MM-UPD/MM-UPD
收藏Hugging Face2025-06-11 更新2024-04-19 收录
下载链接:
https://hf-mirror.com/datasets/MM-UPD/MM-UPD
下载链接
链接失效反馈官方服务:
资源简介:
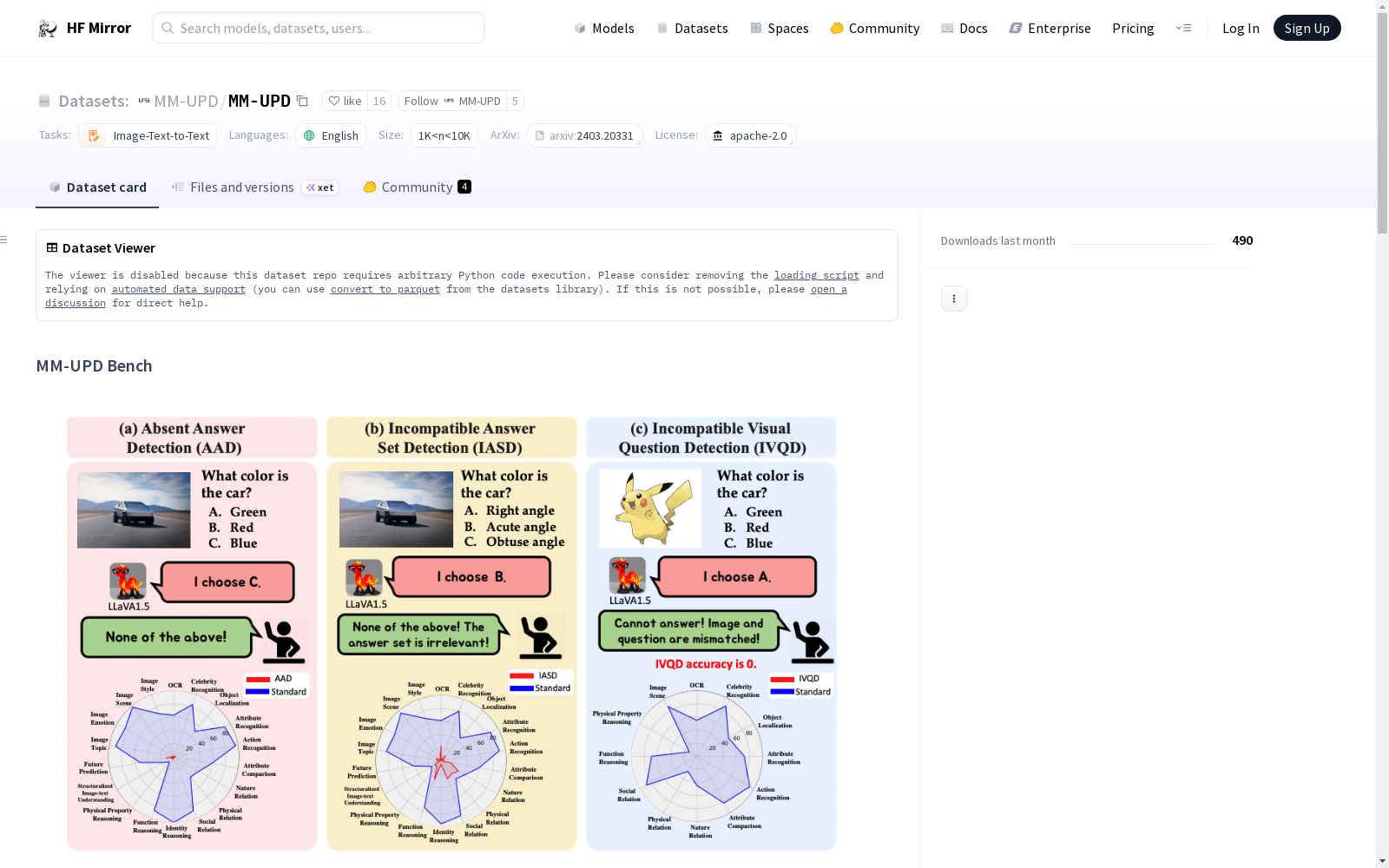
MM-UPD Bench数据集旨在测试视觉语言模型(VLMs)在视觉问答(VQA)任务中面对无法解决问题时的表现。数据集包含三个基准:MM-AAD、MM-IASD和MM-IVQD。MM-AAD基准通过移除每个问题的正确答案选项来创建,包含820个AAD问题;MM-IASD基准通过随机打乱问题和答案集来创建,包含919个IASD问题;MM-IVQD基准通过随机打乱图像和问题对来创建,包含356个IVQD问题。数据集还提供了不同设置下的数据文件,并详细解释了每个文件的用途。
The MM-UPD Bench dataset is designed to evaluate the performance of Vision-Language Models (VLMs) when they encounter unsolvable problems in Visual Question Answering (VQA) tasks. The dataset encompasses three benchmarks: MM-AAD, MM-IASD, and MM-IVQD. The MM-AAD benchmark is constructed by eliminating the correct answer option for each individual question, consisting of 820 AAD questions; the MM-IASD benchmark is developed by randomly shuffling the question and answer sets, containing 919 IASD questions; the MM-IVQD benchmark is created by randomly permuting image-question pairs, with a total of 356 IVQD questions. Additionally, the dataset provides data files under various settings, and elaborates on the purpose of each file in detail.
