PoseDreamer
收藏arXiv2026-03-31 更新2026-04-01 收录
下载链接:
https://prosperolo.github.io/posedreamer
下载链接
链接失效反馈官方服务:
资源简介:
PoseDreamer是由牛津大学团队构建的大规模合成人体数据集,通过扩散模型实现高真实感图像生成与精准3D姿态控制。该数据集包含50万张标注SMPL-X参数的图像,数据源自LAION和AMASS的混合采样,结合硬样本挖掘与多阶段过滤确保多样性。其创新性在于将3D网格参数逆向编码为RGB空间,利用Direct Preference Optimization强化生成控制,解决了传统渲染方法成本高、真实性不足的问题。该数据集专为人体网格恢复任务设计,可提升模型在复杂场景下的姿态估计鲁棒性,填补了真实标注数据与合成数据间的领域鸿沟。
PoseDreamer is a large-scale synthetic human dataset developed by a team from the University of Oxford, which enables high-fidelity image generation and precise 3D pose control via diffusion models. It contains 500,000 images annotated with SMPL-X parameters, sourced from hybrid sampling of LAION and AMASS. Hard sample mining and multi-stage filtering are employed to ensure data diversity. Its innovation lies in inversely encoding 3D mesh parameters into the RGB space, and leveraging Direct Preference Optimization (DPO) to enhance generation control, which addresses the issues of high cost and insufficient realism associated with traditional rendering methods. This dataset is specifically designed for the human mesh recovery task, which can improve the robustness of pose estimation models in complex scenarios, and bridges the domain gap between real annotated data and synthetic data.
提供机构:
牛津大学·视觉几何组; 牛津大学·体育医学与技术研究所; 乌克兰天主教大学
创建时间:
2026-03-31
原始信息汇总
PoseDreamer数据集概述
数据集基本信息
- 数据集名称: PoseDreamer
- 发布年份: 2026
- 论文状态: arXiv预印本
- 相关链接:
- 论文: https://prosperolo.github.io/posedreamer
- 代码: 即将发布
- 数据集: https://prosperolo.github.io/posedreamer
核心目标
PoseDreamer是一个可扩展的流程,旨在通过扩散模型生成具有精确3D姿态控制的光照真实感人体数据集,以解决3D人体网格估计任务中标注数据获取困难的问题。
方法概述
- 核心技术: 结合可控图像生成与直接偏好优化(Direct Preference Optimization)进行控制对齐。
- 关键步骤:
- 基于课程学习的困难样本挖掘。
