ghananlpcommunity/pristine-twi-english-parallel-sentences
收藏Hugging Face2026-05-08 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/ghananlpcommunity/pristine-twi-english-parallel-sentences
下载链接
链接失效反馈官方服务:
资源简介:
Pristine Twi–English Parallel Sentences Dataset是一个大规模的、句子级别的、去重的Twi ↔ 英语平行数据集,专门用于训练最先进的机器翻译模型。该数据集来源于Ghana NLP Community的原始数据集,并经过严格的句子分割、对齐过滤、标准化、全局去重和数据分割等处理步骤。数据集的结构包括Twi和英语的句子对,用于机器翻译、跨语言对齐和大型语言模型预训练等任务。数据集的局限性包括翻译的合成来源、领域限制和方言代表性不足等问题。
The Pristine Twi–English Parallel Sentences Dataset is a massive, sentence-level, deduplicated Twi ↔ English parallel dataset optimized specifically for training State-of-the-Art (SOTA) Machine Translation models. This dataset is derived from the original dataset by the Ghana NLP Community and has been meticulously processed through sentence splitting, strict alignment filtering, standardization, global deduplication, and data splitting. The dataset structure includes Twi and English sentence pairs intended for machine translation, cross-lingual alignment, and large language model pre-training. Limitations include the synthetic origin of translations, domain constraints, and under-representation of dialectal variations.
提供机构:
ghananlpcommunity
搜集汇总
数据集介绍
构建方式
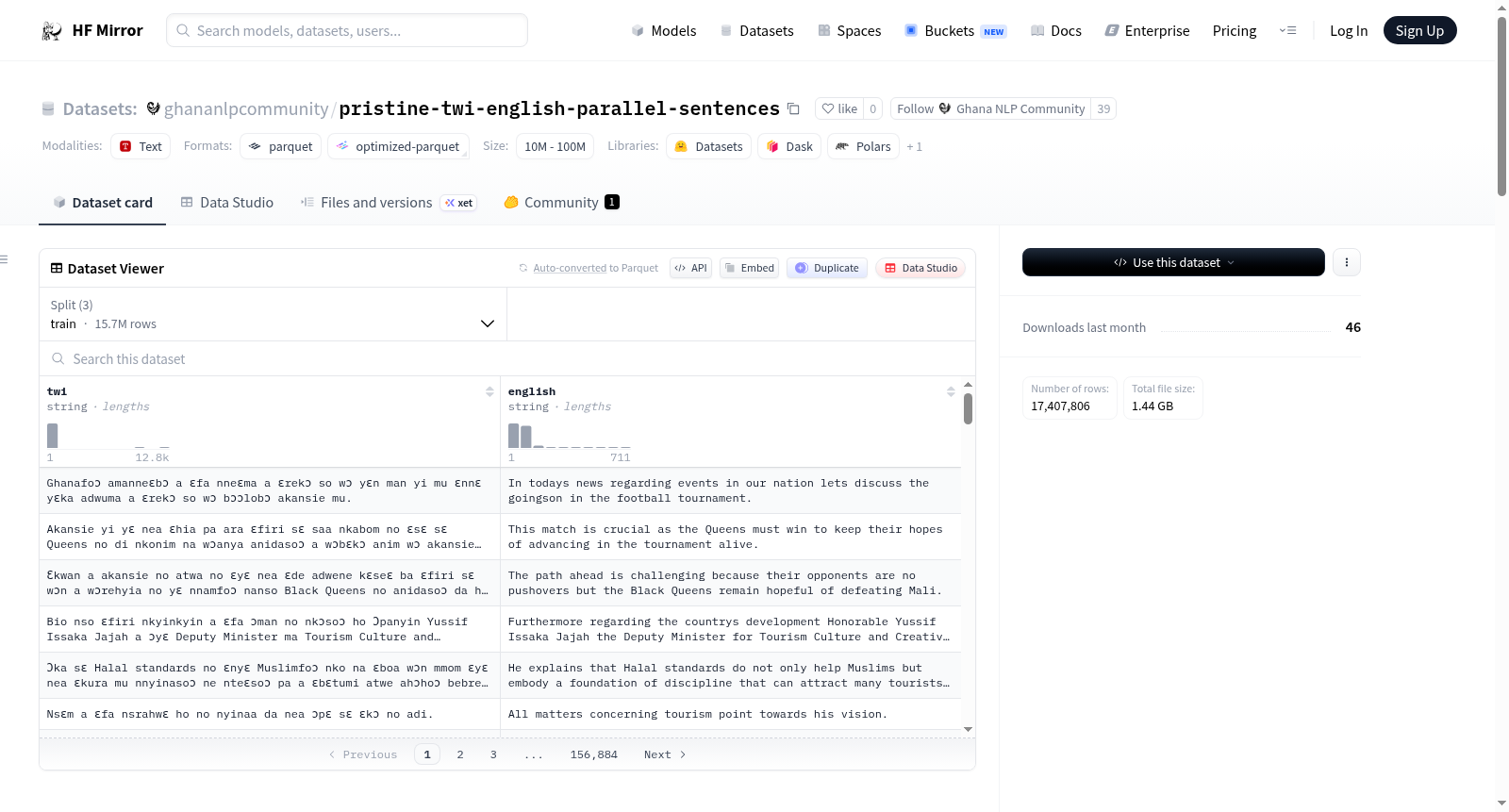
该数据集源自加纳NLP社区的原生Twi-英语平行语料库,经精细处理而成。构建流程首先生成严格对齐的句子对:通过健壮的正则表达式对Twi与英语文本进行句子分割,并仅保留双方句子数量完全一致的行,以剔除因摘要或误译导致的不匹配数据。随后进行标准化处理,去除冗余空白,确保每对句子呈现洁净的1对1平行格式。最后实施全局去重,基于哈希值移除所有重复的句子对,避免数据泄露并提升训练效率。经以上步骤处理后,数据被随机划分,其中90%用于训练,5%用于验证,5%用于测试。
特点