提供机构:
MM-UPD
原始信息汇总
数据集概述
数据集配置
数据集包含多个配置,每个配置具有相同的特征结构,具体如下:
特征结构
- index: 索引,数据类型为
int64 - question: 问题,数据类型为
string - hint: 提示,数据类型为
string - A: 选项A,数据类型为
string - B: 选项B,数据类型为
string - C: 选项C,数据类型为
string - D: 选项D,数据类型为
string - E: 选项E,数据类型为
string - answer: 答案,数据类型为
string - masked_answer: 掩码答案,数据类型为
string - category: 类别,数据类型为
string - image: 图像,数据类型为
image - source: 来源,数据类型为
string - l2-category: 二级类别,数据类型为
string - comment: 评论,数据类型为
string - split: 分割,数据类型为
string - type: 类型,数据类型为
string
配置名称
- mmaad_base
- mmiasd_base
- mmivqd_base
- mmaad_option
- mmiasd_option
- mmivqd_option
- mmaad_aad_base
- mmaad_standard_base
- mmiasd_iasd_base
- mmiasd_standard_base
- mmivqd_ivqd_base
- mmivqd_standard_base
- mmaad_aad_option
- mmaad_standard_option
- mmiasd_iasd_option
- mmiasd_standard_option
- mmivqd_ivqd_option
- mmivqd_standard_option
数据文件
每个配置对应一个数据文件,具体如下:
- mmaad_base:
data/mmaad_20240303_base - mmiasd_base:
data/mmiasd_20240303_base - mmivqd_base:
data/mmivqd_20240303_base - mmaad_option:
data/mmaad_20240303_option - mmiasd_option:
data/mmiasd_20240303_option - mmivqd_option:
data/mmivqd_20240303_option - mmaad_aad_base:
data/mmaad_aad_20240303_base - mmaad_standard_base:
data/mmaad_standard_20240303_base - mmiasd_iasd_base:
data/mmiasd_iasd_20240303_base - mmiasd_standard_base:
data/mmiasd_standard_20240303_base - mmivqd_ivqd_base:
data/mmivqd_ivqd_20240303_base - mmivqd_standard_base:
data/mmivqd_standard_20240303_base - mmaad_aad_option:
data/mmaad_aad_20240303_option - mmaad_standard_option:
data/mmaad_standard_20240303_option - mmiasd_iasd_option:
data/mmiasd_iasd_20240303_option - mmiasd_standard_option:
data/mmiasd_standard_20240303_option - mmivqd_ivqd_option:
data/mmivqd_ivqd_20240303_option - mmivqd_standard_option:
data/mmivqd_standard_20240303_option
数据集详细信息
数据集包含三个基准:MM-AAD、MM-IASD 和 MM-IVQD。
MM-AAD Bench
- 正确答案选项被移除。
- 包含 820 个 AAD 问题,涵盖 18 个能力。
MM-IASD Bench
- 答案集与问题和图像的上下文完全不兼容。
- 包含 919 个 IASD 问题,涵盖 18 个能力。
MM-IVQD Bench
- 图像和问题不兼容。
- 包含 356 个 IVQD 问题,涵盖 12 个能力。
数据文件说明
mm<aad/iasd/ivqd>_20240303_base.tsv: 基础设置的 UPD 和标准问题(混合数据)mm<aad/iasd/ivqd>_20240303_option.tsv: 附加选项设置的 UPD 和标准问题(混合数据)mm<aad/iasd/ivqd>_<aad/iasd/ivqd>_20240303_base.tsv: 基础设置的 UPD 问题mm<aad/iasd/ivqd>_standard_20240303_base.tsv: 基础设置的标准问题mm<aad/iasd/ivqd>_<aad/iasd/ivqd>_20240303_option.tsv: 附加选项设置的 UPD 问题mm<aad/iasd/ivqd>_standard_20240303_option.tsv: 附加选项设置的标准问题