- 多阶段质量过滤。
- 核心优势: 自然保持3D标注与生成图像之间的对应关系,同时优先处理具有挑战性的样本以最大化数据集效用。
数据集规模与质量
- 样本数量: 超过500,000个高质量合成样本。
- 标注信息: 提供精确的3D网格标注。
- 图像质量指标:
- 相较于基于渲染的数据集,图像质量指标提升76%。
- FID得分为1.72。
- IS得分为9.78。
- 控制对齐增益: 直接偏好优化带来**42%**的OKS误差减少。
性能评估
作为唯一训练数据
在野外基准测试(PVE指标,越低越好)中,PoseDreamer作为唯一训练数据,性能全面超越BEDLAM数据集:
- UBody数据集: 97.6 (PoseDreamer) vs 146.3 (BEDLAM)
- MPII数据集: 122.3 (PoseDreamer) vs 141.1 (BEDLAM)
- MSCOCO数据集: 129.4 (PoseDreamer) vs 163.7 (BEDLAM)
与现有合成数据的互补性
- 仅结合PoseDreamer和BEDLAM两个数据集进行训练,其性能即可匹配或超越依赖五个及以上真实与合成数据集的基线方法。
- 该结论在多种模型规模(ViT-S和ViT-L骨干网络)和数据集大小(高达150万个实例)下均成立。
领域特定生成
在MPII Yoga基准测试中,用3万个瑜伽特定样本替换随机图像,可将PVE从199.6降低至171.1。
引用格式
bibtex @article{prospero2026posedreamer, title = {PoseDreamer: Scalable Photorealistic Human Data Generation with Diffusion Models}, author = {Prospero, Lorenza and Kupyn, Orest and Viniavskyi, Ostap and Henriques, Joao F. and Rupprecht, Christian}, journal = {arXiv preprint}, year = {2026} }
搜集汇总
数据集介绍
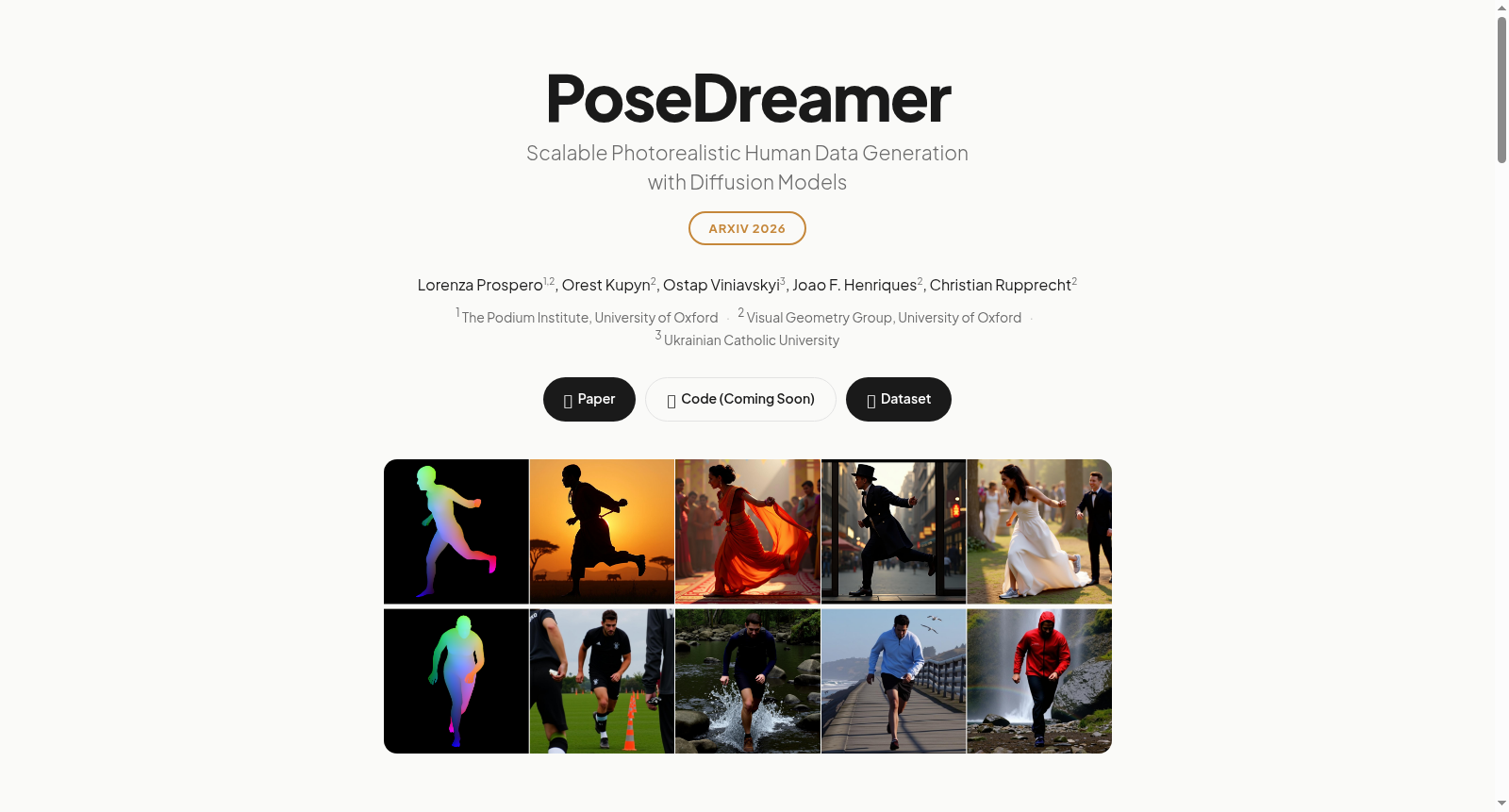
构建方式
在计算机视觉领域,三维人体网格恢复任务长期受限于高质量标注数据的稀缺性。PoseDreamer数据集通过创新的生成式流水线应对这一挑战,其构建过程始于多样化的SMPL-X人体参数与文本描述生成,这些参数源自LAION图像库的真实场景与AMASS运动捕捉数据库的动态姿态,确保了数据在场景真实性与姿态复杂性上的互补。随后,采用基于课程学习的困难样本挖掘策略,利用下游网格恢复模型的反馈识别具有挑战性的姿态配置,优先生成此类样本以最大化数据效用。最后,通过直接偏好优化对齐的空间控制扩散模型进行图像生成,并结合多阶段质量过滤机制,剔除拥挤场景、姿态错位及头部姿态不一致的样本,从而保障了生成图像与三维标注间的高精度对应关系。
使用方法
该数据集专为三维人体网格恢复等监督学习任务而设计,可直接用于训练如SMPLer-X等参数化人体模型回归器。研究人员可将数据集的RGB图像作为输入,其对应的SMPL-X参数作为地面真值,通过标准的监督学习框架优化模型。数据集支持与现有合成或真实数据集进行混合训练,实验表明其与BEDLAM等渲染数据集的结合能产生性能增益,展现出互补特性。此外,数据集的生成流水线具备领域定制化的灵活性,可通过替换输入姿态源(如特定运动数据集)来生成面向特定应用场景(如瑜伽动作分析)的专项数据,从而提升模型在目标领域的泛化能力。
背景与挑战
背景概述
