x_dataset_57303
收藏Hugging Face2025-01-30 更新2025-02-10 收录
下载链接:
https://huggingface.co/datasets/icedwind/x_dataset_57303
下载链接
链接失效反馈官方服务:
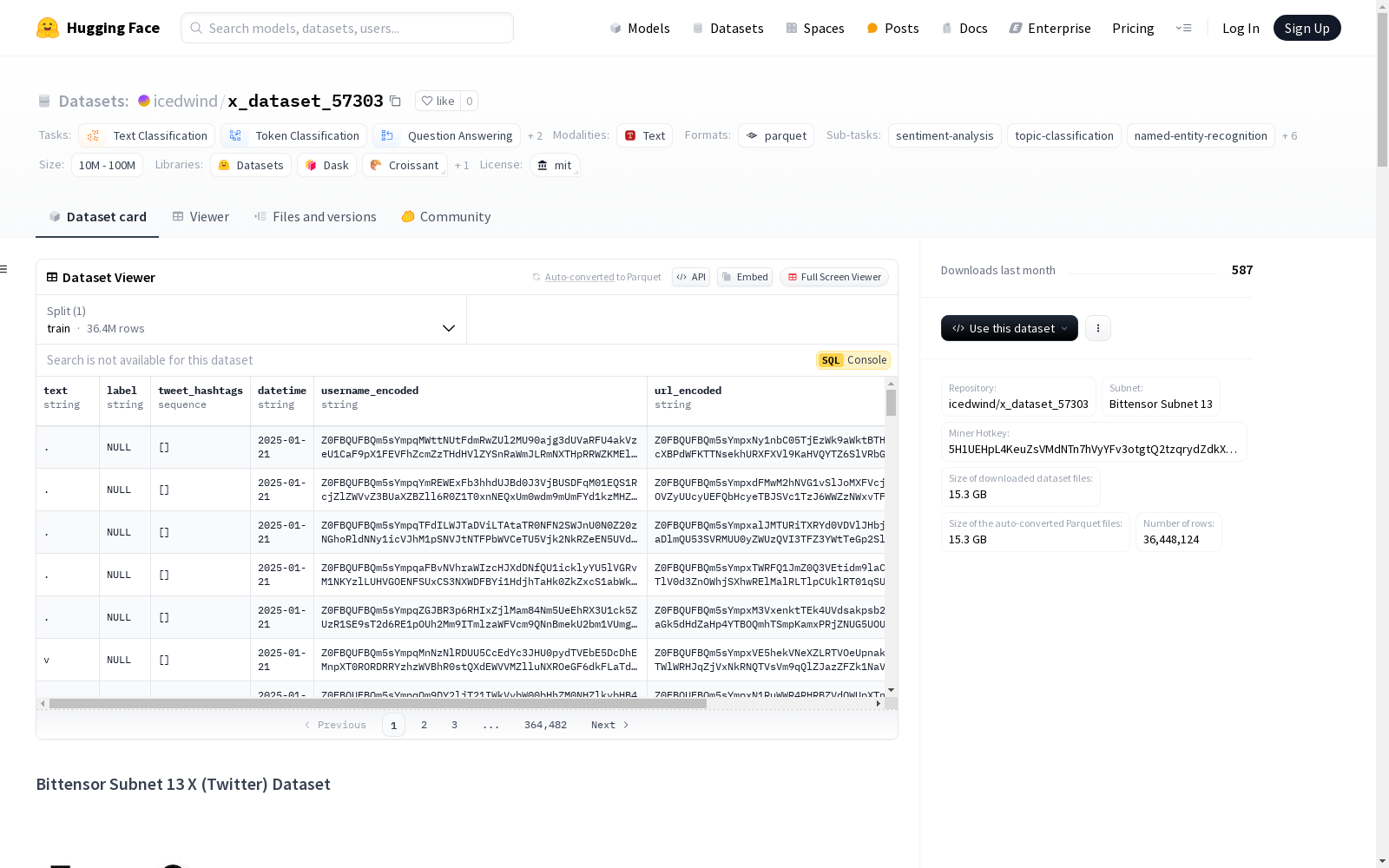
资源简介:
该数据集是Bittensor Subnet 13去中心化网络的一部分,包含来自X(前Twitter)的预处理数据。数据由网络矿工持续更新,提供实时的推文流,适用于各种分析和机器学习任务。数据集支持多种任务,如情感分析、趋势检测、内容分析和用户行为建模。数据集主要包含英文数据,但也可能包含多语言内容。每个实例代表一条推文,包含文本、标签、推文标签、日期时间、编码的用户名和编码的URL等字段。数据集没有固定的分割,用户需要根据需求自行分割。数据集的创建遵循X(Twitter)的服务条款和API使用指南,所有用户名和URL都经过编码以保护用户隐私。数据集可能存在偏见和噪声,用户在使用时应注意这些限制。
创建时间:
2025-01-27
原始信息汇总
Bittensor Subnet 13 X (Twitter) Dataset
数据集描述
- 存储库: icedwind/x_dataset_57303
- 子网: Bittensor Subnet 13
- 数据摘要: 该数据集是Bittensor Subnet 13分布式网络的一部分,包含来自X(前Twitter)的预处理数据。数据由网络矿工持续更新,提供实时推文流,用于各种分析和机器学习任务。
支持的任务
- 文本分类
- 令牌分类
- 问题回答
- 摘要
- 文本生成
语言
主要语言:数据集主要是英文,但由于去中心化的创建方式,可能是多语言的。
数据结构
数据实例
每个实例代表一条推文,包含以下字段:
text(字符串): 推文的主要内容。label(字符串): 推文的情感或主题类别。tweet_hashtags(列表): 推文中使用的标签列表。如果没有标签,可能为空。datetime(字符串): 推文发布的日期。username_encoded(字符串): 编码后的用户名,以保护用户隐私。url_encoded(字符串): 推文中包含的任何URL的编码版本。如果没有URL,可能为空。
数据拆分
该数据集持续更新,没有固定的拆分。用户应根据需求和数据的时间戳创建自己的拆分。
数据创建
来源数据
数据从X(Twitter)上的公共推文中收集,遵守平台的条款服务和API使用指南。
个人和敏感信息
所有用户名和URL都经过编码,以保护用户隐私。数据集不故意包含个人或敏感信息。
使用数据的考虑
社会影响和偏见
用户应注意X(Twitter)数据中潜在的偏见,包括人口统计和内容偏见。此数据集反映了X上表达的内容和观点,不应被视为代表普通人群的样本。
局限性
- 数据质量可能因去中心化收集和预处理而有所不同。
- 数据集可能包含社交媒体平台典型的噪声、垃圾邮件或无关内容。
- 由于实时收集方法,可能存在时间偏见。
- 数据集仅限于公共推文,不包括私人账户或直接消息。
- 并非所有推文都包含标签或URL。
许可信息
数据集根据MIT许可证发布。使用此数据集还受X使用条款的约束。
引用信息
@misc{icedwind2025datauniversex_dataset_57303, title={The Data Universe Datasets: The finest collection of social media data the web has to offer}, author={icedwind}, year={2025}, url={https://huggingface.co/datasets/icedwind/x_dataset_57303}, }
数据统计
- 总实例数: 36448119
- 日期范围: 2025-01-21至2025-02-05
- 最后更新: 2025-02-10
数据分布
- 带标签的推文: 50.84%