该数据集的核心特点在于其大规模、句子级且高度去重的结构。包含超过1568万条训练样本,以及各约86万条验证与测试样本,为机器翻译模型提供了丰沛的训练资源。每条数据由精准对齐的Twi句子与对应的英语流畅译文构成,无方向列,支持双向翻译训练。数据集源自新闻主题为主的多体裁篇章,涵盖独白、叙事、对话等多种风格,虽未经过逐句人工核验,但通过严格的筛选流程保障了高质量的对齐与纯净度。
使用方法
数据集可通过Hugging Face的datasets库便捷加载:使用load_dataset("ghananlpcommunity/pristine-twi-english-parallel-sentences")命令即可获取。访问示例时,如ds["train"][0]将返回包含'twi'与'english'字段的字典。该数据集主要面向机器翻译模型的训练与评估,亦适用于跨语言嵌入与句子表征学习,以及为大型语言模型提供高质量的平行监督数据。为支持双向翻译,建议在数据加载阶段动态交换两列。
背景与挑战
背景概述
在神经机器翻译迅猛发展的时代背景下,低资源语言对的双语语料库稀缺成为制约模型性能的关键瓶颈。由加纳NLP社区的Mich-Seth Owusu主导构建的pristine-twi-english-parallel-sentences数据集于2024年发布,旨在为契维语(Twi)与英语之间的机器翻译和跨语言迁移学习提供大规模、高质量的平行句子对。该数据集源于社区此前发布的语篇级平行语料,经过严格的句子切分、对齐过滤与全局去重后,形成了约1568万条训练样本、85.9万条验证样本和86.0万条测试样本,极大提升了数据单元的一致性与训练效率,为低资源语言神经翻译的突破奠定了坚实的数据基础。
当前挑战
该数据集核心致力于缓解契维语与英语机器翻译领域中平行语料严重匮乏的困境,推动低资源语言翻译模型性能的跃升。然而,构建过程面临多重挑战:首先,原始数据为语篇级段落,需设计鲁棒的正则启发式规则在区分句子边界的同时避免常见缩写与引用造成的误切分,确保双语句子数量的严格一致。其次,双方句子数不匹配的语料需完全舍弃以防错误对齐,这一严苛过滤策略虽提升了数据纯度,却大幅增加了资源浪费。此外,源文本的英语翻译由大语言模型(Gemini API)自动生成,未经母语者逐句校验,其语义保真度与地道性存疑。最后,数据内容高度偏向加纳新闻领域,可能难以全面覆盖口语化或特定方言(如阿散蒂契维语、阿夸佩姆语)的表达,潜藏领域与方言偏差风险。
常用场景
经典使用场景
在机器翻译研究领域,该数据集被广泛用于训练和评估特威语与英语之间的双向翻译模型。其句级对齐、全局去重的特性为构建高性能神经机器翻译系统提供了理想的数据基础。研究者通常利用其训练数据微调预训练序列到序列模型,并通过验证集和测试集进行翻译质量的定量评估。该数据集也常作为跨语言对中低资源语言翻译任务的标准基准,用于对比不同翻译架构和训练策略的效果。
解决学术问题
该数据集解决了低资源语言对特威语与英语之间大规模平行语料稀缺的核心学术问题,填补了非洲语言机器翻译研究的重要空白。通过严格的句子切分和对齐过滤,有效避免了段落级翻译中的错位噪声,为训练精确的句级翻译模型提供了高质量监督信号。全局去重机制消除了数据泄漏风险,使得模型评估结果更加可靠。这一工作显著推动了低资源场景下神经机器翻译的进展,为探索数据预处理策略对翻译质量的影响提供了实证基础。
衍生相关工作
围绕该数据集衍生了一系列重要工作,包括基于多头注意力机制的上下游网络改进(如集成融合策略的Transformer模型)、跨语言句子嵌入的对比学习研究(如利用该数据微调多语言Sentence-BERT),以及针对低资源语言的预训练语言模型专项优化(如结合Twi语料扩展RoBERTa的词表)。部分工作进一步探索了数据增强技术,如反向翻译和噪声注入,以提升模型的鲁棒性。这些研究共同构成了西非语言处理方向的一个活跃研究集群。
以上内容由遇见数据集搜集并总结生成