在计算机视觉领域,三维人体网格恢复任务长期以来受限于高质量标注数据的稀缺性。传统真实数据集如Human3.6M和3DPW虽提供精确的三维标注,但规模有限且场景多样性不足;而基于渲染引擎的合成数据集如BEDLAM和AGORA虽能扩展规模,却常因渲染质量与真实感之间的差距导致域适应问题。为突破这一瓶颈,牛津大学视觉几何组的研究团队于2026年提出了PoseDreamer数据集,其核心创新在于利用扩散模型生成兼具高真实感与精确三维标注的大规模人体图像。该数据集通过可控生成、困难样本挖掘与多级过滤等技术,构建了超过50万样本的合成数据,在图像质量指标上较传统渲染数据集提升76%,为三维人体姿态估计与网格重建任务提供了新的数据范式。
当前挑战
PoseDreamer致力于解决三维人体网格恢复领域的两大核心挑战:一是传统数据集中三维标注与二维图像间的一致性难题,二是合成数据生成过程中真实感与可控性的平衡问题。在构建过程中,研究团队面临多重技术障碍:首先,扩散模型生成图像与输入的三维网格参数间缺乏固有对应关系,需通过改进的网格到RGB编码方案与直接偏好优化技术实现精确的空间控制对齐;其次,为提升数据效用,必须设计课程式困难样本挖掘机制,避免生成冗余的简单样本;此外,生成图像可能包含人群拥挤、严重遮挡或头部姿态不一致等异常情况,需建立多级质量过滤管道以确保标注可靠性。这些挑战的克服使得PoseDreamer在保持生成效率的同时,实现了合成数据与真实场景间域差距的显著缩小。
常用场景
经典使用场景
在三维人体网格恢复领域,获取高质量标注数据一直面临深度模糊性和单目图像三维几何标注困难的挑战。PoseDreamer通过扩散模型生成大规模合成数据集,为这一领域提供了经典解决方案。该数据集最经典的使用场景是作为训练数据,用于提升单目图像中三维人体姿态与形状估计模型的性能。研究者利用其50万张高真实感图像及对应的精确SMPL-X网格标注,能够有效训练监督模型,尤其在复杂姿态、多样服装和背景场景下展现出卓越的泛化能力,显著缩小了合成数据与真实应用之间的域差距。
解决学术问题
PoseDreamer主要解决了三维人体感知研究中标注数据稀缺且成本高昂的学术难题。传统真实数据集受限于标注精度与规模,而基于渲染的合成数据则存在真实感不足与多样性有限的缺陷。该数据集通过可控扩散生成与对齐优化,确保了图像与三维标注间的高度一致性,从而为模型提供了可靠且大规模的训练样本。其意义在于突破了数据获取的瓶颈,使得研究者能够以较低成本获得兼具真实感与精确几何监督的数据,推动了三维人体重建、姿态估计等方向的技术进步,并为生成式模型在数据合成领域的应用开辟了新路径。
实际应用
在实际应用层面,PoseDreamer生成的高质量合成数据已广泛应用于增强现实、虚拟试衣、运动分析和人机交互等领域。例如,在虚拟角色创建中,该数据集能够提供多样化且真实的人体模型,用于生成逼真的数字人;在体育科学和医疗康复中,其丰富的姿态变化有助于训练模型精准分析人体动作。此外,该数据集的生成管道支持针对特定领域(如瑜伽姿态)定制化数据生成,从而提升下游任务在特定场景下的性能,为实际部署提供了高度灵活且经济高效的数据支持。
数据集最近研究
最新研究方向
在三维人体网格估计领域,数据标注的深度模糊性与高昂成本长期制约着模型发展。PoseDreamer通过扩散模型构建了规模化、高真实感的合成数据生成管道,标志着该领域前沿研究正从传统渲染引擎向生成式人工智能范式迁移。其核心突破在于实现了可控图像生成与三维标注的精确对齐,结合基于课程学习的困难样本挖掘与多阶段质量过滤,有效弥合了合成数据与真实场景间的域差距。这一进展不仅显著提升了人体姿态估计模型在复杂野外环境下的鲁棒性,更通过超过50万高质量样本的生成,验证了生成式数据作为传统标注与渲染管道的可行替代方案。相关研究已展示出与真实数据集及传统合成数据集的互补性,为低成本、高可扩展的三维人体感知研究开辟了新路径,并在运动分析、医疗健康等应用场景中展现出广泛潜力。
相关研究论文
- 1PoseDreamer: Scalable and Photorealistic Human Data Generation Pipeline with Diffusion Models牛津大学·视觉几何组; 牛津大学·体育医学与技术研究所; 乌克兰天主教大学 · 2026年
以上内容由遇见数据集搜集并总结生成