- 不带标签的推文: 49.16%
前10大标签
| 排名 | 主题 | 总计数 | 百分比 |
|---|---|---|---|
| 1 | NULL | 17916295 | 49.16% |
| 2 | #riyadh | 303927 | 0.83% |
| 3 | #zelena | 239391 | 0.66% |
| 4 | #tiktok | 179859 | 0.49% |
| 5 | #bbb25 | 106340 | 0.29% |
| 6 | #ad | 104677 | 0.29% |
| 7 | #jhope_at_galadespiècesjaunes | 88765 | 0.24% |
| 8 | #trump | 57357 | 0.16% |
| 9 | #bbmzansi | 53856 | 0.15% |
| 10 | #pr | 52013 | 0.14% |
搜集汇总
数据集介绍
构建方式
x_dataset_57303数据集构建于Bittensor Subnet 13去中心化网络之上,其数据源来自于X(原Twitter)平台。数据通过平台矿工持续更新,确保提供实时tweet流以供多样化分析与机器学习任务之需。数据集的构建严格遵循X平台的服务条款与API使用指南,确保数据的合规性与时效性。
使用方法
使用该数据集时,用户需自行根据需求与数据时间戳创建数据划分。数据集提供丰富的数据字段,包括推文内容、标签、话题标签、发布时间等,可供研究者进行情感分析、趋势探测、内容分析、用户行为建模等多种研究。用户在使用时需注意数据可能存在的质量波动、噪音、垃圾信息等社交媒体平台常见问题,并对潜在的社会影响和偏见保持警觉。
背景与挑战
背景概述
x_dataset_57303数据集,作为Bittensor Subnet 13分布式网络的一部分,包含了来自X(前Twitter)的预处理数据。该数据集自2025年起由网络矿工持续更新,为用户提供实时推文流,以支持各种分析和机器学习任务。该数据集的创建旨在捕捉并分析社交媒体动态,其多语言特性使其在文本分类、命名实体识别、语言模型训练等多种任务中具有重要研究价值。数据集由icedwind团队维护,并在学术研究中得到了广泛的引用。
当前挑战
在构建过程中,该数据集面临的挑战包括确保数据质量、处理噪声和垃圾信息、以及处理社交媒体平台特有的时间偏差。此外,数据集的实时更新性质导致缺乏固定的数据划分,用户需根据需求和时间戳自行创建数据划分。在使用数据时,还需注意潜在的社交媒体数据偏差,以及确保遵守X平台的使用条款和API指南。
常用场景
经典使用场景
在自然语言处理领域,x_dataset_57303因其多语言特性及涵盖的多样化任务类别,已成为学术研究和应用开发的重要资源。该数据集支持文本分类、命名实体识别、情感分析等多种任务,其中最经典的使用场景是进行情感分析,研究人员可通过该数据集对推文进行情绪判断,以了解公众对特定话题或事件的情感倾向。
解决学术问题
x_dataset_57303解决了情感分析、趋势检测和内容分析中的数据不充分和不准确的问题。它为学术研究者提供了一个大规模、实时更新的数据源,有助于提高算法的泛化能力和准确度,从而推动社交网络分析领域的研究进展,对于理解用户行为、分析社会事件传播具有重大意义。
实际应用
在实际应用中,x_dataset_57303被广泛用于品牌监测、市场趋势分析和危机管理。企业和组织可以利用该数据集分析公众情绪,制定相应的市场策略和公关措施,同时,它也为政府和社会科学研究者提供了洞察社会动态和公众舆论的工具。
数据集最近研究
最新研究方向
在自然语言处理领域,x_dataset_57303数据集以其丰富的多语言特性和多样化的任务类别,如文本分类、命名实体识别、情感分析等,正成为研究的热点。该数据集不断更新,为实时趋势检测、用户行为模式分析等研究方向提供了强有力的数据支撑。特别是,近年来,研究者利用该数据集在情绪识别与话题分类方面取得了显著进展,对于理解社交媒体动态、把握公共舆论走向具有深远影响。
以上内容由遇见数据集搜集并总结生成


