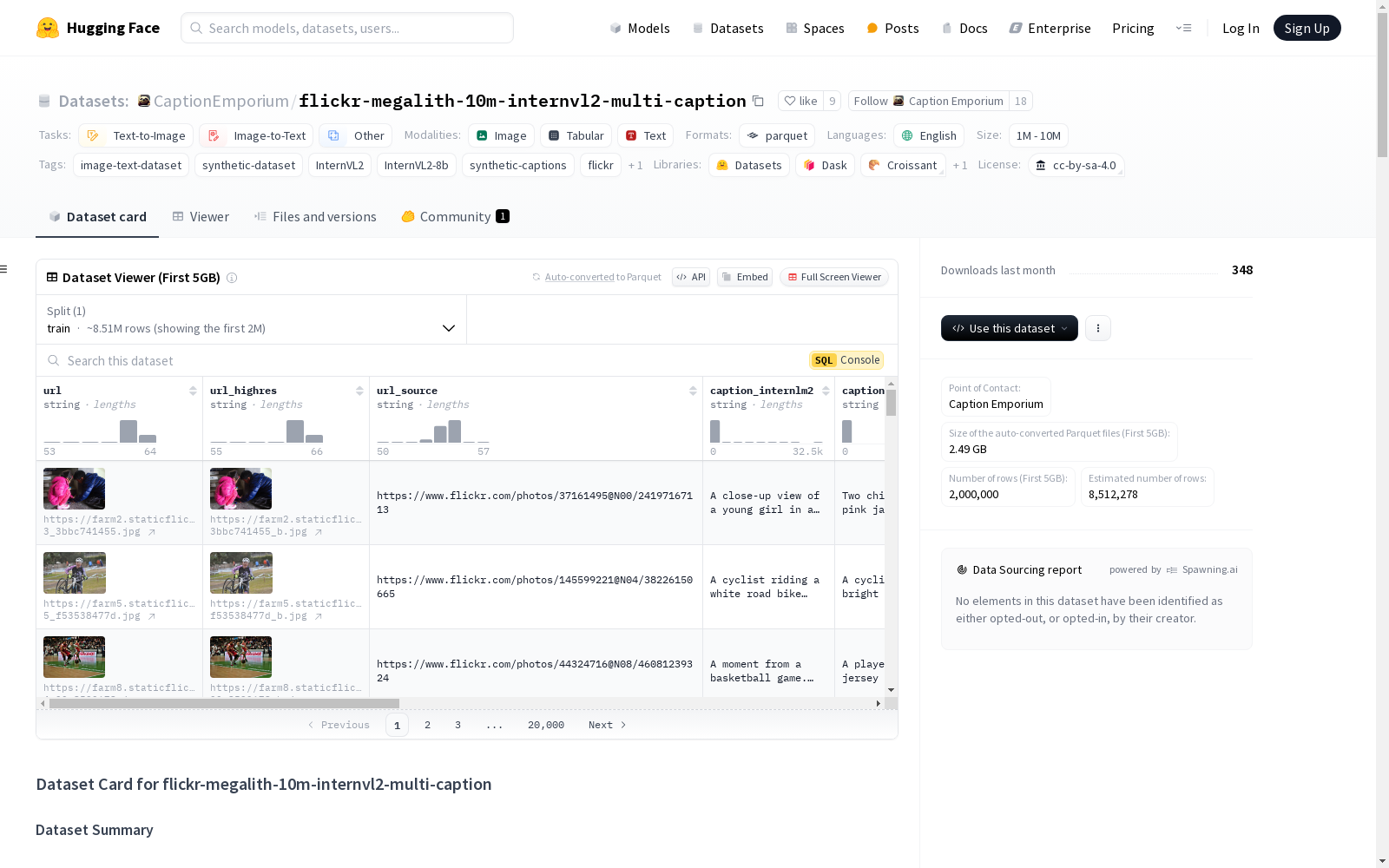
flickr-megalith-10m-internvl2-multi-caption
收藏数据集卡片 for flickr-megalith-10m-internvl2-multi-caption
数据集描述
- 联系人: Caption Emporium
数据集概述
该数据集包含约5730万条合成描述,用于madebyollin/megalith-10m中的图像。
包含以下描述:
- InternVL2 8B长描述(由CaptionEmporium生成)
- InternVL2 8B短描述(由CaptionEmporium生成)
- Florence2长描述(由aipicasso生成)
- Florence2短描述(由CaptionEmporium生成)
- ShareCaptioner长描述(由drawthingsai生成)
- ShareCaptioner短描述(由CaptionEmporium生成)
描述由OpenGVLab/InternVL2-8B生成。短描述均由meta-llama/Meta-Llama-3.1-8B-Instruct生成。图像的高分辨率版本的高度和宽度信息已根据drawthingsai的数据集填充。
语言
文本为英语,但偶尔会转录图像中的其他语言文本。
预期用途
用于训练文本到图像模型和其他机器学习任务。
数据分割
| 数据集名称 | 训练集大小 |
|---|---|
| flickr-megalith-10m-internvl2-multi-caption | 9549801 |
数据集创建
数据集生成
使用以下提示生成描述:
py PROMPT = """ 请为这张图片制作一个详细的描述。如果你看到文本或物体,请确保详细描述它们以及前景和背景的其他方面。
只输出你在图像中看到的内容,不要添加修饰或更深层次的解释,同时对可见的事物做出自信的断言。
例如,而不是:
在海洋中潜水的海星的特写视图。海星的臂上有许多微小的管足可见,形成了一个有纹理和复杂的图案。它的颜色似乎是浅棕色和米色的混合,管足增加了一些白色。背景是暗的,暗示着海洋的深度,它似乎是一个自然栖息地而不是水族馆设置。焦点锐利地集中在海星上,捕捉其解剖结构的细节,而周围环境略微失焦,突出了生物。图像散发出一种宁静和异国情调的感觉,突出了海洋生物的美丽和复杂性。
写:
在海洋中潜水的海星的特写视图。海星的臂上有许多微小的管足可见,形成了一个有纹理和复杂的图案。它的颜色是浅棕色和米色的混合,管足增加了一些白色。背景是暗的,暗示着海洋的深度,它位于自然环境而不是水族馆设置。焦点锐利地集中在海星上,捕捉其解剖结构的细节,而周围环境略微失焦,突出了生物。
现在开始描述,只写描述: """
生成描述后,根据anime-caption-danbooru-2021-sfw-5m-hq的要求去除了前缀。与其他VLM相比,InternVL2仅产生了少量(0.1%)包含重复序列的损坏描述。这些描述使用meta-llama/Meta-Llama-3.1-8B-Instruct手动修复。
同样,Florence2(0.01%)和ShareCaptioner(2.8%)描述中也有重复幻觉的坏描述。这些描述以相同的方式进行了修正。
短描述是从这些描述池中使用meta-llama/Meta-Llama-3.1-8B-Instruct和以下提示生成的:
py prompt_1 = lambda img_prompt: f""" 请将以下图像描述简化为一个句子。去除任何冗余的行或描述,并使其长度不超过30个单词。
{img_prompt}
请只写描述,不写其他文本。 """
数据实例
一个数据行的示例:
py {caption_florence2: 两个年轻的孩子,一个男孩和一个女孩,蹲在楼梯前的一块地上。女孩穿着带有白色圆点的粉色夹克和粉色鞋子,手里拿着一支蓝色蜡笔。男孩也穿着蓝色夹克,跪在她旁边。他们都低头看着地面,似乎在参与一个游戏或活动。楼梯左侧有一个写着“球”、“写”和“苹果”的标志。背景是一堵混凝土墙。, caption_florence2_short: 两个孩子,一个男孩和一个女孩,蹲在楼梯前的一块地上,楼梯上有一个写着“球”、“写”和“苹果”的标志。, caption_internlm2: 一个穿着亮粉色冬装的年轻女孩的特写视图,蹲在石头地板上。她手里拿着一个蓝色物体,可能是笔或小玩具。在她右边,一个穿着蓝色冬装的年轻男孩蹲下,面对着她,似乎在与她互动或帮助她拿物体。两个孩子都有深色的头发。背景包括一个带有手扶梯的楼梯,其中一个手扶梯上写着“球”,另一个部分被遮挡,但似乎写着“rite”。男孩右边有一堆衣服或毛巾,整体设置似乎在一个公共区域,有石头地板和墙壁。, caption_internlm2_short: 两个孩子,一个穿着粉色夹克的女孩和一个穿着蓝色夹克的男孩,在一个公共区域的石头地板上互动。, caption_sharecap: 有两个孩子沉浸在瓷砖地板上的游戏中。左边的孩子穿着粉色外套和圆点裤,手里拿着一个蓝色玩具。右边的孩子穿着蓝色外套和灰色裤子,伸手去拿同一个玩具。他们位于一个楼梯前,楼梯上有一个写着“苹果”的标志。场景捕捉了一个无辜玩耍和探索的时刻。, caption_sharecap_short: 两个孩子,一个穿着粉色,一个穿着蓝色,在瓷砖地板上争夺一个玩具,楼梯前有一个写着“苹果”的标志。, exif: {"Image Artist": "LEAF_Yeh", "Image ExifOffset": "48"}, height: 683, url: https://farm2.staticflickr.com/1598/24197167113_3bbc741455.jpg, url_highres: https://farm2.staticflickr.com/1598/24197167113_3bbc741455_b.jpg, url_source: https://www.flickr.com/photos/37161495@N00/24197167113, width: 1024}
偏见讨论
该数据集偏向于Flickr用户上传的摄影内容。
已知限制
- 描述未经手动验证,可能存在错误。
- 这些不是Flickr上图像的最高分辨率版本,需要直接查询Flickr API以获取这些链接。如果将来有人查找它们,请随时在问题中链接,我将更新数据集。
- 某些行可能缺少某些来源的描述,因为下载的所有图像集合并不完全重叠。在这些情况下,描述只是空字符串。
附加信息
数据集下载
该数据集由drawthingsai上传,但缺少一些包含在InternVL2和Florence2描述中的行。您可能希望使用img2dataset手动下载。
数据集策展人
- Caption Emporium
- madebyollin(原始数据集)
- aipicasso(Florence2描述)
- drawthingsai(Sharecaptioner描述)
特别感谢
SilentAntagonist提供了数据集和一些必要的计算资源。
许可信息
该数据集在Creative Commons ShareAlike (CC BY-SA 4.0)下可用。
引用信息
@misc{flickr-megalith-10m-internvl2-multi-caption, author = { Caption Emporium }, title = {flickr-megalith-10m-internvl2-multi-caption}, year = {2024}, publisher = {Huggingface}, journal = {Huggingface repository}, howpublished = {url{https://huggingface.co/datasets/CaptionEmporium/flickr-megalith-10m-internvl2-multi-caption}}, }