率,却可能限制语言表达的丰富性;此外,空间信息(如坐标与距离)的文本化表示要求模型具备数值与语言的跨模态对齐能力,这对标注设计与模型训练提出了更高要求。
常用场景
经典使用场景
在自动驾驶视觉语言模型的研究中,NuScenes-MQA数据集被广泛用于评估模型在复杂驾驶场景下的视觉问答与自然语言生成能力。该数据集通过Markup-QA标注技术,将问答任务嵌入到完整的自然语言句子中,使得研究者能够同时测试模型对图像内容的精确理解与流畅的文本描述能力。典型应用包括训练多模态模型处理驾驶场景中的对象检测、计数、距离估算及位置描述等任务,为自动驾驶系统的情境感知与决策解释提供关键支持。
解决学术问题
NuScenes-MQA数据集主要解决了自动驾驶领域视觉问答任务中语言生成与场景识别难以协同评估的学术难题。传统VQA数据集通常侧重于单一词语的预测,限制了模型自然语言生成能力的发挥;而该数据集通过创新的标记化标注,使得模型能够在生成连贯句子的同时准确回答嵌入式问题。这不仅促进了视觉语言模型在逻辑推理与描述精度上的平衡,还为多任务学习框架提供了统一评估基准,推动了自动驾驶情境理解与交互系统的发展。
衍生相关工作
NuScenes-MQA的发布催生了一系列基于标记化标注的视觉语言研究,例如扩展至多传感器融合的驾驶数据集构建与跨模态推理模型优化。相关工作如DriveLM和NuScenes-QA在此基础上进一步整合了感知、预测与规划任务,形成端到端的语言驱动自动驾驶框架。同时,该数据集的评估方法启发了如LLaVA、MiniGPT-v2等通用视觉语言模型在领域适配方面的改进,促进了标记化提示技术在视觉定位与复杂问答任务中的创新应用。
以上内容由遇见数据集搜集并总结生成