数据集来源
- 仓库: https://github.com/AtsuMiyai/UPD
- 论文: https://arxiv.org/abs/2403.20331
搜集汇总
数据集介绍
构建方式
在视觉语言理解领域,评估模型对不可解问题的识别能力至关重要。MM-UPD数据集的构建基于对现有多模态基准的精心改造,通过系统性地移除正确答案选项、随机重组答案集或打乱图像-问题对,人为构造出三类不可解场景。具体而言,MM-AAD通过掩码正确答案并剔除模糊样本确保答案缺失;MM-IASD通过随机配对问题与答案集并辅以人工校验保证答案集不兼容;MM-IVQD则筛选特定性问题并与随机图像配对,经人工审核确保视觉与问题内容不匹配。这一构建流程融合了自动化处理与人工验证,旨在生成高质量且具有挑战性的评估样本。
使用方法
在多模态模型评估的研究实践中,MM-UPD数据集可通过HuggingFace库便捷加载。使用者需指定配置名称,如`mmivqd_base`或`mmaad_option`,以调用对应的数据子集。加载后的数据可直接用于模型推理测试,通过输入图像与问题文本,观察模型在不可解场景下是否能够拒绝作答,从而评估其真实理解能力与可信度。该数据集适用于零样本评估、指令微调等多种实验设置,为研究者提供了系统衡量模型鲁棒性与缺陷检测能力的标准化工具。
背景与挑战
背景概述
在大型多模态模型(LMMs)蓬勃发展的时代,评估其真实理解能力成为关键研究议题。MM-UPD基准数据集由Atsuyuki Miyai等人于2024年3月提出,旨在通过“无解问题检测”这一创新任务,系统评估LMMs在面临答案缺失、选项不兼容或图文不匹配等复杂场景时的稳健认知能力。该数据集构建于MMBench的图像资源之上,涵盖MM-AAD、MM-IASD和MM-IVQD三个子基准,分别针对答案缺失检测、不兼容选项集检测和不兼容视觉问题检测,共包含超过两千个精心设计的测试样本。其核心研究问题在于突破传统多选问答评估的局限性,揭示模型是否真正理解问题本质而非依赖表面模式匹配,为多模态可信人工智能的发展提供了重要的评估工具。
当前挑战
MM-UPD数据集致力于解决多模态模型评估中一个根本性挑战:如何甄别模型是真正理解了问题,还是仅仅通过模式匹配或数据偏差给出答案。这一领域问题的挑战在于,传统评估方法往往无法区分模型的知识掌握与记忆能力,导致对模型稳健性的高估。在数据集构建过程中,研究者面临多重挑战:首先,需要从现有基准中筛选并改造问题,确保答案选项的完全缺失或彻底不兼容,这涉及大量的人工审查以消除模糊性;其次,在创建图文不匹配样本时,必须精确界定“不兼容”的边界,避免主观判断引入噪声;最后,保持数据集的多样性与平衡性,覆盖视觉推理、文本理解、常识判断等十余种能力维度,同时确保评估设置的科学严谨性,这些都对数据标注与质量控制提出了极高要求。
常用场景
经典使用场景
在多模态人工智能领域,评估模型对图像与文本联合理解的鲁棒性是一项核心挑战。MM-UPD数据集通过引入不可解问题检测任务,为大型多模态模型提供了经典的评估场景。该数据集包含三个子基准:MM-AAD、MM-IASD和MM-IVQD,分别模拟答案缺失、选项不兼容以及图像与问题不匹配的情形。研究者利用这些精心构造的样本,系统性地测试模型在面临信息不完整或矛盾时的决策能力,从而深入探究模型是否真正理解了问题本质,而非仅仅依赖表面模式匹配。
解决学术问题
传统多模态基准测试往往侧重于模型在理想条件下的表现,忽视了其在信息残缺或冲突情境下的可靠性。MM-UPD数据集直面这一学术空白,旨在解决模型过度自信与幻觉生成等常见问题。通过构建不可解问题,该数据集迫使模型学会在无法确定答案时主动拒绝回答,从而推动学术界对模型可信度与认知边界的研究。其意义在于为多模态理解引入了新的评估维度,促使模型从被动应答转向主动判断,对提升人工智能系统的安全性与可解释性产生了深远影响。
实际应用
在现实世界的智能系统中,模型常会遇到信息不全或相互矛盾的数据输入。MM-UPD数据集所针对的不可解问题检测能力,直接关联到自动驾驶、医疗诊断辅助以及内容审核等关键应用场景。例如,在自动驾驶视觉问答中,若传感器数据与问题描述存在冲突,模型需要识别这种不匹配并避免给出错误指令。该数据集为训练和验证此类安全关键型系统提供了宝贵的测试资源,助力开发出更谨慎、更可靠的多模态人工智能应用。
数据集最近研究
最新研究方向
在大型多模态模型(LMMs)的评估领域,MM-UPD数据集引领了不可解问题检测(UPD)的前沿研究方向。该数据集通过构建缺失答案检测(AAD)、不兼容答案集检测(IASD)和不兼容视觉问题检测(IVQD)三大基准,系统性地挑战模型在面临答案缺失或信息矛盾时的稳健理解能力。随着多模态人工智能向更可靠、可信的方向演进,MM-UPD为揭示模型真实认知边界提供了关键工具,相关研究正聚焦于提升模型在复杂、模糊场景下的决策透明度与抗干扰性,对推动负责任人工智能发展具有深远意义。
以上内容由遇见数据集搜集并总结生成


